moo
Welcome to the moo documentation. moo is a small, self-contained AI agent written in C — plus the foundation libraries it rides on. It ships as a terminal app (moo) that talks to any OpenAI-compatible endpoint (Kimi, GLM, DeepSeek, OpenAI itself, …); an Anthropic-compatible provider is on the roadmap. Runs on macOS and Linux; Windows is on the roadmap but not a near-term priority.
- Designed and reviewed by @mivinci
- Coded by CodeBuddy (VSCode plugin) with claude-opus-4.7 and GLM-5.1
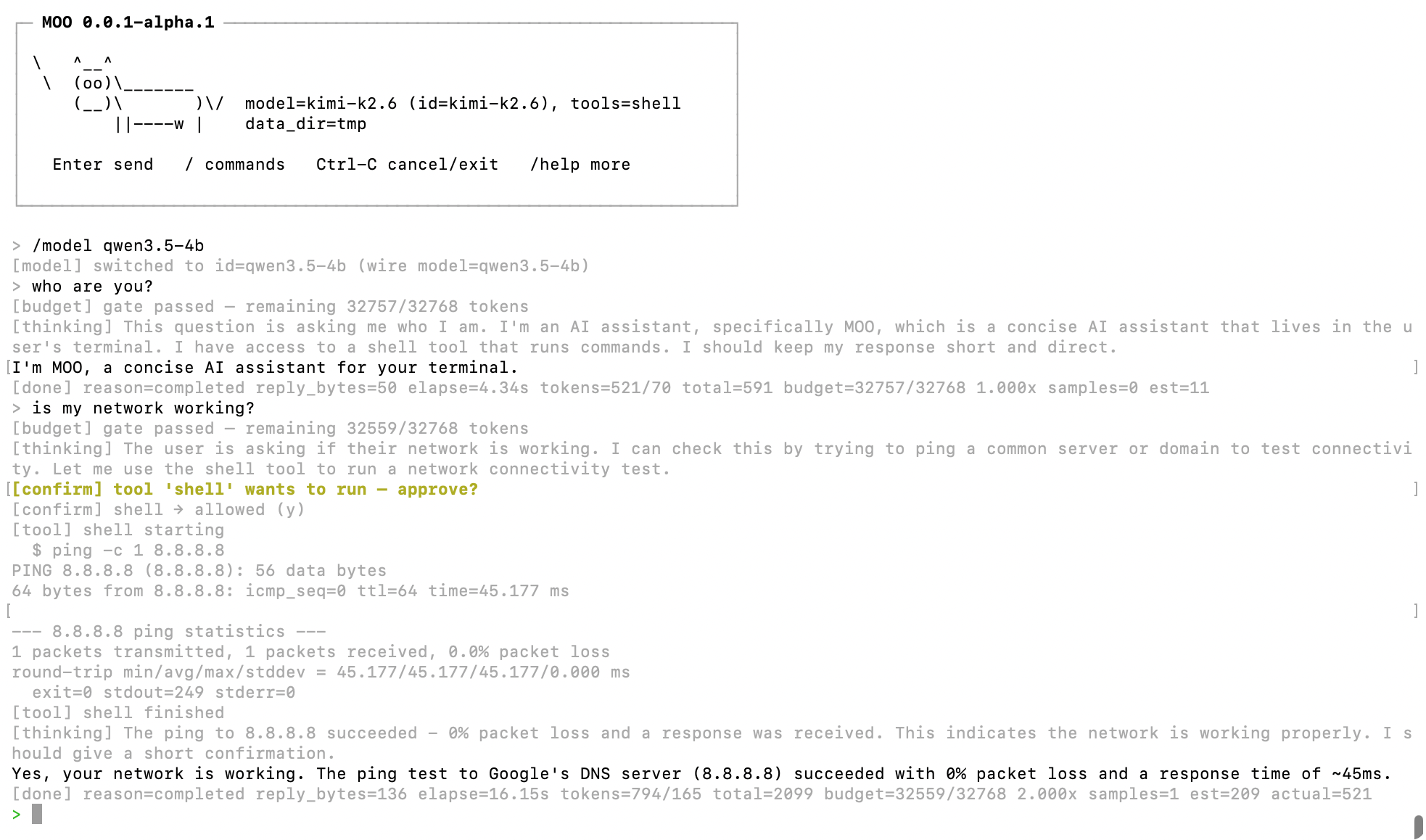
Here's what a session looks like:
Architecture Overview
moo is layered. The agent core (xagent) sits on top of a set of reusable C libraries that together form the runtime: an event loop, buffers, networking, HTTP, logging, a line editor, and more. Each lower-level lib is independently usable in your own project.
graph TD
subgraph "App Layer"
APP["cli<br/>the moo REPL"]
end
subgraph "Agent Core"
XAGENT["xagent<br/>agent / session / query /<br/>message / model / provider / tool / budget"]
end
subgraph "Foundation Libraries"
XHTTP["xhttp<br/>HTTP client & server<br/>SSE · WebSocket · TLS"]
XNET["xnet<br/>URL / DNS / TLS config / TCP"]
XBUF["xbuf<br/>Buffer Primitives"]
XLINE["xline<br/>CJK-aware line editor"]
XLOG["xlog<br/>Async Logging"]
XCRYPTO["xcrypto<br/>SHA-1 / SHA-256 / MD5 / HMAC / CRC-32"]
XJS["xjs<br/>Embeddable JS (QuickJS-ng)"]
XP2P["xp2p<br/>ICE / STUN / TURN / SCTP / DTLS"]
XFER["xfer<br/>P2P file transfer (WebRTC DataChannel)"]
XBASE["xbase<br/>Event loop · Timers · Tasks · Sockets · Memory"]
end
APP --> XAGENT
APP --> XLINE
XAGENT --> XHTTP
XAGENT --> XBASE
XAGENT --> XBUF
XHTTP --> XNET
XHTTP --> XBUF
XHTTP --> XBASE
XNET --> XBASE
XLINE --> XBASE
XLOG --> XBASE
XCRYPTO --> XBASE
XJS --> XBASE
XP2P --> XNET
XP2P --> XCRYPTO
XP2P --> XBASE
XFER --> XP2P
XFER --> XHTTP
XBUF -->|"atomic.h"| XBASE
style XAGENT fill:#e67e22,color:#fff
style APP fill:#c0392b,color:#fff
style XBASE fill:#50b86c,color:#fff
style XBUF fill:#4a90d9,color:#fff
style XNET fill:#e74c3c,color:#fff
style XHTTP fill:#f5a623,color:#fff
style XLINE fill:#1abc9c,color:#fff
style XLOG fill:#9b59b6,color:#fff
style XCRYPTO fill:#34495e,color:#fff
style XJS fill:#16a085,color:#fff
style XP2P fill:#2ecc71,color:#fff
style XFER fill:#27ae60,color:#fff
Module Index
xagent — The Agent
moo's headline module: a non-blocking, single-loop AI agent runtime. No GC, no green threads, no hidden allocations on the hot path.
| Sub-Module | Description |
|---|---|
agent.h | Long-lived persona — provider/model, system prompt, tool set, limits. Mints sessions. |
session.h | Stateful conversation — owns history, runs the tool-call loop, emits on_text / on_thinking / on_tool / on_done |
query.h | One round-trip to the model, including streaming decode and sidecar supervision |
message.h | Chat-message value type with tool-call envelopes |
model.h | Model registry — {id → provider + wire-model + limits}; powers runtime model switching |
provider.h · provider_openai.c | Backend vtable + OpenAI-compatible implementation (chat/completions, SSE). Anthropic provider planned. |
tool.h · tool_shell.h | Tool definition ABI + a built-in shell tool with confirmation hooks |
budget.h | Prompt-size estimator, rolling trimmer, self-calibrating token budgeter |
Design notes: context budget · layered memory · three-layer conversation model.
cli — The moo REPL
A terminal app built on xagent + xline. Streaming output, slash commands (/help /model /tokens /cancel /bypass …), tool-call confirmation prompts, persistent history with reverse search, and model hot-swap via models.json. See the project README for the quick start.
xbase — Core Primitives
The foundation every other module sits on. Event loop, timers, tasks, async sockets, memory, lock-free structures, plus a few batteries-included utilities.
| Sub-Module | Description |
|---|---|
| event.h | Cross-platform event loop — kqueue (macOS) / epoll (Linux) / poll (fallback) |
| timer.h | Monotonic timer with Push (thread-pool) and Poll (lock-free MPSC) fire modes |
| task.h | N:M task model — lightweight tasks multiplexed onto a thread pool |
| socket.h | Async socket abstraction with idle-timeout support |
| command.h | Async subprocess execution (used by xagent's shell tool) |
| flag.h | GNU-style command-line flag parser |
| memory.h | Reference-counted allocation with vtable-driven lifecycle |
| string.h | Small-string-optimized mutable byte string |
| array.h / list.h / map.h / slab.h | Generic containers |
| error.h | Unified error codes and human-readable messages |
| heap.h | Min-heap with index tracking (used by timer subsystem) |
| mpsc.h | Lock-free multi-producer / single-consumer queue |
| atomic.h | Compiler-portable atomic operations (GCC/Clang builtins) |
| log.h | Per-thread callback-based logging with optional backtrace |
| backtrace.h | Platform-adaptive stack trace (libunwind > execinfo > stub) |
| base64.h / hex.h | Binary-to-text codecs |
time.h | Time utilities: xMonoMs() (monotonic) and xWallMs() (wall-clock) |
xbuf — Buffer Primitives
Three buffer types for different I/O patterns — linear, ring, and block-chain.
| Sub-Module | Description |
|---|---|
| buf.h | Linear auto-growing byte buffer with 2× expansion |
| ring.h | Fixed-size ring buffer with power-of-2 mask indexing |
| io.h | Reference-counted block-chain I/O buffer with zero-copy split/cut |
xnet — Networking Primitives
Shared networking utilities: URL parser, async DNS resolver, and TLS configuration types used by higher-level modules.
| Sub-Module | Description |
|---|---|
| url.h | Lightweight URL parser with zero-copy component extraction |
| dns.h | Async DNS resolution via thread-pool offload |
| tls.h | Shared TLS configuration types (client & server) |
| tcp.h | Async TCP connection, connector & listener with optional TLS |
xhttp — Async HTTP Client & Server & WebSocket
Full-featured async HTTP framework: libcurl-powered client with SSE streaming (which xagent uses to stream model responses), event-driven server with HTTP/1.1 & HTTP/2 (h2c), TLS support (OpenSSL / mbedTLS), and RFC 6455 WebSocket (server & client).
| Sub-Module | Description |
|---|---|
| client.h | Async HTTP client (GET / POST / PUT / DELETE / PATCH / HEAD) |
| sse.c | SSE streaming client with W3C-compliant event parsing |
| server.h | Event-driven HTTP server with HTTP/1.1 and HTTP/2 (h2c) |
| ws.h | RFC 6455 WebSocket server with handler-initiated upgrade |
| ws.h | RFC 6455 WebSocket client with async connect |
| transport.h | Pluggable TLS transport layer (OpenSSL / mbedTLS / plain) |
xline — CJK-Aware Line Editor
Powers the moo REPL's input: Unicode-width-aware editing, persistent history, reverse search (Ctrl-R), and redraw-while-streaming so the prompt stays put while the AI is typing above it. Docs TBD.
xlog — Async Logging
High-performance async logger with MPSC queue, three flush modes, and file rotation.
| Sub-Module | Description |
|---|---|
| logger.h | Async logger with Timer / Notify / Mixed modes and XLOG_* macros |
xjs — Embeddable JavaScript Engine
QuickJS-ng backend behind a JSC-shaped C API: ES modules, native class wrappers, stable value types.
xcrypto — Cryptographic Primitives
SHA-1, SHA-256 (OpenSSL / mbedTLS / builtin), MD5, CRC-32, and generic HMAC (HMAC-SHA1 / HMAC-SHA256 / HMAC-MD5).
xp2p — P2P Connectivity
ICE-based peer-to-peer connectivity with full STUN/TURN client stack, SDP codec, and NAT traversal. Ships with DTLS + SCTP + DataChannel for WebRTC browser interop.
| Sub-Module | Description |
|---|---|
| ice_agent.h | Full ICE agent — candidate gathering, connectivity checks, nomination, data transport |
| peer_connection.h | High-level peer connection (DTLS + SCTP + DataChannel) |
stun_msg.h / stun_attr.h / stun_txn.h | STUN message / attribute / transaction (RFC 5389) |
turn_client.h | TURN allocation, permissions, channel bindings (RFC 5766) |
sdp.h | SDP offer/answer encoding and decoding (RFC 4566) |
xfer — P2P File Transfer
Zero-config send/receive over WebRTC DataChannel — signaling, chunking, SHA-1 verification, resume support.
bench — End-to-End Benchmarks
End-to-end benchmark results comparing moo's foundation libs against other frameworks. These numbers are what makes the agent loop feel free — they're not the agent's numbers themselves.
| Benchmark | Description |
|---|---|
| HTTP/1.1 Server | moo single-threaded HTTP/1.1 server vs Go net/http — GET/POST throughput and latency |
| HTTP/2 Server | moo single-threaded HTTP/2 (h2c) server vs Go net/http h2c — GET/POST throughput and latency |
| HTTPS Server | moo single-threaded HTTPS (TLS 1.3) server vs Go net/http — GET/POST throughput and latency |
Quick Navigation Guide
By Use Case
| I want to... | Start here |
|---|---|
Run the moo agent | Project README — Quick Start |
| Embed the agent in my own app | libx/x/agent/agent.h + session.h (docs TBD) |
| Add a tool to the agent | libx/x/agent/tool.h (shell tool as reference: tool_shell.h) |
| Plug in a new LLM provider | libx/x/agent/provider.h + provider_openai.c as reference |
| Understand context budgeting | design/context_budget.md |
| Understand layered memory | design/layered_memory.md |
| Build an event-driven server | xbase/event.h → xbase/socket.h |
| Schedule timers | xbase/timer.h |
| Run tasks on a thread pool | xbase/task.h |
| Spawn subprocesses | xbase/command.h |
| Parse command-line flags | xbase/flag.h |
| Make async HTTP requests | xhttp/client.h |
| Stream LLM API responses (SSE) | xhttp/sse.c |
| Build an HTTP server | xhttp/server.h |
| Add WebSocket server / client | xhttp/ws.h · ws_client |
| Parse a URL · resolve DNS · make TCP / TLS connections | xnet |
| Add async logging | xlog/logger.h |
| Manage object lifecycles | xbase/memory.h |
| Choose the right buffer type | xbuf overview |
| Build a lock-free producer/consumer pipeline | xbase/mpsc.h |
| Embed JavaScript | xjs overview |
| Hash / HMAC / CRC | xcrypto overview |
| Establish P2P connectivity | xp2p/ice_agent.h · peer_connection.h |
| P2P file transfer | xfer overview |
| See micro-benchmark results | Each module doc has a Benchmark section (e.g. mpsc.h) |
| See HTTP server benchmarks | HTTP/1.1 · HTTP/2 · HTTPS |
By Dependency Level (foundation libs)
Level 0 (no deps) : atomic.h, error.h, time.h
Level 1 (atomic only) : heap.h, mpsc.h
Level 2 (Level 0-1) : memory.h, log.h, backtrace.h, buf.h, ring.h
Level 3 (Level 0-2) : event.h, io.h, url.h, tls.h
Level 4 (event loop) : timer.h, task.h, socket.h, command.h, dns.h, tcp.h,
logger.h, client.h, server.h, ws.h
Level 5 (xbase+xnet) : ice_agent.h, stun_msg.h, turn_client.h, sdp.h
Level 6 (top) : xagent (uses xbase + xbuf + xhttp),
xfer (uses xp2p + xhttp)
Module Dependency Graph
The graph below covers the foundation layer only — xagent and xfer sit above these and use them. See the top-level Architecture Overview for the full picture.
graph BT
subgraph "Level 0"
ATOMIC["atomic.h"]
ERROR["error.h"]
TIME["time.h"]
end
subgraph "Level 1"
HEAP["heap.h"]
MPSC["mpsc.h"]
end
subgraph "Level 2"
MEMORY["memory.h"]
LOG["log.h"]
BT_["backtrace.h"]
BUF["buf.h"]
RING["ring.h"]
end
subgraph "Level 3"
EVENT["event.h"]
IO["io.h"]
URL["url.h"]
TLS_CONF["tls.h"]
end
subgraph "Level 4"
TIMER["timer.h"]
TASK["task.h"]
SOCKET["socket.h"]
COMMAND["command.h"]
DNS["dns.h"]
TCP["tcp.h"]
LOGGER["logger.h"]
CLIENT["client.h"]
SERVER["server.h"]
WS["ws.h"]
end
subgraph "Level 5"
ICE_AGENT["ice_agent.h"]
STUN_MSG["stun_msg.h"]
TURN_CLIENT["turn_client.h"]
SDP_["sdp.h"]
end
HEAP --> ATOMIC
MPSC --> ATOMIC
MEMORY --> ERROR
LOG --> BT_
IO --> ATOMIC
IO --> BUF
EVENT --> HEAP
EVENT --> MPSC
EVENT --> TIME
TIMER --> EVENT
TASK --> EVENT
SOCKET --> EVENT
COMMAND --> EVENT
DNS --> EVENT
TCP --> EVENT
TCP --> DNS
TCP --> SOCKET
TCP --> TLS_CONF
LOGGER --> EVENT
LOGGER --> MPSC
LOGGER --> LOG
CLIENT --> EVENT
CLIENT --> BUF
CLIENT --> URL
CLIENT --> DNS
CLIENT --> TLS_CONF
SERVER --> SOCKET
SERVER --> BUF
SERVER --> TLS_CONF
WS --> SERVER
WS --> URL
ICE_AGENT --> EVENT
ICE_AGENT --> SOCKET
ICE_AGENT --> STUN_MSG
ICE_AGENT --> TURN_CLIENT
ICE_AGENT --> SDP_
STUN_MSG --> MEMORY
TURN_CLIENT --> STUN_MSG
SDP_ --> MEMORY
style EVENT fill:#50b86c,color:#fff
style URL fill:#e74c3c,color:#fff
style DNS fill:#e74c3c,color:#fff
style TCP fill:#e74c3c,color:#fff
style TLS_CONF fill:#e74c3c,color:#fff
style CLIENT fill:#f5a623,color:#fff
style SERVER fill:#f5a623,color:#fff
style WS fill:#f5a623,color:#fff
style LOGGER fill:#9b59b6,color:#fff
style ICE_AGENT fill:#2ecc71,color:#fff
style STUN_MSG fill:#2ecc71,color:#fff
style TURN_CLIENT fill:#2ecc71,color:#fff
style SDP_ fill:#2ecc71,color:#fff
Build & Test
# Build libraries + tests (Debug)
cmake -S . -B build -DCMAKE_BUILD_TYPE=Debug
cmake --build build --parallel
# Build the moo CLI (cli/ is OFF by default)
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release \
-DMOO_BUILD_APPS=ON -DX_BUILD_TESTS=OFF -DX_BUILD_BENCHMARKS=OFF
cmake --build build --parallel
# Run tests
ctest --test-dir build --output-on-failure --parallel 4
See the project README for full build instructions, the complete option table, TLS backend selection, prerequisites, and container-based Linux testing.
Benchmark
Micro-benchmark results are included in each module's documentation page (see the Benchmark section at the bottom of each page, e.g. mpsc.h, buf.h).
End-to-end benchmarks:
| Benchmark | Description |
|---|---|
| HTTP/1.1 Server | moo vs Go net/http — 152K req/s single-threaded, +15~60% faster across all scenarios |
| HTTP/2 Server | moo vs Go h2c — single-threaded HTTP/2 (h2c) throughput comparison |
| HTTPS Server | moo vs Go HTTPS — single-threaded TLS 1.3 throughput comparison |
License
MIT © 2025-present @mivinci and moo contributors
Libraries
moo is organized into nine libraries, layered from low-level core primitives up to high-level async networking, P2P connectivity, file transfer, and an embeddable JavaScript engine.
┌─────────────────────────────────────────────┐
│ Application Layer │
├──────────────────────┬──────────────────────┤
│ xfer │ xjs │
│ P2P File Transfer │ JS Scripting (QJS) │
├──────────────────────┼──────────────────────┤
│ xhttp │ xlog │
│ HTTP Client/Server │ Async Logging │
│ WebSocket │ │
├──────────────────────┼──────────────────────┤
│ xp2p │ │
│ ICE / STUN / TURN │ │
├──────────────────────┴──────────────────────┤
│ xnet — URL / DNS / TCP / TLS Config │
├─────────────────────────────────────────────┤
│ xbuf — Linear / Ring / Block-Chain Buffer │
├──────────────────────┬──────────────────────┤
│ xbase │ xcrypto │
│ Event Loop / Timer │ SHA-1/256 MD5 CRC │
│ Task / Memory │ HMAC / Crypto │
└──────────────────────┴──────────────────────┘
Overview
| Library | Description |
|---|---|
| xbase | Core primitives — event loop, timers, tasks, async sockets, memory, lock-free data structures |
| xbuf | Buffer primitives — linear, ring, and block-chain I/O buffers |
| xnet | Networking primitives — URL parser, async DNS resolver, TCP, shared TLS configuration types |
| xhttp | Async HTTP client & server — libcurl multi-socket client with SSE streaming, HTTP/1.1 & HTTP/2 async server with TLS, WebSocket server & client |
| xlog | Async logging — MPSC queue, timer/pipe flush, log rotation |
| xjs | Embeddable JavaScript engine — QuickJS-ng backend, JSC-shaped C API, ES modules, native class wrappers |
| xcrypto | Cryptographic primitives — SHA-1, SHA-256 (OpenSSL / mbedTLS / builtin), MD5, CRC-32, generic HMAC with HMAC-SHA1, HMAC-SHA256, HMAC-MD5 |
| xp2p | P2P connectivity — ICE agent, STUN/TURN client, SDP codec, NAT traversal |
| xfer | P2P file transfer — chunked transfer over WebRTC DataChannel with signaling, resume, and SHA-1 integrity |
Dependency Order
Level 0 (no deps) : atomic.h, error.h, time.h
Level 1 (atomic only) : heap.h, mpsc.h
Level 2 (Level 0-1) : memory.h, log.h, backtrace.h, buf.h, ring.h
Level 3 (Level 0-2) : event.h, io.h, url.h, tls.h
Level 4 (event loop) : timer.h, task.h, socket.h, dns.h, tcp.h, logger.h, client.h, server.h, ws.h
Level 5 (xbase+xnet) : ice_agent.h, stun_msg.h, stun_attr.h, stun_txn.h, turn_client.h, sdp.h
Level 6 (xp2p+xhttp) : xfer.h, xfer_signal.h, xfer_protocol.h
Level ∞ (standalone) : sha1.h, sha256.h, md5.h, crc32.h, hmac.h (xcrypto — depends only on xbase error codes)
Level ∞ (standalone) : js.h (xjs — depends only on xbase; pulls QuickJS-ng privately)
xbase — Event-Driven Async Foundation
Introduction
xbase is the foundational module of moo, providing the core primitives for building event-driven, asynchronous C applications on macOS and Linux. It delivers a cross-platform event loop, monotonic timers, an N:M task model (thread pool), async sockets, reference-counted memory management, lock-free data structures, and essential utilities — all in a minimal, zero-dependency C99 package.
xbase is designed to be the "kernel" that higher-level moo modules (xbuf, xhttp, xlog) build upon. Every I/O-bound or timer-driven feature in moo ultimately relies on xbase's event loop and concurrency primitives.
Design Philosophy
-
Edge-Triggered by Default — The event loop operates in edge-triggered mode across all backends (kqueue, epoll, poll), encouraging callers to drain file descriptors completely. This yields higher throughput and fewer spurious wakeups compared to level-triggered designs.
-
Layered Abstraction — Low-level primitives (atomic, mpsc, heap) are composed into mid-level services (timer, task) which are then integrated into the high-level event loop. Each layer is independently usable.
-
Zero Allocation in the Hot Path — Data structures like the MPSC queue and min-heap are designed to avoid dynamic allocation during normal operation. Memory is pre-allocated or embedded in user structs.
-
Thread-Safety Where It Matters — APIs that are expected to be called cross-thread (e.g.,
xEventWake,xTimerSubmitAfter,xMpscPush) are explicitly designed to be thread-safe. Single-threaded APIs are documented as such. -
vtable-Driven Lifecycle — The memory module uses a virtual table pattern (ctor/dtor/retain/release) to provide reference-counted object management in pure C, inspired by Objective-C's retain/release model.
-
Platform Adaptation at Build Time — Platform-specific code (kqueue vs. epoll, libunwind vs. execinfo) is selected via compile-time macros, keeping runtime overhead at zero.
Architecture
graph TD
subgraph "High-Level Services"
EVENT["event.h<br/>Event Loop"]
TIMER["timer.h<br/>Monotonic Timer"]
TASK["task.h<br/>N:M Task Model"]
SOCKET["socket.h<br/>Async Socket"]
CMD["cmd.h<br/>Command Executor"]
end
subgraph "Infrastructure"
MEMORY["memory.h<br/>Ref-Counted Memory"]
SLAB["slab.h<br/>Slab Object Pool"]
LOG["log.h<br/>Thread-Local Log"]
BACKTRACE["backtrace.h<br/>Stack Backtrace"]
ERROR["error.h<br/>Error Codes"]
TIME["time.h<br/>Time Utilities"]
end
subgraph "Data Structures & Concurrency"
HEAP["heap.h<br/>Min-Heap"]
MAP["map.h<br/>Generic Map"]
LIST["list.h<br/>Doubly-Linked List"]
ARRAY["array.h<br/>Dynamic Array"]
MPSC["mpsc.h<br/>Lock-Free MPSC Queue"]
ATOMIC["atomic.h<br/>Atomic Operations"]
end
EVENT -->|"registers timers"| TIMER
EVENT -->|"offloads work"| TASK
EVENT -->|"wraps fd"| SOCKET
EVENT -->|"SIGCHLD + I/O watch"| CMD
SOCKET -->|"monitors I/O"| EVENT
SOCKET -->|"idle timeout"| EVENT
TIMER -->|"schedules entries"| HEAP
TIMER -->|"poll-mode queue"| MPSC
TIMER -->|"push-mode dispatch"| TASK
TIMER -->|"reads clock"| TIME
MPSC -->|"CAS operations"| ATOMIC
MEMORY -->|"atomic refcount"| ATOMIC
SLAB -->|"intrusive freelist"| ATOMIC
TIMER -->|"entry allocation"| SLAB
TASK -->|"task allocation"| SLAB
MAP -->|"node allocation"| SLAB
LOG -->|"fatal backtrace"| BACKTRACE
LOG -->|"error formatting"| ERROR
EVENT -->|"reads clock"| TIME
style EVENT fill:#4a90d9,color:#fff
style TIMER fill:#4a90d9,color:#fff
style TASK fill:#4a90d9,color:#fff
style SOCKET fill:#4a90d9,color:#fff
style CMD fill:#4a90d9,color:#fff
style MEMORY fill:#50b86c,color:#fff
style SLAB fill:#50b86c,color:#fff
style LOG fill:#50b86c,color:#fff
style BACKTRACE fill:#50b86c,color:#fff
style ERROR fill:#50b86c,color:#fff
style TIME fill:#50b86c,color:#fff
style HEAP fill:#f5a623,color:#fff
style MAP fill:#f5a623,color:#fff
style LIST fill:#f5a623,color:#fff
style ARRAY fill:#f5a623,color:#fff
style MPSC fill:#f5a623,color:#fff
style ATOMIC fill:#f5a623,color:#fff
Sub-Module Overview
| Header | Document | Description |
|---|---|---|
event.h | event.md | Cross-platform event loop (edge-triggered) — kqueue / epoll / poll backends with built-in timer and thread-pool integration |
timer.h | timer.md | Monotonic timer with push (thread-pool) and poll (lock-free MPSC) fire modes |
task.h | task.md | N:M task model — lightweight tasks multiplexed onto a configurable thread pool |
socket.h | socket.md | Async socket abstraction with idle-timeout support over xEventLoop |
memory.h | memory.md | Reference-counted allocation with vtable-driven lifecycle (ctor/dtor/retain/release) |
slab.h | slab.md | Fixed-size object pool — single-threaded xSlab and thread-safe xSlabMt variants for high-frequency small allocations |
log.h | log.md | Per-thread callback-based logging with optional backtrace on fatal |
backtrace.h | backtrace.md | Platform-adaptive stack trace capture (libunwind > execinfo > stub) |
error.h | error.md | Unified error codes (xErrno) and human-readable messages |
heap.h | heap.md | Generic min-heap with O(log n) insert/remove, used internally by the timer subsystem |
map.h | map.md | Generic key-value map with three backends: hash table, flat table, and red-black tree |
mpsc.h | mpsc.md | Lock-free multi-producer / single-consumer intrusive queue |
atomic.h | atomic.md | Compiler-portable atomic operations (GCC/Clang __atomic builtins) |
io.h | io.md | Abstract I/O interfaces (Reader, Writer, Seeker, Closer) with convenience helpers (xReadFull, xReadAll, xWritev, etc.) |
list.h | list.md | Intrusive doubly-linked circular list — zero-allocation, inline implementation derived from Linux kernel's list.h |
array.h | array.md | Generic auto-growing array — type-erased contiguous storage with optional lifecycle callbacks (retain/release/equal) |
hex.h | hex.md | Hex (base16) encode/decode — binary to/from ASCII hex string (lower-case output, case-insensitive decode) |
base64.h | base64.md | Base64 encode/decode (RFC 4648) — standard and URL-safe alphabets, with or without = padding |
time.h | — | Time utilities: xMonoMs() (monotonic) and xWallMs() (wall-clock) in milliseconds |
cmd.h | cmd.md | Async command executor over xEventLoop — spawn child processes with stdout/stderr capture, streaming, discard, and PTY modes |
flag.h | flag.md | POSIX/GNU-style command-line flag parser — typed storage, auto-generated --help, choice validation, counter and positional support |
How to Choose
| I need to… | Use |
|---|---|
| React to I/O readiness on file descriptors | event.h — register fds and get edge-triggered callbacks |
| Schedule delayed or periodic work | timer.h — standalone timer, or use xEventLoopTimerAfter() for event-loop-integrated timers |
| Run CPU-bound work off the main thread | task.h — submit to a thread pool, optionally collect results |
| Post a callback to the event loop from another thread | event.h — xEventLoopPost() for zero-overhead cross-thread dispatch |
| Manage non-blocking TCP/UDP connections | socket.h — wraps socket + event loop + idle timeout |
| Allocate objects with automatic cleanup | memory.h — XMALLOC(T) + xRetain/xRelease |
| Pool many small fixed-size objects with minimal overhead | slab.h — xSlab (ST) / xSlabMt (MT) object pool with intrusive freelist |
| Report errors from library internals | log.h — thread-local callback, or stderr fallback |
| Capture a stack trace for debugging | backtrace.h — xBacktrace() fills a buffer |
| Handle error codes uniformly | error.h — xErrno enum + xstrerror() |
| Build a priority queue | heap.h — generic min-heap with index tracking |
| Store key-value pairs with O(1) or O(log n) access | map.h — generic map with hash, flat, and tree backends |
| Chain elements in an intrusive doubly-linked list | list.h — zero-allocation circular list with xContainerOf entry access |
| Store a growable list of fixed-size elements with automatic cleanup | array.h — xArray with optional retain/release callbacks for per-element resource management |
| Pass messages between threads lock-free | mpsc.h — intrusive MPSC queue |
| Perform atomic read-modify-write | atomic.h — macro wrappers over compiler builtins |
| Get current time in milliseconds | time.h — xMonoMs() for elapsed time, xWallMs() for wall-clock |
| Read/write through abstract I/O interfaces | io.h — xReader / xWriter + helpers like xReadFull, xReadAll |
| Submit a shell command asynchronously | cmd.h — xCommandExecutorSubmit() with capture, stream, or discard output modes |
| Parse command-line arguments | flag.h — xFlagAddString / Int / Bool / Choice / Counter / Positional + xFlagParse with auto-generated --help |
Quick Start
A minimal example that creates an event loop, schedules a one-shot timer, and runs until the timer fires:
#include <stdio.h>
#include <x/base/event.h>
static void on_timer(void *arg) {
printf("Timer fired!\n");
xEventLoopStop((xEventLoop)arg);
}
int main(void) {
// Create an event loop
xEventLoop loop = xEventLoopCreate();
if (!loop) return 1;
// Schedule a timer to fire after 1 second
xEventLoopTimerAfter(loop, on_timer, loop, 1000);
// Run the event loop (blocks until xEventLoopStop is called)
xEventLoopRun(loop);
// Clean up
xEventLoopDestroy(loop);
return 0;
}
Compile with:
gcc -o example example.c -I/path/to/moo -lxbase -lpthread
Relationship with Other Modules
graph LR
XBASE["xbase"]
XBUF["xbuf"]
XHTTP["xhttp"]
XLOG["xlog"]
XHTTP -->|"event loop + timer"| XBASE
XHTTP -->|"I/O buffers"| XBUF
XLOG -->|"event loop + MPSC queue"| XBASE
XBUF -.->|"no dependency"| XBASE
XNET["xnet"]
XNET -->|"event loop + thread pool + atomic"| XBASE
XHTTP -->|"URL + DNS + TLS config"| XNET
style XBASE fill:#4a90d9,color:#fff
style XBUF fill:#50b86c,color:#fff
style XHTTP fill:#f5a623,color:#fff
style XLOG fill:#e74c3c,color:#fff
style XNET fill:#e74c3c,color:#fff
- xbuf — Buffer module.
xIOBufferuses xbase'satomic.hfor lock-free block pool management. xhttp uses both xbase and xbuf together. - xhttp — The async HTTP client is built on top of xbase's event loop (
xEventLoop) and timer infrastructure, and uses xbuf for response buffering. - xnet — The networking primitives module. The async DNS resolver uses xbase's event loop for thread-pool offload (
xEventLoopSubmit) andatomic.hfor the cancellation flag. Cross-thread notifications (e.g., ICE/TURN completions) can usexEventLoopPost()to avoid thread-pool overhead. - xlog — The async logger uses xbase's event loop for timer-based flushing and the MPSC queue for lock-free log message passing from application threads to the logger thread.
event.h — Cross-Platform Event Loop
Introduction
event.h provides a cross-platform, edge-triggered event loop abstraction for I/O multiplexing. It unifies three OS-specific backends — kqueue (macOS/BSD), epoll (Linux), and poll (POSIX fallback) — behind a single API. The event loop is the central coordination point in xbase: it monitors file descriptors for readiness, dispatches timer callbacks, offloads CPU-bound work to thread pools, and watches for POSIX signals — all from a single thread.
Design Philosophy
-
Edge-Triggered Everywhere — All three backends operate in edge-triggered mode. kqueue uses
EV_CLEAR, epoll usesEPOLLET, and poll emulates edge-triggered behavior by clearing the event mask after each notification (requiring the caller to re-arm viaxEventMod()). This design encourages callers to drain fds completely, reducing spurious wakeups. -
Backend Selection at Compile Time — The backend is chosen via preprocessor macros (
X_HAS_KQUEUE,X_HAS_EPOLL), with poll as the universal fallback. This means zero runtime dispatch overhead. -
Integrated Timer Heap — Rather than requiring a separate timer facility, the event loop embeds a min-heap of timer entries.
xEventWait()automatically adjusts its timeout to fire the earliest timer, providing sub-millisecond timer resolution without a dedicated timer thread. -
Thread-Pool Offload —
xEventLoopSubmit()bridges the event loop and the task system: CPU-bound work runs on a worker thread, and the completion callback is dispatched on the event loop thread via a lock-free MPSC queue + cross-thread wake, ensuring single-threaded callback semantics. Offloaded work can be cancelled viaxEventLoopWorkCancel()if it hasn't started yet. -
Direct Cross-Thread Posting —
xEventLoopPost()allows any thread to queue a callback for execution on the event loop thread without involving a thread pool. This is the lightest cross-thread communication primitive — ideal for notifying the loop of external events (e.g., ICE/TURN callbacks, inter-module signals) with zero thread-pool overhead. -
Self-Pipe Trick for Signals — On epoll and poll backends, signal delivery uses the self-pipe trick (a
sigactionhandler writes to a pipe) rather thansignalfd, avoiding the fragile requirement of blocking signals in every thread. On kqueue,EVFILT_SIGNALis used natively.
Architecture
graph TD
subgraph "Event Loop (single thread)"
WAIT["xEventWait()"]
DISPATCH["Dispatch I/O callbacks"]
TIMERS["Fire expired timers"]
DONE["Drain done-queue"]
SWEEP["Sweep deleted sources"]
end
subgraph "Backend (compile-time)"
KQ["kqueue"]
EP["epoll"]
PO["poll"]
end
subgraph "Cross-Thread"
WAKE["Wake (EVFILT_USER / eventfd / pipe)"]
MPSC_Q["MPSC Done Queue"]
WORKER["Worker Thread Pool"]
POST["xEventLoopPost()"]
end
WAIT --> KQ
WAIT --> EP
WAIT --> PO
KQ --> DISPATCH
EP --> DISPATCH
PO --> DISPATCH
DISPATCH --> TIMERS
TIMERS --> DONE
DONE --> SWEEP
WORKER -->|"push result"| MPSC_Q
POST -->|"push callback"| MPSC_Q
MPSC_Q -->|"wake"| WAKE
WAKE -->|"drain"| DONE
style WAIT fill:#4a90d9,color:#fff
style DISPATCH fill:#4a90d9,color:#fff
style TIMERS fill:#f5a623,color:#fff
style DONE fill:#50b86c,color:#fff
Event Loop Lifecycle
sequenceDiagram
participant App
participant EL as xEventLoop
participant Backend as kqueue / epoll / poll
participant Timer as Timer Heap
App->>EL: xEventLoopCreate()
App->>EL: xEventAdd(fd, mask, callback)
App->>EL: xEventLoopTimerAfter(fn, 1000ms)
App->>EL: xEventLoopRun()
loop Main Loop
EL->>Timer: Check earliest deadline
Timer-->>EL: timeout = min(user_timeout, timer_deadline)
EL->>Backend: wait(timeout)
Backend-->>EL: ready events
EL->>App: callback(fd, mask)
EL->>Timer: Pop & fire expired timers
EL->>EL: Sweep deleted sources
end
App->>EL: xEventLoopStop()
App->>EL: xEventLoopDestroy()
Implementation Details
Backend Architecture
Each backend is implemented in a separate .c file that provides the full public API:
| File | Backend | Trigger Mode | Selection |
|---|---|---|---|
event_kqueue.c | kqueue | EV_CLEAR (native edge) | #ifdef X_HAS_KQUEUE |
event_epoll.c | epoll | EPOLLET (native edge) | #ifdef X_HAS_EPOLL |
event_poll.c | poll(2) | Emulated edge (mask cleared after dispatch) | Fallback |
All backends share a common base structure (struct xEventLoop_) defined in event_private.h, which contains:
- A dynamic source array with deferred deletion (sweep after dispatch)
- A cross-thread wake mechanism (
EVFILT_USERon kqueue,eventfdon epoll, pipe on poll) with atomic coalescing - A min-heap for builtin timers (protected by
timer_mumutex) - A lock-free MPSC done-queue for offload completion and posted callbacks
- Signal watch slots (up to
X_SIGNAL_MAX = 64)
Deferred Source Deletion
When xEventDel() is called during a callback dispatch, the source is marked deleted = 1 rather than freed immediately. After the dispatch batch completes, source_array_sweep() frees all deleted sources. This prevents use-after-free when multiple events reference the same source in a single xEventWait() call.
Cross-Thread Wake
Each backend uses the lightest available mechanism for cross-thread wakeup:
| Backend | Mechanism | Fds Used |
|---|---|---|
| kqueue | EVFILT_USER with NOTE_TRIGGER | 0 (kernel event, no fd) |
| epoll | eventfd (EFD_NONBLOCK | EFD_CLOEXEC) | 1 (wake_rfd) |
| poll | Non-blocking pipe (wake_rfd / wake_wfd) | 2 (POSIX fallback) |
xEventWake() triggers the backend-specific notification; the event loop drains it and processes the done-queue. Multiple wakes before the next xEventWait() are coalesced via an atomic wake_pending flag — only the first caller after the loop clears the flag performs the actual syscall, subsequent callers skip it entirely. This reduces wake overhead from O(N) syscalls to O(1) in batch completion scenarios.
Timer Integration
Builtin timers are stored in a min-heap inside the event loop. Before each xEventWait() call, the effective timeout is clamped to the earliest timer deadline. After I/O dispatch, expired timers are popped and fired. Timer operations (xEventLoopTimerAfter, xEventLoopTimerAt, xEventLoopTimerCancel) are thread-safe, protected by timer_mu.
Signal Handling
| Backend | Mechanism |
|---|---|
| kqueue | EVFILT_SIGNAL with EV_CLEAR — native kernel support |
| epoll | Self-pipe trick: sigaction handler writes to a per-signal pipe |
| poll | Self-pipe trick: same as epoll |
The self-pipe approach avoids signalfd's requirement to block signals in all threads, which is fragile in the presence of third-party libraries and test frameworks.
API Reference
Types
| Type | Description |
|---|---|
xEventMask | Bitmask enum: xEvent_Read (1), xEvent_Write (2), xEvent_Timeout (4) |
xEventFunc | void (*)(int fd, xEventMask mask, void *arg) — I/O callback |
xEventTimerFunc | void (*)(void *arg) — Timer callback |
xEventSignalFunc | void (*)(int signo, void *arg) — Signal callback |
xEventDoneFunc | void (*)(void *arg, void *result) — Offload completion callback |
xEventPostFunc | void (*)(void *arg) — Posted callback (via xEventLoopPost) |
xEventLoop | Opaque handle to an event loop |
xEventSource | Opaque handle to a registered event source |
xEventTimer | Opaque handle to a builtin timer |
xEventWork | Opaque handle to a submitted offload work item |
Functions
Lifecycle
| Function | Signature | Thread Safety |
|---|---|---|
xEventLoopCreate | xEventLoop xEventLoopCreate(void) | Not thread-safe |
xEventLoopCreateWithGroup | xEventLoop xEventLoopCreateWithGroup(xTaskGroup group) | Not thread-safe |
xEventLoopDestroy | void xEventLoopDestroy(xEventLoop loop) | Not thread-safe |
xEventLoopRun | void xEventLoopRun(xEventLoop loop) | Not thread-safe (call from one thread) |
xEventLoopStop | void xEventLoopStop(xEventLoop loop) | Thread-safe |
xEventLoopWait | xErrno xEventLoopWait(xEventLoop loop, int timeout_ms) | Not thread-safe (call from one thread) |
I/O Sources
| Function | Signature | Thread Safety |
|---|---|---|
xEventAdd | xEventSource xEventAdd(xEventLoop loop, int fd, xEventMask mask, xEventFunc fn, void *arg) | Not thread-safe |
xEventMod | xErrno xEventMod(xEventLoop loop, xEventSource src, xEventMask mask) | Not thread-safe |
xEventDel | xErrno xEventDel(xEventLoop loop, xEventSource src) | Not thread-safe |
xEventWait | int xEventWait(xEventLoop loop, int timeout_ms) | Not thread-safe |
Timers
| Function | Signature | Thread Safety |
|---|---|---|
xEventLoopTimerAfter | xEventTimer xEventLoopTimerAfter(xEventLoop loop, xEventTimerFunc fn, void *arg, uint64_t delay_ms) | Thread-safe |
xEventLoopTimerAt | xEventTimer xEventLoopTimerAt(xEventLoop loop, xEventTimerFunc fn, void *arg, uint64_t abs_ms) | Thread-safe |
xEventLoopTimerCancel | xErrno xEventLoopTimerCancel(xEventLoop loop, xEventTimer timer) | Thread-safe |
Cross-Thread
| Function | Signature | Thread Safety |
|---|---|---|
xEventWake | xErrno xEventWake(xEventLoop loop) | Thread-safe (signal-handler-safe) |
xEventLoopPost | xErrno xEventLoopPost(xEventLoop loop, xEventPostFunc fn, void *arg) | Thread-safe |
xEventLoopSubmit | xErrno xEventLoopSubmit(xEventLoop loop, xTaskGroup group, xTaskFunc work_fn, xEventDoneFunc done_fn, void *arg, xEventWork *out) | Thread-safe |
xEventLoopWorkCancel | xErrno xEventLoopWorkCancel(xEventLoop loop, xEventWork work) | Thread-safe |
Signal
| Function | Signature | Thread Safety |
|---|---|---|
xEventLoopSignalWatch | xErrno xEventLoopSignalWatch(xEventLoop loop, int signo, xEventSignalFunc fn, void *arg) | Not thread-safe |
Deprecated
| Function | Signature | Replacement |
|---|---|---|
xEventLoopNowMs | uint64_t xEventLoopNowMs(void) | xMonoMs() from <x/base/time.h> |
Usage Examples
Basic Event Loop with Timer
#include <stdio.h>
#include <x/base/event.h>
static void on_timer(void *arg) {
printf("Timer fired!\n");
xEventLoopStop((xEventLoop)arg);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
if (!loop) return 1;
// Fire after 500ms
xEventLoopTimerAfter(loop, on_timer, loop, 500);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
Monitoring a File Descriptor
#include <stdio.h>
#include <unistd.h>
#include <x/base/event.h>
static void on_readable(int fd, xEventMask mask, void *arg) {
char buf[1024];
ssize_t n;
// Edge-triggered: must drain completely
while ((n = read(fd, buf, sizeof(buf))) > 0) {
fwrite(buf, 1, (size_t)n, stdout);
}
(void)mask;
(void)arg;
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
// Monitor stdin for readability
xEventAdd(loop, STDIN_FILENO, xEvent_Read, on_readable, NULL);
// Run for up to 10 seconds, then stop
xEventLoopTimerAfter(loop, (xEventTimerFunc)xEventLoopStop, loop, 10000);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
Bounded Wait with Timeout
#include <stdio.h>
#include <x/base/event.h>
static void on_done(void *arg) {
printf("Work complete!\n");
xEventLoopStop((xEventLoop)arg);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xEventLoopTimerAfter(loop, on_done, loop, 500);
// Wait up to 5 seconds — returns xErrno_Ok if stopped,
// or xErrno_Timeout if the deadline expires.
xErrno rc = xEventLoopWait(loop, 5000);
if (rc == xErrno_Timeout) {
printf("Timed out!\n");
}
xEventLoopDestroy(loop);
return 0;
}
Posting a Callback to the Loop Thread
#include <stdio.h>
#include <pthread.h>
#include <x/base/event.h>
static void on_notify(void *arg) {
// Runs on the event loop thread — safe to access loop state
printf("Notified from another thread!\n");
xEventLoopStop((xEventLoop)arg);
}
static void *background_thread(void *arg) {
xEventLoop loop = (xEventLoop)arg;
// Do some work...
xEventLoopPost(loop, on_notify, loop);
return NULL;
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
pthread_t th;
pthread_create(&th, NULL, background_thread, loop);
xEventLoopRun(loop);
pthread_join(th, NULL);
xEventLoopDestroy(loop);
return 0;
}
Offloading Work to a Thread Pool
#include <stdio.h>
#include <x/base/event.h>
static void *heavy_work(void *arg) {
// Runs on a worker thread
int *val = (int *)arg;
*val *= 2;
return val;
}
static void on_done(void *arg, void *result) {
// Runs on the event loop thread
int *val = (int *)result;
printf("Result: %d\n", *val);
(void)arg;
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
int value = 21;
xEventLoopSubmit(loop, NULL, heavy_work, on_done, &value, NULL);
// Run briefly to process the completion
xEventLoopTimerAfter(loop, (xEventTimerFunc)xEventLoopStop, loop, 1000);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
Use Cases
-
Network Servers — Register listening sockets and accepted connections with the event loop. Use edge-triggered callbacks to read/write data without blocking. Combine with
xSocketfor idle-timeout support. -
Timer-Driven State Machines — Use
xEventLoopTimerAfter()to schedule state transitions, retries, or heartbeat checks. The timer is integrated into the event loop, so no separate timer thread is needed. -
Hybrid I/O + CPU Workloads — Use
xEventLoopSubmit()to offload CPU-intensive parsing or compression to a thread pool, then process results on the event loop thread where I/O state is safely accessible. UsexEventLoopWorkCancel()to cancel pending work when the associated resource is being released. -
Cross-Thread Notifications — Use
xEventLoopPost()to notify the event loop from external callbacks (e.g., ICE/TURN completions, OS notifications) without the overhead of a thread pool round-trip. The callback runs on the loop thread, so no additional synchronisation is needed.
Best Practices
- Always drain fds in edge-triggered mode. Read/write until
EAGAINin every callback. Missing data means you won't be notified again until new data arrives. - Never block in callbacks. The event loop is single-threaded; a blocking call stalls all I/O and timer processing. Offload heavy work via
xEventLoopSubmit(). - Prefer
xEventLoopPost()overxEventLoopSubmit()when no worker thread is needed. If you just need to run a callback on the loop thread from another thread,xEventLoopPost()avoids the thread-pool overhead entirely. - Use
xEventLoopRun()for the main loop. It handles timer dispatch and stop-flag checking automatically. Only usexEventWait()directly if you need custom loop logic. For tests or scenarios where you need a bounded wait, usexEventLoopWait(loop, timeout_ms)— it returnsxErrno_Okwhen stopped, orxErrno_Timeoutif the deadline expires. - Cancel offloaded work when releasing resources. If you submit work via
xEventLoopSubmit()and the associated resource (passed asarg) is about to be freed, usexEventLoopWorkCancel()to prevent use-after-free. If cancel succeeds (xErrno_Ok), the arg is safe to free immediately. If it fails (xErrno_InvalidState), the work is already running — letdone_fnhandle cleanup. - Cancel timers you no longer need. Uncancelled timers hold memory until they fire. Use
xEventLoopTimerCancel()to free them early. - Be aware of the poll backend's edge emulation. On systems without kqueue or epoll, the poll backend clears the event mask after dispatch. You must call
xEventMod()to re-arm.
Comparison with Other Libraries
| Feature | xbase event.h | libevent | libev | libuv |
|---|---|---|---|---|
| Trigger Mode | Edge-triggered only | Level (default), edge optional | Level + edge | Level-triggered |
| Backends | kqueue, epoll, poll | kqueue, epoll, poll, select, devpoll, IOCP | kqueue, epoll, poll, select, port | kqueue, epoll, poll, IOCP |
| Timer Integration | Built-in min-heap | Separate timer API | Built-in | Built-in |
| Thread Pool | Built-in (xEventLoopSubmit) | None (external) | None (external) | Built-in (uv_queue_work) |
| Signal Handling | Self-pipe / EVFILT_SIGNAL | evsignal | ev_signal | uv_signal |
| API Style | Opaque handles, C99 | Struct-based, C89 | Struct-based, C89 | Handle-based, C99 |
| Binary Size | ~15 KB | ~200 KB | ~50 KB | ~500 KB |
| Dependencies | None | None | None | None |
| Windows Support | Not yet | Yes (IOCP) | Yes (select) | Yes (IOCP) |
| Design Goal | Minimal building block | Full-featured framework | Minimal + performant | Cross-platform framework |
Key Differentiator: xbase's event loop is intentionally minimal — it provides the essential primitives (I/O, timers, signals, thread-pool offload) without buffered I/O, DNS resolution, or HTTP parsing. This makes it ideal as a foundation layer for higher-level libraries (like xhttp) rather than a standalone application framework.
Benchmark
Environment: Apple M3 Pro, 36 GB RAM, macOS 26.4, Release build (
-O2), kqueue backend. Source:xbase/event_bench.cppFull report:docs/bench/event_loop.md
Core Operations
| Benchmark | Time (ns) | CPU (ns) | Iterations |
|---|---|---|---|
BM_EventLoop_CreateDestroy | 700 | 700 | 974,157 |
BM_EventLoop_WakeLatency | 413 | 413 | 1,717,088 |
BM_EventLoop_PipeAddDel | 1,144 | 1,144 | 612,118 |
- Create/Destroy takes ~700ns — reduced from ~2.8µs after eliminating the wake pipe (no more
pipe()+ two extra fds). - Wake latency is ~413ns per wake+wait cycle via
EVFILT_USER, down from ~879ns with the old pipe mechanism — a 2.1× improvement.
libuv Baseline Comparison
| Dimension | moo | libuv | Ratio |
|---|---|---|---|
| Wake Latency | 413 ns | 417 ns | Tied (moo 1.01× faster) |
| Timer (single) | 461 ns | 1,517 ns | moo 3.3× faster |
| Timer (×1000) | 43,545 ns | 68,659 ns | moo 1.6× faster |
| Offload (single) | 3,785 ns | 3,449 ns | libuv 1.1× faster (tied) |
| Offload (×1000) | 456,426 ns | 218,513 ns | libuv 2.1× faster |
Key Observations:
- Wake latency — Now effectively tied with libuv (413ns vs 417ns) after switching to
EVFILT_USER(kqueue) /eventfd(epoll) + atomic wake coalescing. Previously 2.1× slower. - Timer — moo now wins across all batch sizes thanks to batch-pop with single lock acquisition and timer struct freelist pooling. Previously libuv was 4–5× faster at batch sizes.
- Offload round-trip — libuv remains ~2× faster at scale. The gap has narrowed at small batch sizes thanks to wake coalescing and work item pooling.
timer.h — Monotonic Timer
Introduction
timer.h provides a standalone monotonic timer that schedules callbacks to fire after a delay or at an absolute time. It supports two fire modes — Push mode (dispatch to a thread pool) and Poll mode (enqueue to a lock-free MPSC queue for caller-driven execution) — making it suitable for both multi-threaded and single-threaded architectures.
Note: For timers integrated directly into an event loop, see
xEventLoopTimerAfter()/xEventLoopTimerAt()inevent.h. The standalonetimer.his useful when you need timers without an event loop, or when you want explicit control over which thread executes the callbacks.
Design Philosophy
-
Dual Fire Modes — Push mode hands expired callbacks to a thread pool for concurrent execution; Poll mode queues them for the caller to drain synchronously. This lets latency-sensitive code (e.g., an event loop) avoid thread-switch overhead by polling, while background services can use push mode for simplicity.
-
Dedicated Timer Thread — Each
xTimerinstance spawns one background thread that sleeps on a condition variable, waking only when the earliest deadline arrives or a new entry is submitted. This avoids busy-waiting and keeps CPU usage near zero when idle. -
Min-Heap for O(log n) Scheduling — Timer entries are stored in a min-heap ordered by deadline. Insert, cancel, and fire-next are all O(log n). The heap is provided by
heap.h. -
Lock-Free Poll Queue — In poll mode, expired entries are pushed onto an intrusive MPSC queue (
mpsc.h) without holding the mutex, minimizing contention between the timer thread and the polling thread.
Architecture
sequenceDiagram
participant App
participant Timer as xTimer
participant Thread as Timer Thread
participant Heap as Min-Heap
participant Queue as MPSC Queue
App->>Timer: xTimerCreate(group)
Timer->>Thread: spawn
App->>Timer: xTimerSubmitAfter(fn, 1000ms)
Timer->>Heap: push(entry)
Timer->>Thread: signal(cond)
Thread->>Heap: peek → deadline
Note over Thread: sleep until deadline
Thread->>Heap: pop(entry)
alt Push Mode
Thread->>App: xTaskSubmit(fn)
else Poll Mode
Thread->>Queue: xMpscPush(entry)
App->>Queue: xTimerPoll()
Queue-->>App: callback(arg)
end
Implementation Details
Internal Structure
struct xTimerTask_ {
xMpsc node; // Intrusive MPSC node (poll mode)
uint64_t deadline; // Absolute expiry time (CLOCK_MONOTONIC, ms)
xTimerFunc fn; // User callback
void *arg; // User argument
size_t heap_idx; // Position in min-heap (TIMER_INVALID_IDX when not in heap)
int cancelled; // Set to 1 under mutex before removal
};
struct xTimer_ {
xHeap heap; // Min-heap ordered by deadline
xTaskGroup group; // Non-NULL → push mode; NULL → poll mode
xMpsc *mq_head; // Poll-mode MPSC queue head
xMpsc *mq_tail; // Poll-mode MPSC queue tail
pthread_t thread; // Background timer thread
pthread_mutex_t mu; // Protects heap and stopped flag
pthread_cond_t cond; // Wakes timer thread on new entry or stop
int stopped; // Shutdown flag
};
Timer Thread Loop
The background thread follows this algorithm:
- Wait — If the heap is empty, block on
pthread_cond_wait(). - Check top — Peek at the minimum-deadline entry.
- Fire or sleep — If
deadline ≤ now, pop and fire. Otherwise,pthread_cond_timedwait()until the deadline or a new signal. - Repeat until
stoppedis set.
When a new entry is submitted, pthread_cond_signal() wakes the thread so it can re-evaluate whether the new entry has an earlier deadline.
Push vs. Poll Mode
graph LR
subgraph "Push Mode (group != NULL)"
HEAP_P["Min-Heap"] -->|"pop expired"| FIRE_P["fire()"]
FIRE_P -->|"xTaskSubmit"| POOL["Thread Pool"]
POOL -->|"execute"| CB_P["callback(arg)"]
end
subgraph "Poll Mode (group == NULL)"
HEAP_Q["Min-Heap"] -->|"pop expired"| FIRE_Q["fire()"]
FIRE_Q -->|"xMpscPush"| MPSC["MPSC Queue"]
MPSC -->|"xTimerPoll()"| CB_Q["callback(arg)"]
end
style POOL fill:#4a90d9,color:#fff
style MPSC fill:#f5a623,color:#fff
Cancellation
xTimerCancel() acquires the mutex, checks if the entry is still in the heap (not already fired or cancelled), removes it via xHeapRemove(), marks it cancelled, and frees the memory. If the entry has already fired, xErrno_Cancelled is returned.
Memory Ownership
- Push mode: The timer thread transfers ownership of the
xTimerTask_to the worker thread viaxTaskSubmit(). The worker frees it after executing the callback. - Poll mode: The timer thread pushes the entry to the MPSC queue.
xTimerPoll()pops and frees each entry after executing its callback. - Cancellation: The caller frees the entry immediately.
- Destroy: Remaining heap entries and poll-queue entries are freed without firing.
API Reference
Types
| Type | Description |
|---|---|
xTimerFunc | void (*)(void *arg) — Timer callback signature |
xTimer | Opaque handle to a timer instance |
xTimerTask | Opaque handle to a submitted timer entry |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xTimerCreate | xTimer xTimerCreate(xTaskGroup g) | Create a timer. g != NULL → push mode, g == NULL → poll mode. | Not thread-safe |
xTimerDestroy | void xTimerDestroy(xTimer t) | Stop the timer thread and free all resources. Pending entries are discarded. | Not thread-safe |
xTimerSubmitAfter | xTimerTask xTimerSubmitAfter(xTimer t, xTimerFunc fn, void *arg, uint64_t delay_ms) | Schedule a callback after a relative delay. | Thread-safe |
xTimerSubmitAt | xTimerTask xTimerSubmitAt(xTimer t, xTimerFunc fn, void *arg, uint64_t abs_ms) | Schedule a callback at an absolute monotonic time. | Thread-safe |
xTimerCancel | xErrno xTimerCancel(xTimer t, xTimerTask task) | Cancel a pending entry. Returns xErrno_Ok if cancelled, xErrno_Cancelled if already fired. | Thread-safe |
xTimerPoll | int xTimerPoll(xTimer t) | Execute all due callbacks (poll mode only). Returns count. No-op in push mode. | Not thread-safe |
xTimerNowMs | uint64_t xTimerNowMs(void) | Deprecated. Use xMonoMs() from <x/base/time.h>. | Thread-safe |
Usage Examples
Push Mode (Thread Pool Dispatch)
#include <stdio.h>
#include <x/base/timer.h>
#include <x/base/task.h>
#include <unistd.h>
static void on_timeout(void *arg) {
printf("Timer fired on worker thread! arg=%p\n", arg);
}
int main(void) {
xTaskGroup group = xTaskGroupCreate(NULL);
xTimer timer = xTimerCreate(group);
// Fire after 500ms on a worker thread
xTimerSubmitAfter(timer, on_timeout, NULL, 500);
sleep(1); // Wait for timer to fire
xTimerDestroy(timer);
xTaskGroupDestroy(group);
return 0;
}
Poll Mode (Event Loop Integration)
#include <stdio.h>
#include <x/base/timer.h>
#include <x/base/time.h>
static void on_timeout(void *arg) {
int *count = (int *)arg;
printf("Timer #%d fired on caller thread\n", ++(*count));
}
int main(void) {
xTimer timer = xTimerCreate(NULL); // Poll mode
int count = 0;
// Schedule 3 timers
xTimerSubmitAfter(timer, on_timeout, &count, 100);
xTimerSubmitAfter(timer, on_timeout, &count, 200);
xTimerSubmitAfter(timer, on_timeout, &count, 300);
// Poll loop
uint64_t start = xMonoMs();
while (xMonoMs() - start < 500) {
int n = xTimerPoll(timer);
if (n > 0) printf(" Polled %d timer(s)\n", n);
usleep(10000); // 10ms
}
xTimerDestroy(timer);
return 0;
}
Use Cases
-
Event Loop Timer Backend — The event loop's builtin timers (
xEventLoopTimerAfter) use the same min-heap approach internally. Use standalonexTimerwhen you need timers independent of an event loop. -
Retry / Backoff Logic — Schedule retries with exponential backoff using
xTimerSubmitAfter(). Cancel pending retries withxTimerCancel()when a response arrives. -
Periodic Health Checks — In poll mode, integrate
xTimerPoll()into your main loop to execute periodic health checks without spawning additional threads.
Best Practices
- Choose the right mode. Use push mode when callbacks are independent and can run concurrently. Use poll mode when callbacks must run on a specific thread (e.g., the event loop thread) or when you want to avoid thread-switch latency.
- Don't use the handle after fire or cancel. Once a timer entry fires or is cancelled, the memory is freed. Accessing the handle is undefined behavior.
- Destroy before the task group. If using push mode, destroy the timer before destroying the task group to ensure all in-flight callbacks complete.
- Prefer
xEventLoopTimerAfter()when using an event loop. It avoids the overhead of a separate timer thread and integrates seamlessly with I/O dispatch.
Comparison with Other Libraries
| Feature | xbase timer.h | timerfd (Linux) | POSIX timer (timer_create) | libuv uv_timer |
|---|---|---|---|---|
| Platform | macOS + Linux | Linux only | POSIX (varies) | Cross-platform |
| Fire Mode | Push (thread pool) or Poll (MPSC) | fd-based (integrates with epoll) | Signal or thread | Event loop callback |
| Resolution | Millisecond (CLOCK_MONOTONIC) | Nanosecond | Nanosecond | Millisecond |
| Data Structure | Min-heap (O(log n)) | Kernel-managed | Kernel-managed | Min-heap |
| Thread Safety | Submit/Cancel are thread-safe | fd operations are thread-safe | Varies | Not thread-safe |
| Cancellation | O(log n) via heap index | timerfd_settime(0) | timer_delete() | uv_timer_stop() |
| Overhead | 1 background thread per xTimer | 1 fd per timer | 1 kernel timer per instance | Shared with event loop |
| Dependencies | heap.h, mpsc.h, task.h | Linux kernel | POSIX RT library | libuv |
Key Differentiator: xbase's timer provides a unique dual-mode design (push/poll) that lets you choose between concurrent execution and single-threaded polling without changing your callback code. The poll mode's lock-free MPSC queue makes it ideal for integration with custom event loops.
Benchmark
Environment: Apple Mac15,7 (12 cores), 36 GB RAM, macOS 26.x, Release build (
-O2). Each result is the median of 3 repetitions. Source:xbase/timer_bench.cpp
| Benchmark | N | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Timer_SubmitCancel | — | 68.7 | 61.0 | — |
BM_Timer_SubmitBatch | 10 | 1,287 | 1,247 | 8.02 M items/s |
BM_Timer_SubmitBatch | 100 | 7,590 | 6,538 | 15.3 M items/s |
BM_Timer_SubmitBatch | 1,000 | 61,647 | 53,211 | 18.8 M items/s |
BM_Timer_FirePoll | 10 | 3,003 | 3,003 | 3.33 M items/s |
BM_Timer_FirePoll | 100 | 16,993 | 15,878 | 6.30 M items/s |
BM_Timer_FirePoll | 1,000 | 172,412 | 153,600 | 6.51 M items/s |
Key Observations:
- Submit+Cancel cycle takes ~61 ns CPU time, down from ~121 ns in the
calloc-based implementation. The improvement comes from swappingcalloc/freeforxSlabMt(see slab.md); the heap push + heap remove are unchanged. - Batch submit throughput scales from ~8 M to ~19 M items/s as batch size grows. Larger batches amortise the per-entry xSlabMt CAS across the heap-push dominated cost.
- Fire+Poll is slower than submit alone because it includes the MPSC queue transfer and callback invocation. At N=1,000 it sustains ~6.5 M timer fires/s.
task.h — N:M Task Model
Introduction
task.h provides a lightweight N:M concurrent task model where N user tasks are multiplexed onto M OS threads managed by a task group (thread pool). It supports lazy thread creation, configurable queue capacity, per-task result retrieval, and a global shared task group for convenience.
Design Philosophy
-
Lazy Thread Spawning — Worker threads are created on-demand when tasks are submitted and no idle thread is available, up to the configured maximum. This avoids pre-allocating threads that may never be used, reducing resource consumption for bursty workloads.
-
Simple Submit/Wait Model — Tasks are submitted with
xTaskSubmit()and optionally awaited withxTaskWait(). This mirrors the future/promise pattern found in higher-level languages, but in pure C with minimal overhead. -
Safe Cancellation —
xTaskCancel()uses a single CAS (compare-and-swap) to atomically transition a queued task to the cancelled state. If the task is still in the queue, the cancel succeeds and the caller can safely release the task's argument. If the task is already running or done, the cancel fails and the caller mustxTaskWait()first. -
Configurable Capacity — The task group can be configured with a maximum thread count and queue capacity. When the queue is full,
xTaskSubmit()returns NULL, giving the caller explicit backpressure. -
Global Shared Group —
xTaskGroupGlobal()provides a lazily-initialized, process-wide task group with default settings (unlimited threads, no queue cap). It's automatically destroyed atatexit(), making it convenient for fire-and-forget usage.
Architecture
graph TD
subgraph "Task Group"
QUEUE["Task Queue (FIFO)"]
W1["Worker Thread 1"]
W2["Worker Thread 2"]
WN["Worker Thread N"]
end
APP["Application"] -->|"xTaskSubmit()"| QUEUE
QUEUE -->|"dequeue"| W1
QUEUE -->|"dequeue"| W2
QUEUE -->|"dequeue"| WN
W1 -->|"done"| RESULT["xTaskWait() → result"]
W2 -->|"done"| RESULT
WN -->|"done"| RESULT
style APP fill:#4a90d9,color:#fff
style QUEUE fill:#f5a623,color:#fff
style RESULT fill:#50b86c,color:#fff
Implementation Details
Internal Structure
struct xTask_ {
xTaskFunc fn; // User function
void *arg; // User argument
xNote note; // 4-byte one-shot completion notification
void *result; // Return value of fn
struct xTaskGroup_ *group; // Back-pointer to owning group
struct xTask_ *next; // Intrusive queue linkage (task queue + TLS freelist)
xMpsc done_link; // Lock-free done-list linkage (xMpsc)
atomic_int state; // QUEUED → RUNNING/CANCELLED → DONE (CAS-based cancel)
};
// sizeof(xTask_) ≈ 48 bytes (down from ~136 bytes with mutex+cond)
struct xTaskGroup_ {
pthread_t *workers; // Dynamic array of worker threads
size_t max_threads; // Upper bound (SIZE_MAX if unlimited)
size_t nthreads; // Currently spawned threads
pthread_mutex_t qlock; // Protects the task queue
pthread_cond_t qcond; // Wakes idle workers
struct xTask_ *qhead, *qtail; // FIFO task queue
size_t qsize, qcap; // Current size and capacity
xMpsc *done_head; // Lock-free MPSC done queue (head)
xMpsc *done_tail; // Lock-free MPSC done queue (tail)
size_t idle; // Number of idle workers
atomic_size_t pending; // Submitted - finished
atomic_size_t done_count; // Tasks completed
pthread_cond_t wcond; // Dedicated cond for xTaskGroupWait()
bool shutdown; // Shutdown flag
};
TLS Freelist
In the common event-loop offload path, xTaskSubmit() (alloc) and xTaskWait() (free) happen on the same thread. A per-thread freelist eliminates malloc/free overhead entirely — zero locks, zero atomics. The task->next pointer is reused as the freelist link (zero extra memory). A per-thread cap of 64 prevents unbounded caching.
static __thread struct {
struct xTask_ *head;
size_t count;
} tl_free = {NULL, 0};
Worker Loop
Each worker thread runs worker_loop():
- Acquire lock and increment
idlecount. - Wait on
qcondwhile the queue is empty and not shutting down. - Dequeue one task, decrement
idle. - CAS state QUEUED → RUNNING — if the CAS fails (task was cancelled), skip execution.
- Execute
task->fn(task->arg)(only if step 4 succeeded). - Push to done queue via
xMpscPush()(lock-free, wait-free for producers). - Signal completion via
xNoteSignal()(atomic store + kernel wake). - Update counters — decrement
pending, signalwcondif all tasks are done.
Task Submission Flow
flowchart TD
SUBMIT["xTaskSubmit(group, fn, arg)"]
CHECK_CAP{"Queue full?"}
ENQUEUE["Enqueue task"]
CHECK_IDLE{"Idle workers > 0?"}
SIGNAL["Signal qcond"]
CHECK_MAX{"nthreads < max?"}
SPAWN["Spawn new worker"]
DONE["Return task handle"]
FAIL["Return NULL"]
SUBMIT --> CHECK_CAP
CHECK_CAP -->|Yes| FAIL
CHECK_CAP -->|No| ENQUEUE
ENQUEUE --> CHECK_IDLE
CHECK_IDLE -->|Yes| SIGNAL
CHECK_IDLE -->|No| CHECK_MAX
CHECK_MAX -->|Yes| SPAWN
CHECK_MAX -->|No| DONE
SPAWN --> SIGNAL
SIGNAL --> DONE
style SUBMIT fill:#4a90d9,color:#fff
style FAIL fill:#e74c3c,color:#fff
style DONE fill:#50b86c,color:#fff
Separate Wait Conditions
The implementation uses two separate condition variables:
qcond— Wakes idle workers when a new task arrives.wcond— WakesxTaskGroupWait()callers when all tasks complete.
Using a single condition variable caused lost wakeups: pthread_cond_signal() could wake an idle worker instead of the GroupWait caller, leaving it blocked forever.
Global Task Group
xTaskGroupGlobal() uses pthread_once for thread-safe lazy initialization. The group is registered with atexit() for automatic cleanup. It uses default configuration (unlimited threads, no queue cap).
API Reference
Types
| Type | Description |
|---|---|
xTaskFunc | void *(*)(void *arg) — Task function signature. Returns a result pointer. |
xTask | Opaque handle to a submitted task |
xTaskGroup | Opaque handle to a task group (thread pool) |
xTaskGroupConf | Configuration struct: nthreads (0 = auto), queue_cap (0 = unbounded) |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xTaskGroupCreate | xTaskGroup xTaskGroupCreate(const xTaskGroupConf *conf) | Create a task group. NULL conf = defaults. | Not thread-safe |
xTaskGroupDestroy | void xTaskGroupDestroy(xTaskGroup g) | Wait for pending tasks, then destroy. | Not thread-safe |
xTaskSubmit | xTask xTaskSubmit(xTaskGroup g, xTaskFunc fn, void *arg) | Submit a task. Returns NULL if queue is full. | Thread-safe |
xTaskWait | xErrno xTaskWait(xTask t, void **result) | Block until task completes. Returns xErrno_Cancelled if the task was cancelled. | Thread-safe |
xTaskCancel | xErrno xTaskCancel(xTask t) | Cancel a queued task. Returns xErrno_Ok on success, xErrno_Busy if already running/done. | Thread-safe |
xTaskGroupWait | xErrno xTaskGroupWait(xTaskGroup g) | Block until all pending tasks complete. | Thread-safe |
xTaskGroupThreads | size_t xTaskGroupThreads(xTaskGroup g) | Return number of spawned worker threads. | Thread-safe (atomic read) |
xTaskGroupPending | size_t xTaskGroupPending(xTaskGroup g) | Return number of pending tasks. | Thread-safe (atomic read) |
xTaskGroupGlobal | xTaskGroup xTaskGroupGlobal(void) | Get the global shared task group (lazy init). | Thread-safe |
Usage Examples
Basic Task Submission
#include <stdio.h>
#include <x/base/task.h>
static void *compute(void *arg) {
int *val = (int *)arg;
*val *= 2;
return val;
}
int main(void) {
xTaskGroup group = xTaskGroupCreate(NULL);
int value = 21;
xTask task = xTaskSubmit(group, compute, &value);
void *result;
xTaskWait(task, &result);
printf("Result: %d\n", *(int *)result); // 42
xTaskGroupDestroy(group);
return 0;
}
Parallel Map
#include <stdio.h>
#include <x/base/task.h>
#define N 8
static void *square(void *arg) {
int *val = (int *)arg;
*val = (*val) * (*val);
return val;
}
int main(void) {
xTaskGroupConf conf = { .nthreads = 4, .queue_cap = 0 };
xTaskGroup group = xTaskGroupCreate(&conf);
int data[N] = {1, 2, 3, 4, 5, 6, 7, 8};
xTask tasks[N];
for (int i = 0; i < N; i++)
tasks[i] = xTaskSubmit(group, square, &data[i]);
// Wait for all
xTaskGroupWait(group);
for (int i = 0; i < N; i++)
printf("data[%d] = %d\n", i, data[i]);
// Clean up task handles
for (int i = 0; i < N; i++)
xTaskWait(tasks[i], NULL);
xTaskGroupDestroy(group);
return 0;
}
Cancelling a Task
#include <stdio.h>
#include <stdlib.h>
#include <x/base/task.h>
static void *process(void *arg) {
int *data = (int *)arg;
printf("Processing: %d\n", *data);
return NULL;
}
int main(void) {
xTaskGroup group = xTaskGroupCreate(NULL);
int *data = (int *)malloc(sizeof(int));
*data = 42;
xTask task = xTaskSubmit(group, process, data);
// Try to cancel — if successful, we can safely free data now.
if (xTaskCancel(task) == xErrno_Ok) {
free(data); // Safe: fn was never called
} else {
// Task is already running — must wait before freeing
xTaskWait(task, NULL);
free(data);
}
xTaskGroupDestroy(group);
return 0;
}
Using the Global Task Group
#include <stdio.h>
#include <x/base/task.h>
static void *work(void *arg) {
printf("Running on global pool: %s\n", (char *)arg);
return NULL;
}
int main(void) {
xTask t = xTaskSubmit(xTaskGroupGlobal(), work, "hello");
xTaskWait(t, NULL);
// No need to destroy the global group
return 0;
}
Use Cases
-
CPU-Bound Parallel Processing — Distribute computation across multiple cores. Use
xTaskGroupWait()to synchronize at barriers. -
Event Loop Offload — The event loop's
xEventLoopSubmit()usesxTaskGroupinternally to run work functions on worker threads, then delivers results back to the loop thread. -
Background I/O — Offload blocking file I/O (e.g.,
fsync, large reads) to a thread pool to keep the main thread responsive.
Best Practices
- Always call
xTaskWait()or letxTaskGroupDestroy()clean up. EachxTaskSubmit()allocates a task struct (from the TLS freelist or malloc). Task memory is reclaimed when the done queue is drained (duringxTaskGroupWait()orxTaskGroupDestroy()). Leaking task handles leaks resources. - Check
xTaskCancel()return value before releasing the arg.xErrno_Okmeans the task will not execute — safe to free.xErrno_Busymeans it's already running or done — you mustxTaskWait()first. - Set
queue_capfor backpressure. Without a cap, unbounded submission can exhaust memory. A bounded queue lets you detect overload via NULL returns fromxTaskSubmit(). - Don't destroy the global group.
xTaskGroupGlobal()is managed internally and destroyed atatexit(). Passing it toxTaskGroupDestroy()is undefined behavior. - Use
xTaskGroupWait()for barriers, not busy-polling. It uses a dedicated condition variable and blocks efficiently.
Comparison with Other Libraries
| Feature | xbase task.h | pthread | C11 threads | GCD (libdispatch) |
|---|---|---|---|---|
| Abstraction | Task (submit/wait) | Thread (create/join) | Thread (create/join) | Block (dispatch_async) |
| Thread Management | Automatic (lazy spawn) | Manual | Manual | Automatic |
| Queue | Built-in FIFO with cap | N/A | N/A | Built-in (serial/concurrent) |
| Result Retrieval | xTaskWait(t, &result) | pthread_join(t, &result) | thrd_join(t, &result) | Completion handler |
| Group Wait | xTaskGroupWait() | Manual barrier | Manual barrier | dispatch_group_wait() |
| Backpressure | queue_cap → NULL on full | N/A | N/A | N/A (unbounded) |
| Global Pool | xTaskGroupGlobal() | N/A | N/A | dispatch_get_global_queue() |
| Platform | macOS + Linux | POSIX | C11 | macOS + Linux (via libdispatch) |
| Dependencies | pthread | OS | OS | OS / libdispatch |
Key Differentiator: xbase's task model provides a simple, portable thread pool with lazy spawning and explicit backpressure — features that require significant boilerplate with raw pthreads. Unlike GCD, it gives you direct control over thread count and queue capacity.
memory.h — Reference-Counted Memory Management
Introduction
memory.h provides a vtable-driven, reference-counted memory management system for C. It enables object lifecycle management (construction, destruction, retain, release, copy, move) through a virtual table pattern, bringing RAII-like semantics to pure C. The XMALLOC(T) macro allocates an object with an embedded header that tracks the reference count and vtable pointer.
Design Philosophy
-
vtable-Driven Lifecycle — Each object type defines a static
xVTablewith optional function pointers forctor,dtor,retain,release,copy, andmove. This decouples lifecycle logic from the allocation mechanism, similar to C++ virtual destructors or Objective-C's class methods. -
Hidden Header Pattern — A
Headerstruct is prepended to every allocation, storing the type name (for debugging), size, reference count, and vtable pointer. The user receives a pointer past the header, so the header is invisible to normal usage. -
Atomic Reference Counting —
xRetain()andxRelease()use atomic operations (__ATOMIC_SEQ_CST) to safely manage reference counts across threads. When the count reaches zero, the destructor is called and memory is freed. -
Macro Convenience —
XMALLOC(T)andXMALLOCEX(T, sz)macros generate the correctxAlloc()call with the type name string, size, and vtable pointer, reducing boilerplate.
Architecture
graph TD
MACRO["XMALLOC(T) / XMALLOCEX(T, sz)"]
ALLOC["xAlloc(name, size, count, vtab)"]
HEADER["Header + Object"]
RETAIN["xRetain(ptr)<br/>atomic refs++"]
RELEASE["xRelease(ptr)<br/>atomic refs--"]
FREE["xFree(ptr)<br/>dtor + free"]
COPY["xCopy(ptr, other)"]
MOVE["xMove(ptr, other)"]
MACRO --> ALLOC
ALLOC --> HEADER
HEADER --> RETAIN
HEADER --> RELEASE
RELEASE -->|"refs == 0"| FREE
HEADER --> COPY
HEADER --> MOVE
style MACRO fill:#4a90d9,color:#fff
style RELEASE fill:#e74c3c,color:#fff
style FREE fill:#e74c3c,color:#fff
Implementation Details
Memory Layout
graph LR
subgraph "malloc'd block"
HDR["Header<br/>name | size | refs | vtab"]
OBJ["User Object<br/>(sizeof(T) bytes)"]
EXTRA["Extra bytes<br/>(XMALLOCEX only)"]
end
PTR["xAlloc() returns →"] --> OBJ
style HDR fill:#f5a623,color:#fff
style OBJ fill:#4a90d9,color:#fff
style EXTRA fill:#50b86c,color:#fff
The actual memory layout:
┌──────────────────────────────────────────────────────┐
│ Header (hidden) │
│ const char *name — type name string (e.g. "Foo") │
│ size_t size — sizeof(T) │
│ size_t refs — reference count (starts at 1) │
│ xVTable *vtab — pointer to static vtable │
├──────────────────────────────────────────────────────┤
│ User Object (returned pointer) │
│ T fields... │
│ [optional extra bytes from XMALLOCEX] │
└──────────────────────────────────────────────────────┘
XMALLOC / XMALLOCEX Macro Expansion
// Given:
typedef struct Foo Foo;
struct Foo { int x; char buf[]; };
XDEF_VTABLE(Foo) { .ctor = FooCtor, .dtor = FooDtor };
XDEF_CTOR(Foo) { self->x = 0; }
XDEF_DTOR(Foo) { /* cleanup */ }
// XMALLOC(Foo) expands to:
(Foo *)xAlloc("Foo", sizeof(Foo), 1, &FooVTable)
// XMALLOCEX(Foo, 128) expands to:
(Foo *)xAlloc("Foo", sizeof(Foo) + 128, 1, &FooVTable)
Reference Count Lifecycle
sequenceDiagram
participant App
participant Alloc as xAlloc
participant Header
participant VTable
App->>Alloc: XMALLOC(Foo)
Alloc->>Header: malloc(sizeof(Header) + sizeof(Foo))
Alloc->>Header: refs = 1
Alloc->>VTable: vtab->ctor(ptr)
Alloc-->>App: Foo *ptr
App->>Header: xRetain(ptr) → refs = 2
App->>Header: xRelease(ptr) → refs = 1
App->>Header: xRelease(ptr) → refs = 0
Header->>VTable: vtab->release(ptr)
Header->>VTable: vtab->dtor(ptr)
Header->>Header: free(hdr)
Thread Safety
xRetain()andxRelease()are thread-safe — they usexAtomicAdd/xAtomicSubwith sequential consistency ordering.xAlloc(),xFree(),xCopy(), andxMove()are not thread-safe — they should be called from a single owner or with external synchronization.
API Reference
Macros
| Macro | Expansion | Description |
|---|---|---|
XDEF_VTABLE(T) | static xVTable TVTable = | Define a static vtable for type T |
XDEF_CTOR(T) | static void TCtor(T *self) | Define a constructor for type T |
XDEF_DTOR(T) | static void TDtor(T *self) | Define a destructor for type T |
XMALLOC(T) | (T *)xAlloc("T", sizeof(T), 1, &TVTable) | Allocate one T with vtable |
XMALLOCEX(T, sz) | (T *)xAlloc("T", sizeof(T) + sz, 1, &TVTable) | Allocate T + extra bytes |
Types
| Type | Description |
|---|---|
xVTable | Struct with function pointers: ctor, dtor, retain, release, copy, move |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xAlloc | void *xAlloc(const char *name, size_t size, size_t count, xVTable *vtab) | Allocate object(s) with header and call ctor. | Not thread-safe |
xFree | void xFree(void *ptr) | Call dtor and free. Ignores NULL. | Not thread-safe |
xRetain | void xRetain(void *ptr) | Increment reference count atomically. Calls vtab->retain if set. | Thread-safe |
xRelease | void xRelease(void *ptr) | Decrement reference count atomically. Calls vtab->release then xFree when refs reach 0. | Thread-safe |
xCopy | void xCopy(void *ptr, void *other) | Call vtab->copy if set. | Not thread-safe |
xMove | void xMove(void *ptr, void *other) | Call vtab->move if set. | Not thread-safe |
Usage Examples
Basic Object with Constructor/Destructor
#include <stdio.h>
#include <string.h>
#include <x/base/memory.h>
typedef struct Connection Connection;
struct Connection {
int fd;
char host[256];
};
XDEF_CTOR(Connection) {
self->fd = -1;
memset(self->host, 0, sizeof(self->host));
printf("Connection created\n");
}
XDEF_DTOR(Connection) {
if (self->fd >= 0) {
// close(self->fd);
printf("Connection closed (fd=%d)\n", self->fd);
}
}
XDEF_VTABLE(Connection) {
.ctor = ConnectionCtor,
.dtor = ConnectionDtor,
};
int main(void) {
Connection *conn = XMALLOC(Connection);
conn->fd = 42;
strcpy(conn->host, "example.com");
xRetain(conn); // refs = 2
xRelease(conn); // refs = 1
xRelease(conn); // refs = 0 → dtor called → freed
return 0;
}
Flexible Array Member with XMALLOCEX
#include <stdio.h>
#include <string.h>
#include <x/base/memory.h>
typedef struct Buffer Buffer;
struct Buffer {
size_t len;
char data[]; // flexible array member
};
XDEF_CTOR(Buffer) { self->len = 0; }
XDEF_DTOR(Buffer) { /* nothing to clean up */ }
XDEF_VTABLE(Buffer) { .ctor = BufferCtor, .dtor = BufferDtor };
int main(void) {
// Allocate Buffer + 1024 extra bytes for data[]
Buffer *buf = XMALLOCEX(Buffer, 1024);
memcpy(buf->data, "Hello, moo!", 12);
buf->len = 12;
printf("Buffer: %.*s\n", (int)buf->len, buf->data);
xRelease(buf); // refs 1 → 0 → freed
return 0;
}
Use Cases
-
Shared Ownership — Multiple components hold references to the same object (e.g., a connection shared between a reader and a writer).
xRetain/xReleaseensures the object is freed only when the last reference is dropped. -
Plugin/Extension Objects — Define vtables for different object types that share a common interface. The vtable pattern enables polymorphic behavior in C.
-
Debug-Friendly Allocation — The
namefield in the header enables allocation tracking and leak detection by type name.
Best Practices
- Always pair
xRetainwithxRelease. Every retain must have a corresponding release, or you'll leak memory. - Use
XMALLOCinstead of rawxAlloc. The macro handles type name, size, and vtable automatically. - Set unused vtable fields to NULL. The implementation checks for NULL before calling each vtable function.
- Don't mix with
free(). Objects allocated withxAllochave a hidden header. Callingfree()directly on the user pointer corrupts the heap. - Use
XMALLOCEXfor flexible array members. It adds extra bytes after the struct for variable-length data.
Comparison with Other Libraries
| Feature | xbase memory.h | C++ RAII | Objective-C ARC | GLib GObject |
|---|---|---|---|---|
| Mechanism | vtable + atomic refcount | Destructor + smart pointers | Compiler-inserted retain/release | GType + refcount |
| Automation | Manual retain/release | Automatic (scope-based) | Automatic (compiler) | Manual ref/unref |
| Thread Safety | Atomic refcount | shared_ptr is atomic | Atomic | Atomic |
| Polymorphism | vtable function pointers | Virtual functions | Method dispatch | Signal/slot + vtable |
| Overhead | 1 header per object (~32 bytes) | 0 (stack) or control block | 1 isa pointer + refcount | Large (GTypeInstance) |
| Flexible Arrays | XMALLOCEX(T, sz) | std::vector | NSMutableData | GArray |
| Debug Info | Type name in header | RTTI | Class name | GType name |
| Language | C99 | C++ | Objective-C | C (with macros) |
Key Differentiator: xbase's memory system brings reference-counted lifecycle management to C with minimal overhead — just a 32-byte header per object. The vtable pattern provides extensibility (custom ctor/dtor/copy/move) without requiring a complex type system like GObject.
Benchmark
Environment: Apple M3 Pro, 36 GB RAM, macOS 26.4, Release build (
-O2). Source:xbase/memory_bench.cpp
| Benchmark | Size (bytes) | Time (ns) | CPU (ns) | Iterations |
|---|---|---|---|---|
BM_Memory_XAlloc | 16 | 23.3 | 23.3 | 29,809,940 |
BM_Memory_XAlloc | 64 | 21.1 | 21.1 | 32,551,024 |
BM_Memory_XAlloc | 256 | 22.4 | 22.4 | 31,207,508 |
BM_Memory_XAlloc | 1,024 | 20.1 | 20.1 | 34,024,352 |
BM_Memory_XAlloc | 4,096 | 24.2 | 24.2 | 29,002,681 |
BM_Memory_Malloc | 16 | 17.5 | 17.5 | 39,883,995 |
BM_Memory_Malloc | 64 | 18.7 | 18.7 | 37,576,831 |
BM_Memory_Malloc | 256 | 19.0 | 19.0 | 34,505,536 |
BM_Memory_Malloc | 1,024 | 23.0 | 23.0 | 30,557,144 |
BM_Memory_Malloc | 4,096 | 17.7 | 17.7 | 39,849,483 |
BM_Memory_RetainRelease | — | 3.90 | 3.90 | 183,068,277 |
Key Observations:
- xAlloc vs malloc overhead is only ~3–5ns across all sizes. The extra cost covers header initialization, vtable setup, and constructor invocation — negligible for most workloads.
- Retain/Release cycle takes ~3.9ns, dominated by the atomic increment/decrement. This is fast enough for hot-path reference counting.
- Allocation time is nearly constant across sizes (16B–4KB), confirming that the overhead is in the header management, not the underlying
malloc.
slab.h — Fixed-Size Object Pool (Slab Allocator)
Introduction
slab.h provides a fixed-size object pool that carves large OS-backed chunks into equally-sized slots and hands them out via an intrusive freelist. It is designed to replace the many small calloc(1, sizeof(T)) / free() call sites scattered throughout xbase where objects are allocated and freed at very high frequency — event sources, timer entries, tree nodes, hash entries, task structs, and so on.
Two variants are provided behind a uniform API shape:
xSlab— single-threaded, zero synchronisation overhead. Use this when the pool is owned by a single thread (e.g. a map backend or an event loop's internal bookkeeping).xSlabMt— multi-threaded. A plain LIFO freelist guarded by a short-held internal spinlock. Use this when allocations and frees may come from different threads (e.g. cross-thread task submission).
Both variants never return individual slots to the OS. Memory is released only when the pool itself is destroyed (or, for xSlab, explicitly reclaimed in bulk via xSlabReset).
Design Philosophy
-
Fixed Slot Size — A pool is parameterised by
(obj_size, obj_align)at create time. Every slot has identical layout, which lets allocation collapse to "pop the head of an intrusive freelist" and deallocation to "push onto that freelist" — both O(1) with zero metadata search. -
Chunk-Backed Growth — When the freelist is empty the pool asks the OS for a contiguous chunk (default 64 KiB, configurable), slices it into slots, and links them into the freelist. Chunks are acquired through the platform's native anonymous mapping facility (
mmapon POSIX,VirtualAllocon Windows) and fall back tomallocwhere neither is available. -
Uninitialised Memory — Slots are returned uninitialised; callers that previously relied on
calloc's zeroing must callmemsetexplicitly. This removes a per-alloc cost that is often wasted when the caller overwrites the fields immediately. -
Configurable Alignment — The default alignment is 16 bytes, which satisfies the requirements of SIMD and common atomic instructions. Callers with stricter requirements (e.g. cache-line alignment for false-sharing mitigation) can pass a larger power-of-two.
-
Spinlock-Guarded Multi-Thread Path —
xSlabMtprotects its freelist with a single short-held spinlock. An earlier lock-free Treiber-stack implementation had an ABA use-after-free hazard: user writes into the handed-out slot could overlap with a preempted popper's stalenextsnapshot, so the CAS could publish a garbage pointer as the new head. Replacing the Treiber stack with a spinlock eliminates the hazard at the cost of mild contention above four threads — a trade-off that is invisible to xbase's actual consumers (timer/task submission) and documented honestly in the benchmark section. -
No Header Per Slot — Unlike general-purpose allocators, the pool stores no per-slot metadata (no size, no cookie). The only per-slot state is the intrusive freelist pointer, which occupies the slot itself while it is free.
Architecture
graph TD
CREATE["xSlabCreate(obj_size, obj_align, chunk_bytes)"]
POOL["xSlab pool<br/>freelist head + chunk list"]
ALLOC["xSlabAlloc(pool)<br/>pop freelist head"]
FREE["xSlabFree(pool, p)<br/>push onto freelist"]
RESET["xSlabReset(pool)<br/>rebuild freelist from chunks"]
DESTROY["xSlabDestroy(pool)<br/>munmap all chunks"]
GROW["grow():<br/>mmap(chunk_bytes)<br/>slice into slots<br/>link into freelist"]
CREATE --> POOL
POOL --> ALLOC
POOL --> FREE
POOL --> RESET
POOL --> DESTROY
ALLOC -.->|"freelist empty"| GROW
GROW --> POOL
style POOL fill:#4a90d9,color:#fff
style ALLOC fill:#50b86c,color:#fff
style FREE fill:#50b86c,color:#fff
style GROW fill:#f5a623,color:#fff
style DESTROY fill:#e74c3c,color:#fff
Implementation Details
Memory Layout
Each chunk is a single OS-backed mapping of at least chunk_bytes rounded up to hold an integral number of slots. Slots are laid out back-to-back at the configured alignment; the chunk header itself is embedded at the start of the mapping and linked into the pool's chunk list for later release.
chunk (64 KiB default)
┌──────────────────────────────────────────────────────────────┐
│ chunk header (next pointer, size) │
├───────┬───────┬───────┬───────┬───────┬───────┬─────┬────────┤
│ slot0 │ slot1 │ slot2 │ slot3 │ slot4 │ ... │ ... │ slotN │
└───┬───┴───┬───┴───┬───┴───┬───┴───┬───┴───────┴─────┴────────┘
│ │ │ │ │
└───────┴───────┴───────┴───────┘ (free slots chained via
first word of each slot)
pool.free_head ─► slotK ─► slotJ ─► ... ─► NULL
A free slot's first word is the pointer to the next free slot (intrusive list). Once handed out, that same word becomes part of the caller's object and can be used freely; on xSlabFree the pool overwrites it again to stitch the slot back into the freelist.
Fast-Path Operations
// xSlabAlloc — single-threaded
if (pool->free_head == NULL) grow(pool);
slot = pool->free_head;
pool->free_head = *(void **)slot;
return slot;
// xSlabFree — single-threaded
*(void **)slot = pool->free_head;
pool->free_head = slot;
xSlabMt performs the same two-instruction sequence inside a spinlock:
// xSlabMt — multi-threaded
spin_lock(&pool->lock);
if (pool->free_head == NULL) grow(pool); // under the same lock
slot = pool->free_head;
pool->free_head = *(void **)slot;
spin_unlock(&pool->lock);
return slot;
The lock also covers grow() (OS mapping + freelist seeding) so only one thread can call into the OS at a time. The spinlock uses xAtomicCasWeak to acquire and xAtomicStore(release) to release.
Lifecycle
sequenceDiagram
participant App
participant Pool as xSlab
participant OS
App->>Pool: xSlabCreate(sizeof(T), 0, 0)
Note over Pool: free_head = NULL, no chunks
App->>Pool: xSlabAlloc()
Pool->>OS: mmap(64 KiB)
OS-->>Pool: chunk base
Note over Pool: slice into slots,<br/>link into freelist
Pool-->>App: slot pointer
App->>Pool: xSlabFree(slot)
Note over Pool: push slot onto<br/>freelist head
App->>Pool: xSlabAlloc() × many
Note over Pool: pops reuse slots<br/>without touching OS
App->>Pool: xSlabDestroy()
Pool->>OS: munmap(each chunk)
Thread Safety
| Function | xSlab | xSlabMt |
|---|---|---|
Create / Destroy | Not thread-safe | Not thread-safe (caller must quiesce) |
Alloc / Free | Not thread-safe | Thread-safe (spinlock-guarded) |
Reset | Not thread-safe | N/A — xSlabMt has no bulk reclaim |
InUse / SlotSize | Not thread-safe read | SlotSize is a constant read, safe after create |
API Reference
Constants
| Macro | Value | Description |
|---|---|---|
XSLAB_DEFAULT_ALIGN | 16 | Default slot alignment when obj_align == 0 |
XSLAB_DEFAULT_CHUNK_BYTES | 64 * 1024 | Default chunk size when chunk_bytes == 0 |
Types
| Type | Description |
|---|---|
xSlab | Opaque handle to a single-threaded pool |
xSlabMt | Opaque handle to a multi-threaded pool |
Functions — xSlab (single-threaded)
| Function | Signature | Description |
|---|---|---|
xSlabCreate | xSlab *xSlabCreate(size_t obj_size, size_t obj_align, size_t chunk_bytes) | Create a pool. 0 selects defaults for align/chunk. Returns NULL on invalid args or OOM. |
xSlabDestroy | void xSlabDestroy(xSlab *s) | Release all chunks. All outstanding slots become invalid. NULL is a no-op. |
xSlabAlloc | void *xSlabAlloc(xSlab *s) | Return one uninitialised slot of obj_size bytes at obj_align. NULL on OOM. |
xSlabFree | void xSlabFree(xSlab *s, void *p) | Return a slot to the pool. NULL is a no-op. The slot must not be touched afterward. |
xSlabReset | void xSlabReset(xSlab *s) | Bulk-reclaim every slot without freeing chunks. Caller must guarantee no slot is live. |
xSlabInUse | size_t xSlabInUse(const xSlab *s) | Number of slots currently handed out. |
xSlabSlotSize | size_t xSlabSlotSize(const xSlab *s) | Configured slot size (after alignment rounding). |
Functions — xSlabMt (multi-threaded)
| Function | Signature | Description |
|---|---|---|
xSlabMtCreate | xSlabMt *xSlabMtCreate(size_t obj_size, size_t obj_align, size_t chunk_bytes) | Create a thread-safe pool. Same parameter semantics as xSlabCreate. |
xSlabMtDestroy | void xSlabMtDestroy(xSlabMt *s) | Release all chunks. Caller must externally quiesce all users first. |
xSlabMtAlloc | void *xSlabMtAlloc(xSlabMt *s) | Thread-safe alloc. Lock-free fast path (CAS on freelist head). |
xSlabMtFree | void xSlabMtFree(xSlabMt *s, void *p) | Thread-safe free. Lock-free fast path. |
xSlabMtSlotSize | size_t xSlabMtSlotSize(const xSlabMt *s) | Configured slot size. |
Usage Examples
Single-threaded: tree node pool
#include <stdlib.h>
#include <string.h>
#include <x/base/slab.h>
typedef struct Node Node;
struct Node {
Node *left, *right;
int key;
void *value;
};
int main(void) {
// One slot per Node, default 16-byte alignment, default 64 KiB chunks.
xSlab *pool = xSlabCreate(sizeof(Node), 0, 0);
Node *root = xSlabAlloc(pool);
memset(root, 0, sizeof(*root)); // slab does not zero
root->key = 42;
// ... manipulate tree, allocate more nodes, free when removing ...
xSlabFree(pool, root);
xSlabDestroy(pool); // releases every chunk at once
return 0;
}
Multi-threaded: cross-thread task structs
#include <x/base/slab.h>
static xSlabMt *g_task_pool;
void task_pool_init(void) {
g_task_pool = xSlabMtCreate(sizeof(struct Task), 0, 0);
}
struct Task *task_alloc(void) {
struct Task *t = xSlabMtAlloc(g_task_pool);
memset(t, 0, sizeof(*t));
return t;
}
void task_free(struct Task *t) {
xSlabMtFree(g_task_pool, t); // safe from any thread
}
void task_pool_shutdown(void) {
xSlabMtDestroy(g_task_pool); // caller must have quiesced all workers
}
Bulk reclaim with xSlabReset
// Event loop shuts down — every event source is about to be destroyed.
// Rather than freeing sources one by one, reset the pool in O(chunks):
xSlabReset(loop->source_pool);
// Pool keeps its chunks, ready to be reused when the loop restarts.
Use Cases
-
High-Frequency Small Allocations — Timer entries, event sources, map nodes, task structs. Anything that used to be a
calloc(1, sizeof(T))in a hot path is a candidate. -
Uniform-Size Containers — A hash/tree map with fixed-size nodes is a perfect fit: every node has the same layout, and deletions recycle through the freelist immediately.
-
Phase-Scoped Arenas via
xSlabReset— When an entire subsystem is torn down,xSlabResetreturns every slot at once without any per-slot bookkeeping. Combined with non-destructive teardown, it enables arena-style lifetimes in C. -
Cross-Thread Object Recycling —
xSlabMtis the right tool when producers on one thread allocate objects that consumers on another thread eventually free. The short-held spinlock avoids the general-purpose allocator's size-class lookup and the bookkeeping overhead of per-thread caches.
Best Practices
- Pick the right variant. If a pool is touched by only one thread, use
xSlab— its fast path is a plain load/store with no synchronisation. Reach forxSlabMtonly when you actually cross threads. - Zero explicitly if you need zeroing. Slots come back uninitialised. Do
memset(p, 0, xSlabSlotSize(pool))if your code previously depended oncalloc. - Match each slot size to one type. Don't mix differently-sized objects in the same pool; create separate pools per type. Slot size is fixed at create time.
- Don't mix with
free(). Slots are carved from a chunk; they are not independently freeable. Always usexSlabFree/xSlabMtFree. - Destroy invalidates everything. After
xSlabDestroy, every slot the pool ever handed out is dangling. Make sure lifetime containment is obvious at the call site. - Reset is a footgun.
xSlabResetdoes not run any destructor — only call it when you are certain every slot is either already cleaned up or safely discardable.
Comparison with Other Approaches
| Feature | xSlab / xSlabMt | malloc / free | Thread-local freelist | C++ std::pmr::pool_resource |
|---|---|---|---|---|
| Slot size | Fixed per pool | Arbitrary | Fixed per freelist | Fixed per pool |
| Alloc fast path | Load + store (ST) / spinlock + load-store (MT) | Size-class lookup + lock | Load + store, but only same thread | Size-class lookup |
| Cross-thread free | xSlabMt supports it | Yes (slow path) | No (must return to origin) | Depends on upstream |
| Per-slot header | None | Typically 8–16 bytes | None | Implementation-defined |
| OS syscall rate | One mmap per chunk (64 KiB) | Many mmap/sbrk depending on impl | None (built on malloc) | Depends on upstream |
| Bulk reclaim | xSlabReset (O(chunks)) | No | No | release() |
| Returns memory to OS | Only on Destroy | Depends on impl | No | On release() |
Key Differentiator: xSlab trades generality (fixed slot size, no per-slot size/type info) for a predictable, extremely cheap fast path and a single munmap per chunk at shutdown. For containers whose nodes are uniform, that trade is almost always worth it.
Benchmark
Environment: Apple Mac15,7 (12 cores), 36 GB RAM, macOS 26.x, Release build (
-O2). Each result is the median of 3 repetitions (--benchmark_min_time=1.0s --benchmark_repetitions=3 --benchmark_report_aggregates_only=true). Source:xbase/slab_bench.cpp
Single-Threaded Alloc + Free
| Benchmark | Time (ns) | Notes |
|---|---|---|
BM_Slab_AllocFree | 2.58 | xSlabAlloc + xSlabFree, 32-byte slots |
BM_Malloc_AllocFree | 18.9 | malloc + free, 32 bytes |
BM_Calloc_AllocFree | 16.9 | calloc + free, 32 bytes |
Single-threaded allocation is ~7.3× faster than malloc and ~6.5× faster than calloc. The slab fast path is a single load + store on the freelist head; malloc must traverse its size-class table and take at least one internal lock even on macOS.
Batched Alloc + Free (Single-Threaded)
| Benchmark | Batch | Time (ns) | Slab vs malloc |
|---|---|---|---|
BM_Slab_Batch | 16 | 37.9 | |
BM_Malloc_Batch | 16 | 287 | slab 7.6× faster |
BM_Slab_Batch | 256 | 590 | |
BM_Malloc_Batch | 256 | 4,409 | slab 7.5× faster |
BM_Slab_Batch | 4,096 | 15,236 | |
BM_Malloc_Batch | 4,096 | 73,612 | slab 4.8× faster |
The gap narrows somewhat at 4K slots because the first chunk (64 KiB / 32 B = 2,048 slots) fills up and a second chunk must be carved — a one-shot mmap cost amortised across the remaining slots. Steady-state performance still matches the single-op numbers above.
Multi-Threaded Alloc + Free
| Threads | xSlabMt (ns) | malloc (ns) | Winner |
|---|---|---|---|
| 1 | 9.79 | 18.8 | slab 1.9× faster |
| 2 | ~80 | 91.3 | roughly tied |
| 4 | 540 | 476 | malloc 1.1× faster |
| 8 | ~1,100 | 46.4 | macOS malloc much faster |
The crossover above four threads is real and worth understanding:
xSlabMtserialises allocations through a single spinlock. With many threads doing nothing but alloc/free in a tight loop the critical section becomes a contention hotspot.- macOS's
malloc(libmalloc's nano zone) maintains per-thread caches that are essentially uncontended up to the small-allocation size class, so 8 threads rarely touch any shared state.
The earlier PR shipped a lock-free Treiber-stack variant that benched a bit faster at four threads but had an ABA hazard around the user-writable first word of a popped slot. The hazard is fundamental to a word-width CAS without a tag, and the spinlock is a clean, portable fix. In practice xSlabMt's usage inside xbase (task/timer/event bookkeeping) allocates at a rate where the lock is rarely contended — timer/task benchmarks elsewhere in these docs still show ~2× gains over the previous malloc/TLS-freelist implementations. If you have a workload with eight or more threads each churning small allocations back-to-back with no other work, put a per-thread cache in front of xSlabMt.
Key Observations:
- Single-threaded allocation is 7× faster than
malloc. This is the primary win; it applies to every map backend, timer heap node, and event-loop bookkeeping struct. - Multi-threaded allocation is faster than
mallocup to ~2 threads and within the same order of magnitude at four. This matches the concurrency envelope of xTask/xTimer under typical xbase workloads, where the downstream wins (SubmitCancel ~2× faster, FanOut throughput ~2× higher) are driven by eliminatingcallocin the submission path rather than by the raw allocator being the fastest at high thread counts. - Zero-init is not free.
BM_Calloc_AllocFreeis ~10% faster thanmallocon macOS because libmalloc short-circuits zeroing for freshly-mmaped pages. For pre-used memory callers should stillmemset. - Bulk
xSlabResetis O(chunks) and can reclaim 64 KiB worth of slots per chunk in a single loop pass — far cheaper than individual frees when tearing a subsystem down.
Integration Status
Within xbase, the following modules have been migrated from calloc to the slab allocator:
| Module | Variant | Slot | Rationale |
|---|---|---|---|
map.c (hash + tree backends) | xSlab | hash entry / tree node | map operations are single-threaded; nodes are uniform-size. |
timer.c | xSlabMt | xTimerTask_ | timer submission is cross-thread; push-mode hands the entry to the task pool. |
task.c | xSlabMt | xTask_ | task structs are freed on worker threads after execution. |
See the respective module documents for benchmarks of the integrated paths.
error.h — Unified Error Codes
Introduction
error.h defines a unified set of error codes (xErrno) used throughout moo. Every function that can fail returns an xErrno value, providing a consistent error handling pattern across all modules. The companion function xstrerror() converts error codes to human-readable strings for logging and debugging.
Design Philosophy
-
Single Error Enum — All moo modules share one error code enum, avoiding the confusion of module-specific error types. This makes error handling uniform: check for
xErrno_Okeverywhere. -
Descriptive Codes — Each error code maps to a specific failure category (invalid argument, out of memory, wrong state, etc.), giving callers enough information to decide how to handle the error without inspecting errno or platform-specific codes.
-
Human-Readable Messages —
xstrerror()returns a static string for each code, suitable for direct inclusion in log messages. It never returns NULL.
Architecture
graph LR
MODULES["All moo Modules"] -->|"return"| ERRNO["xErrno"]
ERRNO -->|"xstrerror()"| MSG["Human-readable string"]
MSG -->|"xLog()"| LOG["Log output"]
style ERRNO fill:#4a90d9,color:#fff
style MSG fill:#50b86c,color:#fff
Implementation Details
Error Code Values
The error codes are defined as an int-based enum (via XDEF_ENUM), starting from 0:
| Code | Value | Meaning |
|---|---|---|
xErrno_Ok | 0 | Success |
xErrno_Unknown | 1 | Unspecified error (legacy / catch-all) |
xErrno_InvalidArg | 2 | NULL or invalid argument |
xErrno_NoMemory | 3 | Memory allocation failed |
xErrno_InvalidState | 4 | Object is in the wrong state for this call |
xErrno_SysError | 5 | Underlying syscall / OS error |
xErrno_NotFound | 6 | Requested item does not exist |
xErrno_AlreadyExists | 7 | Item already registered / bound |
xErrno_Cancelled | 8 | Operation was cancelled |
Usage Pattern
The idiomatic moo error handling pattern:
xErrno err = xSomeFunction(args);
if (err != xErrno_Ok) {
xLog(false, "operation failed: %s", xstrerror(err));
return err; // propagate
}
Internal Usage
xErrno is used by:
- event.h —
xEventMod(),xEventDel(),xEventWake(),xEventLoopTimerCancel(),xEventLoopSubmit(),xEventLoopWorkCancel(),xEventLoopPost(),xEventLoopSignalWatch() - timer.h —
xTimerCancel() - task.h —
xTaskWait(),xTaskCancel(),xTaskGroupWait() - socket.h —
xSocketSetMask(),xSocketSetTimeout() - heap.h —
xHeapPush(),xHeapUpdate()
API Reference
Types
| Type | Description |
|---|---|
xErrno | int-based enum of error codes |
Enum Values
| Value | Description |
|---|---|
xErrno_Ok | Success |
xErrno_Unknown | Unspecified error (legacy / catch-all) |
xErrno_InvalidArg | NULL or invalid argument |
xErrno_NoMemory | Memory allocation failed |
xErrno_InvalidState | Object is in the wrong state for this call |
xErrno_SysError | Underlying syscall / OS error |
xErrno_NotFound | Requested item does not exist |
xErrno_AlreadyExists | Item already registered / bound |
xErrno_Cancelled | Operation was cancelled |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xstrerror | const char *xstrerror(xErrno err) | Return a human-readable error message. Never returns NULL. | Thread-safe (returns static strings) |
Usage Examples
Error Handling Pattern
#include <stdio.h>
#include <x/base/error.h>
#include <x/base/event.h>
int main(void) {
xEventLoop loop = xEventLoopCreate();
if (!loop) {
fprintf(stderr, "Failed to create event loop\n");
return 1;
}
xErrno err = xEventMod(loop, NULL, xEvent_Read);
if (err != xErrno_Ok) {
fprintf(stderr, "xEventMod failed: %s\n", xstrerror(err));
// Output: "xEventMod failed: NULL or invalid argument"
}
xEventLoopDestroy(loop);
return 0;
}
Propagating Errors
#include <x/base/error.h>
#include <x/base/socket.h>
xErrno setup_socket(xEventLoop loop, xSocket *out) {
xSocket sock = xSocketCreate(loop, AF_INET, SOCK_STREAM, 0,
xEvent_Read, my_callback, NULL);
if (!sock) return xErrno_SysError;
xErrno err = xSocketSetTimeout(sock, 5000, 0);
if (err != xErrno_Ok) {
xSocketDestroy(loop, sock);
return err;
}
*out = sock;
return xErrno_Ok;
}
Use Cases
-
Uniform Error Propagation — Functions return
xErrnoand callers check againstxErrno_Ok. This eliminates the need for module-specific error types. -
Logging and Diagnostics —
xstrerror()provides instant human-readable messages for log output without maintaining separate message tables. -
Error Classification — Callers can switch on specific error codes to implement different recovery strategies (e.g., retry on
xErrno_SysError, abort onxErrno_NoMemory).
Best Practices
- Always check return values. Functions that return
xErrnoshould be checked. Functions that return handles (pointers) should be checked for NULL. - Use
xstrerror()in log messages. It's more informative than printing the raw integer. - Don't compare against raw integers. Always use the enum constants (
xErrno_Ok,xErrno_InvalidArg, etc.) for readability and forward compatibility. - Prefer specific codes over
xErrno_Unknown. When adding new error paths, choose the most specific applicable code.
Comparison with Other Libraries
| Feature | xbase error.h | POSIX errno | Windows HRESULT | GLib GError |
|---|---|---|---|---|
| Type | int enum | int (thread-local) | LONG | Struct (domain + code + message) |
| Scope | Library-wide | System-wide | System-wide | Per-domain |
| String Conversion | xstrerror() | strerror() | FormatMessage() | g_error->message |
| Thread Safety | Return value (inherently safe) | Thread-local global | Return value | Heap-allocated |
| Extensibility | Add to enum | Platform-defined | Facility codes | Custom domains |
| Overhead | Zero (int return) | Zero (thread-local) | Zero (int return) | Heap allocation per error |
Key Differentiator: xbase's error system is intentionally simple — a single enum with descriptive codes and a string conversion function. It avoids the complexity of domain-based systems (GError) and the thread-local pitfalls of POSIX errno, while providing enough granularity for library-level error handling.
heap.h — Min-Heap
Introduction
heap.h provides a generic binary min-heap that stores opaque pointers and orders them via a user-supplied comparison function. Each element carries its heap index (maintained via a callback), enabling O(log n) removal and priority updates by index. It is the core data structure behind xbase's timer subsystem.
Design Philosophy
-
Generic via Function Pointers — The heap stores
void *elements and uses axHeapCmpFuncfor ordering. This makes it reusable for any element type without code generation or macros. -
Index Tracking — A
xHeapSetIdxFunccallback notifies elements of their current position in the heap array. This enables O(1) lookup forxHeapRemove()andxHeapUpdate(), which would otherwise require O(n) search. -
Dynamic Array Backend — The heap uses a dynamically-growing array (2x expansion) starting from a default capacity of 16. This provides cache-friendly access patterns and amortized O(1) growth.
-
No Element Ownership — The heap does not own the elements it stores.
xHeapDestroy()frees the heap structure but NOT the elements. This gives the caller full control over element lifecycle.
Architecture
graph TD
PUSH["xHeapPush(elem)"] --> APPEND["Append to data[size]"]
APPEND --> SIFTUP["Sift Up"]
SIFTUP --> NOTIFY["setidx(elem, new_idx)"]
POP["xHeapPop()"] --> SWAP["Swap data[0] with data[size-1]"]
SWAP --> SIFTDOWN["Sift Down from 0"]
SIFTDOWN --> NOTIFY
REMOVE["xHeapRemove(idx)"] --> SWAP2["Swap data[idx] with data[size-1]"]
SWAP2 --> BOTH["Sift Up + Sift Down"]
BOTH --> NOTIFY
style PUSH fill:#4a90d9,color:#fff
style POP fill:#f5a623,color:#fff
style REMOVE fill:#e74c3c,color:#fff
Implementation Details
Data Structure
struct xHeap_ {
void **data; // Dynamic array of element pointers
size_t size; // Current number of elements
size_t cap; // Allocated capacity
xHeapCmpFunc cmp; // Comparison function
xHeapSetIdxFunc setidx; // Index notification callback
};
Array Layout
Index: 0 1 2 3 4 5 6
[min] [ ] [ ] [ ] [ ] [ ] [ ]
│ │ │
│ ├────┤
│ children of 0
├─────┤
parent of 1,2
Parent of i: (i - 1) / 2
Left child of i: 2 * i + 1
Right child of i: 2 * i + 2
Operations and Complexity
| Operation | Function | Time Complexity | Description |
|---|---|---|---|
| Insert | xHeapPush | O(log n) | Append to end, sift up |
| Peek min | xHeapPeek | O(1) | Return data[0] |
| Extract min | xHeapPop | O(log n) | Swap with last, sift down |
| Remove by index | xHeapRemove | O(log n) | Swap with last, sift up + down |
| Update priority | xHeapUpdate | O(log n) | Sift up + down at index |
| Size | xHeapSize | O(1) | Return size field |
| Grow | ensure_cap | Amortized O(1) | 2x realloc |
Sift Operations
- Sift Up — Compare element with parent; swap if smaller. Repeat until heap property is restored or root is reached.
- Sift Down — Compare element with children; swap with the smallest child if it's smaller. Repeat until heap property is restored or a leaf is reached.
Remove by Index
xHeapRemove(h, idx) replaces the element at idx with the last element, then applies both sift-up and sift-down. This handles both cases: the replacement may be smaller (needs to go up) or larger (needs to go down) than its new neighbors.
API Reference
Types
| Type | Description |
|---|---|
xHeapCmpFunc | int (*)(const void *a, const void *b) — Returns negative if a < b, 0 if equal, positive if a > b |
xHeapSetIdxFunc | void (*)(void *elem, size_t idx) — Called when an element's index changes |
xHeap | Opaque handle to a min-heap |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xHeapCreate | xHeap xHeapCreate(xHeapCmpFunc cmp, xHeapSetIdxFunc setidx, size_t cap) | Create a heap. cap = 0 uses default (16). | Not thread-safe |
xHeapDestroy | void xHeapDestroy(xHeap h) | Free the heap. Does NOT free elements. | Not thread-safe |
xHeapPush | xErrno xHeapPush(xHeap h, void *elem) | Insert an element. O(log n). | Not thread-safe |
xHeapPeek | void *xHeapPeek(xHeap h) | Return the minimum element without removing. O(1). | Not thread-safe |
xHeapPop | void *xHeapPop(xHeap h) | Remove and return the minimum element. O(log n). | Not thread-safe |
xHeapRemove | void *xHeapRemove(xHeap h, size_t idx) | Remove element at index. O(log n). | Not thread-safe |
xHeapUpdate | xErrno xHeapUpdate(xHeap h, size_t idx) | Re-heapify after priority change. O(log n). | Not thread-safe |
xHeapSize | size_t xHeapSize(xHeap h) | Return element count. O(1). | Not thread-safe |
Usage Examples
Timer-Style Priority Queue
#include <stdio.h>
#include <stdlib.h>
#include <x/base/heap.h>
typedef struct {
uint64_t deadline;
size_t heap_idx;
char name[32];
} TimerEntry;
static int cmp_entry(const void *a, const void *b) {
const TimerEntry *ea = (const TimerEntry *)a;
const TimerEntry *eb = (const TimerEntry *)b;
if (ea->deadline < eb->deadline) return -1;
if (ea->deadline > eb->deadline) return 1;
return 0;
}
static void set_idx(void *elem, size_t idx) {
((TimerEntry *)elem)->heap_idx = idx;
}
int main(void) {
xHeap heap = xHeapCreate(cmp_entry, set_idx, 0);
TimerEntry entries[] = {
{ .deadline = 300, .name = "C" },
{ .deadline = 100, .name = "A" },
{ .deadline = 200, .name = "B" },
};
for (int i = 0; i < 3; i++)
xHeapPush(heap, &entries[i]);
// Pop in order: A (100), B (200), C (300)
while (xHeapSize(heap) > 0) {
TimerEntry *e = (TimerEntry *)xHeapPop(heap);
printf("%s (deadline=%llu)\n", e->name, e->deadline);
}
xHeapDestroy(heap);
return 0;
}
Use Cases
-
Timer Subsystem —
timer.huses the min-heap to order timer entries by deadline. The timer thread peeks at the minimum to determine how long to sleep, then pops expired entries. -
Event Loop Timers — The event loop's builtin timer heap (
event.h) uses the same pattern to integrate timer dispatch with I/O polling. -
Custom Priority Queues — Any scenario requiring efficient insert/extract-min with O(log n) removal by index.
Best Practices
- Always implement
xHeapSetIdxFunc. Without index tracking,xHeapRemove()andxHeapUpdate()cannot locate elements efficiently. - Store the index in your element struct. The
setidxcallback should write the index into a field of your element (e.g.,elem->heap_idx = idx). - Don't free elements while they're in the heap. Remove them first with
xHeapRemove()orxHeapPop(). - Use
xHeapUpdate()after changing an element's priority. The heap doesn't detect priority changes automatically.
Comparison with Other Libraries
| Feature | xbase heap.h | C++ std::priority_queue | Linux kernel prio_heap | Go container/heap |
|---|---|---|---|---|
| Element Type | void * (generic) | Template | Fixed struct | interface{} |
| Index Tracking | Built-in (setidx callback) | Not available | Not available | Manual (Fix method) |
| Remove by Index | O(log n) | Not supported | Not supported | O(log n) via Remove |
| Update Priority | O(log n) via xHeapUpdate | Not supported | Not supported | O(log n) via Fix |
| Ownership | No (caller owns elements) | Yes (copies/moves) | No | No |
| Thread Safety | Not thread-safe | Not thread-safe | Not thread-safe | Not thread-safe |
Key Differentiator: xbase's heap provides built-in index tracking via the setidx callback, enabling O(log n) removal and priority updates — features that std::priority_queue lacks entirely. This makes it ideal for timer implementations where cancellation is a common operation.
Benchmark
Environment: Apple M3 Pro, 36 GB RAM, macOS 26.4, Release build (
-O2). Source:xbase/heap_bench.cpp
| Benchmark | N | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Heap_Push | 8 | 983 | 987 | 8.1 M items/s |
BM_Heap_Push | 64 | 1,694 | 1,699 | 37.7 M items/s |
BM_Heap_Push | 512 | 8,722 | 8,725 | 58.7 M items/s |
BM_Heap_Push | 4,096 | 56,854 | 56,853 | 72.0 M items/s |
BM_Heap_Pop | 8 | 1,020 | 1,024 | 7.8 M items/s |
BM_Heap_Pop | 64 | 2,807 | 2,809 | 22.8 M items/s |
BM_Heap_Pop | 512 | 26,334 | 26,337 | 19.4 M items/s |
BM_Heap_Pop | 4,096 | 297,382 | 297,325 | 13.8 M items/s |
BM_Heap_Remove | 8 | 1,015 | 1,020 | 7.8 M items/s |
BM_Heap_Remove | 64 | 1,808 | 1,811 | 35.3 M items/s |
BM_Heap_Remove | 512 | 8,914 | 8,903 | 57.5 M items/s |
BM_Heap_Remove | 4,096 | 68,017 | 68,016 | 60.2 M items/s |
Key Observations:
- Push throughput scales well with heap size — amortized cost per element decreases as batch size grows, reaching 72M items/s at N=4096.
- Pop is more expensive than push at large N due to the sift-down operation traversing more levels. At N=4096, pop throughput drops to ~14M items/s.
- Remove (random index removal) performs comparably to push, thanks to the O(log n) index-tracked removal. This validates the
setidxcallback design for timer cancellation workloads.
map.h — Generic Key-Value Map
Introduction
map.h provides a generic associative container that stores opaque key-value pairs and supports multiple backend implementations selected at creation time. Users supply a hash function and an equality function; the map handles collision resolution, resizing, and iteration internally. Three backends are available: separate-chaining hash table, open-addressing hash table, and red-black tree.
Design Philosophy
-
vtable-Driven Polymorphism — All backends share a common
xMapVTabledispatch table. The public API (xMapSet,xMapGet,xMapDel, etc.) forwards calls through function pointers, so callers can switch backends by changing a singlexMapTypeargument without touching any other code. -
Opaque Keys and Values — The map stores
const void *keys andvoid *values. Hash and equality functions are user-supplied, making the map reusable for any key type (strings, integers, structs) without code generation or macros. -
Single-Allocation Construction — The hash and flat backends allocate the struct header and the initial bucket/slot array in one contiguous
calloccall. This reduces allocation overhead and improves cache locality for small maps. -
No Key/Value Ownership — The map does not own the keys or values it stores.
xMapDestroy()frees internal structures but NOT user data. This gives the caller full control over element lifecycle. -
Built-in Hash Helpers — Common hash/equality pairs for C strings (
xMapStrHash/xMapStrEq) and integer keys (xMapIntHash/xMapIntEq) are provided out of the box, covering the two most frequent use cases.
Architecture
graph TD
CREATE["xMapCreate(type, cap, hash, eq)"]
HASH["xMapType_Hash<br/>Separate Chaining"]
FLAT["xMapType_Flat<br/>Open Addressing"]
TREE["xMapType_Tree<br/>Red-Black Tree"]
CREATE -->|"type = Hash"| HASH
CREATE -->|"type = Flat"| FLAT
CREATE -->|"type = Tree"| TREE
API["Public API<br/>Set / Get / Del / Len / Iterate"]
HASH --> VT["xMapVTable dispatch"]
FLAT --> VT
TREE --> VT
VT --> API
style CREATE fill:#4a90d9,color:#fff
style HASH fill:#f5a623,color:#fff
style FLAT fill:#50b86c,color:#fff
style TREE fill:#e74c3c,color:#fff
style API fill:#4a90d9,color:#fff
Internal Dispatch
graph LR
subgraph "xMapBase (common header)"
VTABLE["vtable *"]
HASHFN["hash()"]
EQFN["eq()"]
end
subgraph "xMapVTable"
SET["set()"]
GET["get()"]
DEL["del()"]
LEN["len()"]
ITER["iterate()"]
DESTROY["destroy()"]
end
VTABLE --> SET
VTABLE --> GET
VTABLE --> DEL
VTABLE --> LEN
VTABLE --> ITER
VTABLE --> DESTROY
Every backend struct embeds xMapBase as its first member. The public API casts the opaque xMap handle to xMapBase * to access the vtable, then dispatches to the backend-specific implementation.
Backend Implementations
Hash (Separate Chaining)
┌─────────────────────────────────────────┐
│ xMapHash (single calloc) │
│ base: { vtable, hash, eq } │
│ buckets → ┌──┬──┬──┬──┬──┬──┐ │
│ │ │ │ │ │ │ │ ... │
│ └──┴──┴──┴──┴──┴──┘ │
│ size, cap │
└─────────────────────────────────────────┘
│
▼
┌─────────┐ ┌─────────┐
│ Entry │───▶│ Entry │───▶ NULL
│ key,val │ │ key,val │
└─────────┘ └─────────┘
- Collision resolution: Linked list per bucket.
- Load factor threshold: 75% — triggers 2× resize with full rehash.
- Memory layout: Initial buckets are allocated inline (contiguous with the struct). After the first resize, buckets are a separate allocation.
- Best for: General-purpose use, pointer-heavy keys, high collision tolerance.
Flat (Open Addressing, Linear Probing)
┌─────────────────────────────────────────┐
│ xMapFlat (single calloc) │
│ base: { vtable, hash, eq } │
│ slots → ┌───────┬───────┬───────┐ │
│ │ key │ key │ EMPTY │... │
│ │ val │ val │ │ │
│ │ OCCUP │ OCCUP │ │ │
│ └───────┴───────┴───────┘ │
│ size, cap │
└─────────────────────────────────────────┘
- Collision resolution: Linear probing with tombstone markers for deletion.
- Load factor threshold: 70% — triggers 2× resize (tombstones are discarded during rehash).
- Slot states:
EMPTY(never used),OCCUPIED(active entry),TOMBSTONE(deleted, probe continues). - Memory layout: Initial slots are allocated inline. After the first resize, slots are a separate allocation.
- Best for: Small keys (integers, pointers), cache-friendly sequential access, iteration-heavy workloads.
Tree (Red-Black Tree)
┌───────────┐
│ node(B) │
│ hash=500 │
├─────┬─────┤
│ │ │
┌────▼──┐ ┌▼────────┐
│node(R)│ │ node(R) │
│hash=200│ │ hash=800 │
└───────┘ └──────────┘
- Ordering: Nodes are ordered by 64-bit hash value.
- Hash collisions: When two different keys produce the same hash, the first key is stored in the tree node's primary slot; additional keys are chained in a singly-linked overflow list (
xTreeOverflow). - Deletion optimization: When deleting a primary key that has overflow entries, the first overflow entry is promoted to primary — avoiding an expensive RB-tree fixup.
- No pre-allocation: The
capparameter is ignored; nodes are allocated individually on insert. - Best for: Ordered iteration by hash value, worst-case O(log n) guarantees, workloads where hash table resizing pauses are unacceptable.
Operations and Complexity
| Operation | Hash (avg) | Hash (worst) | Flat (avg) | Flat (worst) | Tree |
|---|---|---|---|---|---|
xMapSet | O(1) | O(n) | O(1) | O(n) | O(log n) |
xMapGet | O(1) | O(n) | O(1) | O(n) | O(log n) |
xMapDel | O(1) | O(n) | O(1) | O(n) | O(log n) |
xMapLen | O(1) | O(1) | O(1) | O(1) | O(1) |
xMapIterate | O(n + cap) | O(n + cap) | O(cap) | O(cap) | O(n) |
xMapCreate | O(cap) | O(cap) | O(cap) | O(cap) | O(1) |
xMapDestroy | O(n + cap) | O(n + cap) | O(cap) | O(cap) | O(n) |
Note: For Hash, iteration visits all buckets (including empty ones). For Flat, iteration visits all slots. Tree iteration is a pure in-order traversal visiting only occupied nodes.
API Reference
Types
| Type | Description |
|---|---|
xMapType | Enum: xMapType_Hash (separate chaining), xMapType_Flat (open addressing), xMapType_Tree (red-black tree) |
xMap | Opaque handle to a map |
xMapHashFunc | uint64_t (*)(const void *key) — Returns a 64-bit hash for the given key |
xMapEqFunc | bool (*)(const void *a, const void *b) — Returns true if two keys are equal |
xMapIterFunc | bool (*)(const void *key, void *val, void *arg) — Iterator callback; return false to stop early |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xMapCreate | xMap xMapCreate(xMapType type, size_t cap, xMapHashFunc hash, xMapEqFunc eq) | Create a map with the specified backend. cap = 0 uses default (16). hash and eq are required. | Not thread-safe |
xMapDestroy | void xMapDestroy(xMap m) | Free the map. Does NOT free user keys/values. NULL is a safe no-op. | Not thread-safe |
xMapSet | xErrno xMapSet(xMap m, const void *key, void *val) | Insert or update a key-value pair. Returns xErrno_Ok or xErrno_NoMemory. | Not thread-safe |
xMapGet | void *xMapGet(xMap m, const void *key) | Look up a value by key. Returns NULL if not found. | Not thread-safe |
xMapDel | void *xMapDel(xMap m, const void *key) | Remove a key-value pair. Returns the removed value, or NULL. | Not thread-safe |
xMapLen | size_t xMapLen(xMap m) | Return the number of entries. O(1). | Not thread-safe |
xMapIterate | void xMapIterate(xMap m, xMapIterFunc fn, void *arg) | Iterate over all entries. Callback returns false to stop early. | Not thread-safe |
Built-in Hash / Equality Helpers
| Function | Description |
|---|---|
xMapStrHash | FNV-1a 64-bit hash for NUL-terminated C strings |
xMapStrEq | strcmp-based equality for C strings |
xMapIntHash | Splitmix64 finalizer for integer keys cast to (void *) |
xMapIntEq | Pointer-value equality for integer keys cast to (void *) |
Usage Examples
String-Keyed Map
#include <stdio.h>
#include <x/base/map.h>
int main(void) {
xMap m = xMapCreate(xMapType_Hash, 0, xMapStrHash, xMapStrEq);
xMapSet(m, "alice", (void *)"engineer");
xMapSet(m, "bob", (void *)"designer");
xMapSet(m, "carol", (void *)"manager");
printf("alice = %s\n", (const char *)xMapGet(m, "alice"));
printf("bob = %s\n", (const char *)xMapGet(m, "bob"));
// Update existing key
xMapSet(m, "alice", (void *)"senior engineer");
printf("alice = %s\n", (const char *)xMapGet(m, "alice"));
// Delete
xMapDel(m, "bob");
printf("bob = %s\n", xMapGet(m, "bob") ? "found" : "not found");
printf("len = %zu\n", xMapLen(m));
xMapDestroy(m);
return 0;
}
Integer-Keyed Map with Iteration
#include <stdio.h>
#include <x/base/map.h>
static bool print_entry(const void *key, void *val, void *arg) {
(void)arg;
printf(" key=%ld val=%ld\n", (long)(intptr_t)key, (long)(intptr_t)val);
return true; // continue iteration
}
int main(void) {
// Use flat map for cache-friendly integer lookups
xMap m = xMapCreate(xMapType_Flat, 0, xMapIntHash, xMapIntEq);
for (int i = 1; i <= 10; i++) {
xMapSet(m, (const void *)(intptr_t)i,
(void *)(intptr_t)(i * i));
}
printf("Entries (%zu):\n", xMapLen(m));
xMapIterate(m, print_entry, NULL);
xMapDestroy(m);
return 0;
}
Choosing a Backend
#include <x/base/map.h>
void example(void) {
// General purpose — good default
xMap hash_map = xMapCreate(xMapType_Hash, 0, xMapStrHash, xMapStrEq);
// Cache-friendly for small integer keys
xMap flat_map = xMapCreate(xMapType_Flat, 0, xMapIntHash, xMapIntEq);
// Ordered iteration, O(log n) worst-case guarantees
xMap tree_map = xMapCreate(xMapType_Tree, 0, xMapStrHash, xMapStrEq);
// ... use them identically via xMapSet/xMapGet/xMapDel ...
xMapDestroy(hash_map);
xMapDestroy(flat_map);
xMapDestroy(tree_map);
}
How to Choose a Backend
| Criteria | Hash | Flat | Tree |
|---|---|---|---|
| Average lookup | O(1) ✅ | O(1) ✅ | O(log n) |
| Worst-case lookup | O(n) | O(n) | O(log n) ✅ |
| Cache locality | Poor (pointer chasing) | Excellent ✅ | Poor (pointer chasing) |
| Iteration speed | Visits empty buckets | Visits empty slots | Visits only entries ✅ |
| Ordered iteration | No | No | Yes (by hash) ✅ |
| Resize pauses | Yes (rehash) | Yes (rehash) | No ✅ |
| Memory overhead | Entry nodes + bucket array | Slot array (inline) ✅ | Node + parent/child pointers |
| Deletion | Free entry node | Tombstone marker | RB fixup or overflow promotion |
| Best for | General purpose | Small keys, hot loops | Ordered access, latency-sensitive |
Rule of thumb: Start with xMapType_Hash. Switch to xMapType_Flat if profiling shows cache misses dominate. Use xMapType_Tree when you need ordered iteration or cannot tolerate resize pauses.
Use Cases
-
Session Management — Store active sessions keyed by session ID (string). The hash backend provides O(1) average lookup for connection dispatch.
-
Configuration Registry — Map string keys to configuration values. The tree backend provides ordered iteration for serialization.
-
Object Caches — Cache computed results keyed by integer IDs. The flat backend's cache-friendly layout minimizes latency for hot-path lookups.
-
Symbol Tables — Compilers and interpreters can use the map to store variable bindings, with string keys and pointer values.
Best Practices
- Always provide both
hashandeq. The map requires both functions; passing NULL for either causesxMapCreateto return NULL. - Use the built-in helpers when possible.
xMapStrHash/xMapStrEqandxMapIntHash/xMapIntEqare well-tested and optimized. - Keys must remain valid while stored. The map stores key pointers, not copies. If you free a key while it's in the map, lookups will read freed memory.
- Don't modify keys in-place. Changing a key's content after insertion will corrupt the map's internal structure (wrong bucket/slot/tree position).
- Pre-size when the count is known. Pass a
caphint toxMapCreateto avoid early resizes. For hash and flat backends, capacity should be a power of 2. - Prefer
xMapType_Hashas the default. It handles the widest range of workloads well. Only switch backends based on profiling data.
Comparison with Other Libraries
| Feature | xbase map.h | C++ std::unordered_map | Go map | GLib GHashTable | uthash |
|---|---|---|---|---|---|
| Language | C99 | C++ | Go | C | C (macros) |
| Key Type | void * (generic) | Template | comparable | gpointer | Struct field |
| Multiple Backends | Hash / Flat / Tree ✅ | Hash only | Hash only | Hash only | Hash only |
| Ordered Iteration | Tree backend ✅ | No (std::map for ordered) | No | No | No |
| Ownership | No (caller owns) | Yes (copies) | Yes (copies) | No | No |
| Thread Safety | Not thread-safe | Not thread-safe | Not thread-safe | Not thread-safe | Not thread-safe |
| Resize Strategy | 2× with rehash | Bucket-based rehash | Incremental | Bucket-based rehash | Bucket-based rehash |
| Intrusive | No | No | No | No | Yes (struct embedding) |
Key Differentiator: xbase's map provides three interchangeable backends behind a single API. Callers can tune the data structure to their workload (cache locality, ordered access, worst-case guarantees) without changing any code beyond the xMapType argument.
Benchmark
Environment: Apple Mac15,7 (12 cores), 36 GB RAM, macOS 26.x, Release build (
-O2). Each result is the median of 3 repetitions (--benchmark_min_time=0.5s --benchmark_repetitions=3). Source:xbase/map_bench.cppThe hash and tree backends allocate nodes through
xSlab(see slab.md); the flat backend uses a single contiguous array and does no per-entry allocation.
Set (Insert)
| Benchmark | N | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Map_Set_Hash | 64 | 4,879 | 4,879 | 13.1 M items/s |
BM_Map_Set_Hash | 512 | 9,027 | 9,027 | 56.7 M items/s |
BM_Map_Set_Hash | 4,096 | 56,781 | 56,779 | 72.1 M items/s |
BM_Map_Set_Hash | 32,768 | 713,860 | 713,810 | 45.9 M items/s |
BM_Map_Set_Flat | 64 | 1,061 | 1,062 | 60.2 M items/s |
BM_Map_Set_Flat | 512 | 5,507 | 5,508 | 93.0 M items/s |
BM_Map_Set_Flat | 4,096 | 48,033 | 48,036 | 85.3 M items/s |
BM_Map_Set_Flat | 32,768 | 689,267 | 689,275 | 47.5 M items/s |
BM_Map_Set_Tree | 64 | 5,265 | 5,268 | 12.1 M items/s |
BM_Map_Set_Tree | 512 | 11,232 | 11,233 | 45.6 M items/s |
BM_Map_Set_Tree | 4,096 | 146,120 | 146,120 | 28.0 M items/s |
BM_Map_Set_Tree | 32,768 | 3,154,728 | 3,154,598 | 10.4 M items/s |
Get (Lookup)
| Benchmark | N | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Map_Get_Hash | 64 | 214 | 214 | 298.7 M items/s |
BM_Map_Get_Hash | 512 | 1,967 | 1,967 | 260.3 M items/s |
BM_Map_Get_Hash | 4,096 | 20,192 | 20,187 | 202.9 M items/s |
BM_Map_Get_Hash | 32,768 | 207,804 | 207,791 | 157.7 M items/s |
BM_Map_Get_Flat | 64 | 243 | 243 | 263.8 M items/s |
BM_Map_Get_Flat | 512 | 2,276 | 2,276 | 224.9 M items/s |
BM_Map_Get_Flat | 4,096 | 22,258 | 22,256 | 184.0 M items/s |
BM_Map_Get_Flat | 32,768 | 256,893 | 256,885 | 127.6 M items/s |
BM_Map_Get_Tree | 64 | 438 | 438 | 146.1 M items/s |
BM_Map_Get_Tree | 512 | 4,829 | 4,829 | 106.0 M items/s |
BM_Map_Get_Tree | 4,096 | 60,687 | 60,687 | 67.5 M items/s |
BM_Map_Get_Tree | 32,768 | 2,600,910 | 2,600,792 | 12.6 M items/s |
Del (Delete)
| Benchmark | N | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Map_Del_Hash | 64 | 1,247 | 1,250 | 51.2 M items/s |
BM_Map_Del_Hash | 512 | 3,366 | 3,371 | 151.9 M items/s |
BM_Map_Del_Hash | 4,096 | 23,818 | 23,814 | 172.0 M items/s |
BM_Map_Del_Hash | 32,768 | 209,060 | 209,018 | 156.8 M items/s |
BM_Map_Del_Flat | 64 | 1,153 | 1,155 | 55.4 M items/s |
BM_Map_Del_Flat | 512 | 3,026 | 3,030 | 169.0 M items/s |
BM_Map_Del_Flat | 4,096 | 21,236 | 21,243 | 192.8 M items/s |
BM_Map_Del_Flat | 32,768 | 270,593 | 268,020 | 122.3 M items/s |
BM_Map_Del_Tree | 64 | 1,788 | 1,791 | 35.7 M items/s |
BM_Map_Del_Tree | 512 | 8,524 | 8,527 | 60.0 M items/s |
BM_Map_Del_Tree | 4,096 | 146,494 | 145,907 | 28.1 M items/s |
BM_Map_Del_Tree | 32,768 | 2,672,192 | 2,672,155 | 12.3 M items/s |
Iterate
| Benchmark | N | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Map_Iterate_Hash | 64 | 128 | 128 | 500.2 M items/s |
BM_Map_Iterate_Hash | 512 | 1,030 | 1,030 | 497.3 M items/s |
BM_Map_Iterate_Hash | 4,096 | 8,436 | 8,436 | 485.5 M items/s |
BM_Map_Iterate_Hash | 32,768 | 169,785 | 169,780 | 193.0 M items/s |
BM_Map_Iterate_Flat | 64 | 120 | 120 | 534.7 M items/s |
BM_Map_Iterate_Flat | 512 | 973 | 973 | 526.0 M items/s |
BM_Map_Iterate_Flat | 4,096 | 7,775 | 7,774 | 526.9 M items/s |
BM_Map_Iterate_Flat | 32,768 | 113,315 | 113,308 | 289.2 M items/s |
BM_Map_Iterate_Tree | 64 | 154 | 154 | 416.7 M items/s |
BM_Map_Iterate_Tree | 512 | 1,235 | 1,235 | 414.4 M items/s |
BM_Map_Iterate_Tree | 4,096 | 10,813 | 10,812 | 378.8 M items/s |
BM_Map_Iterate_Tree | 32,768 | 178,903 | 178,901 | 183.2 M items/s |
Key Observations:
- Flat is fastest for small maps. At N≤512, flat's contiguous array layout beats hash on both insert and iterate, and trades evenly with hash on lookup/delete. It is the right choice when capacity fits in a few cache lines.
- Hash scales better at large N. At N=32K, hash sustains 157.7 M lookups/s vs flat's 127.6 M and tree's 12.6 M — separate-chaining avoids the probe-length blowup that hurts flat as load increases.
- Tree pays for ordering. At N=32K, tree set throughput is 10.4 M items/s (~30× slower than flat). Pick tree only when range scans or predictable worst-case latency matter; its iterate throughput remains strong at small N because the red-black walk stays cache-resident.
- Iteration dominates everywhere. Flat peaks at ~535 M items/s (pure sequential scan), hash ~500 M (bucket hop + chain), tree ~415 M (in-order recursion). Use iterate for bulk scans rather than repeatedly calling
xMapGet. - Large-N drops are real. Both flat and hash lose roughly a third of peak throughput between 4K and 32K entries — this is the L2-to-L3 cache boundary, not an algorithmic issue.
list.h — Doubly-Linked Circular List
Introduction
list.h provides an intrusive doubly-linked circular list, derived from the Linux kernel's include/linux/list.h. Instead of storing payloads inside list nodes, the caller embeds an xList node inside their own struct and uses xContainerOf to recover the enclosing struct. This design avoids dynamic allocation for the list itself and works with any element type without generic macros or function pointers.
Design Philosophy
-
Intrusive Design — The list node (
xList) is embedded inside the user's struct rather than wrapping it. This eliminates per-element heap allocation and makes the list usable for any type without templates orvoid *casts. -
Circular Sentinel — The list head is itself an
xListnode whosenextandprevpoint back to itself when empty. This eliminates special-case branching for head/tail operations — every insertion and deletion follows the same pointer manipulation. -
Inline Implementation — All functions are declared
XCAPI_INLINE, so the entire list implementation lives in the header with no separate.cfile. This gives the compiler full visibility for inlining and constant propagation, yielding zero-overhead list operations. -
Poison Pointers — After removal, a node's
nextandprevare overwritten with sentinel values (0xDEAD/0xBEEF). Accessing a removed node's links will trigger an obvious crash, catching use-after-remove bugs early. -
Safe Iteration Macros —
xListForEachSafeandxListForEachEntrySafestash the next pointer before the current node is visited, allowing deletion during iteration without invalidating the loop.
Architecture
graph TD
INIT["xListInit(head)"] --> CIRCULAR["head ⇄ head<br/>(empty circle)"]
ADD["xListAdd(prev, node)"] --> INSERT["Insert after prev"]
ADDH["xListAddHead(head, node)"] --> INSERTH["Insert at head<br/>(= xListAdd(head, node))"]
ADDT["xListAddTail(head, node)"] --> INSERTT["Insert at tail<br/>(= xListAdd(head→prev, node))"]
ADDB["xListAddBefore(next, node)"] --> INSERTB["Insert before next"]
DEL["xListDel(node)"] --> REMOVE["Unlink + poison"]
EMPTY["xListEmpty(head)"] --> CHECK["head→next == head?"]
CIRCULAR --> ADD
CIRCULAR --> ADDH
CIRCULAR --> ADDT
CIRCULAR --> ADDB
ADD --> DEL
ADDH --> DEL
ADDT --> DEL
ADDB --> DEL
style INIT fill:#4a90d9,color:#fff
style ADD fill:#50b86c,color:#fff
style ADDH fill:#50b86c,color:#fff
style ADDT fill:#50b86c,color:#fff
style ADDB fill:#50b86c,color:#fff
style DEL fill:#e74c3c,color:#fff
style EMPTY fill:#f5a623,color:#fff
Implementation Details
Data Structure
typedef struct xList {
struct xList *next;
struct xList *prev;
} xList;
Circular Layout
Empty list:
┌──────────────┐
│ head │
│ next ──┐ │
│ prev ──┼──┐ │
│ │ │ │
└────────┼──┼───┘
▼ ▼
(self)
List with three nodes:
head ⇄ A ⇄ B ⇄ C ⇄ head
┌─►──────────────────┐
│ ▼
head ──► A ──► B ──► C ──┘
▲ ◄── ◄── ◄── │
└──────────────────────┘
Operations and Complexity
| Operation | Function / Macro | Time Complexity | Description |
|---|---|---|---|
| Initialize | xListInit | O(1) | Set next = prev = head (circular empty) |
| Insert after | xListAdd | O(1) | Link node after a given node |
| Insert at head | xListAddHead | O(1) | Insert node right after the list head |
| Insert at tail | xListAddTail | O(1) | Insert node right before the list head (tail) |
| Insert before | xListAddBefore | O(1) | Link node before a given node |
| Remove | xListDel | O(1) | Unlink node + poison pointers |
| Is empty | xListEmpty | O(1) | Check head->next == head |
| Iterate | xListForEach | O(n) | Forward traversal (raw xList *) |
| Iterate safe | xListForEachSafe | O(n) | Forward traversal with deletion support |
| Iterate entries | xListForEachEntry | O(n) | Forward traversal (struct pointers via xContainerOf) |
| Iterate entries safe | xListForEachEntrySafe | O(n) | Forward traversal with deletion support (struct pointers) |
Pointer Manipulation
Inserting node after prev:
Before: prev ⇄ next
After: prev ⇄ node ⇄ next
next->prev = node;
node->next = next;
node->prev = prev;
prev->next = node;
Removing node:
Before: prev ⇄ node ⇄ next
After: prev ⇄ next (node: 0xDEAD / 0xBEEF)
next->prev = prev;
prev->next = next;
node->next = 0xDEAD;
node->prev = 0xBEEF;
API Reference
Types
| Type | Description |
|---|---|
xList | Doubly-linked list node. Embed in your struct as a member. |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xListInit | void xListInit(xList *head) | Initialize a list head as an empty circular list | Not thread-safe |
xListAdd | void xListAdd(xList *prev, xList *node) | Insert node after prev | Not thread-safe |
xListAddHead | void xListAddHead(xList *head, xList *node) | Insert node at the head of the list (equivalent to xListAdd(head, node)) | Not thread-safe |
xListAddTail | void xListAddTail(xList *head, xList *node) | Insert node at the tail of the list (equivalent to xListAdd(head->prev, node)) | Not thread-safe |
xListAddBefore | void xListAddBefore(xList *next, xList *node) | Insert node before next | Not thread-safe |
xListDel | void xListDel(xList *node) | Remove node from its list and poison its pointers | Not thread-safe |
xListEmpty | bool xListEmpty(xList *head) | Return true if the list is empty | Not thread-safe |
Macros
| Macro | Parameters | Description |
|---|---|---|
xListForEach(pos, head) | pos: iterator (xList *), head: list head | Iterate over raw list nodes |
xListForEachSafe(pos, tmp, head) | pos: iterator, tmp: temp, head: list head | Iterate with safe deletion support |
xListForEachEntry(pos, head, member) | pos: struct pointer iterator, head: list head, member: name of xList field | Iterate over struct entries via xContainerOf |
xListForEachEntrySafe(pos, tmp, head, member) | pos: struct pointer iterator, tmp: temp struct pointer, head: list head, member: name of xList field | Iterate over struct entries with safe deletion support |
Usage Examples
Basic List Operations
#include <stdio.h>
#include <x/base/list.h>
struct Task {
xList list;
int id;
};
int main(void) {
xList head;
xListInit(&head);
struct Task t1 = { .id = 1 };
struct Task t2 = { .id = 2 };
struct Task t3 = { .id = 3 };
/* Append to the end */
xListAddTail(&head, &t1.list);
xListAddTail(&head, &t2.list);
xListAddTail(&head, &t3.list);
/* Iterate: 1, 2, 3 */
struct Task *pos;
xListForEachEntry(pos, &head, list) {
printf("task id = %d\n", pos->id);
}
/* Remove t2 */
xListDel(&t2.list);
/* Iterate: 1, 3 */
xListForEachEntry(pos, &head, list) {
printf("task id = %d\n", pos->id);
}
return 0;
}
Safe Deletion During Iteration
#include <x/base/list.h>
struct Node {
xList list;
int value;
};
void remove_all(xList *head) {
struct Node *pos, *tmp;
xListForEachEntrySafe(pos, tmp, head, list) {
xListDel(&pos->list);
/* pos is now unlinked; safe to free if dynamically allocated */
}
}
Stack (LIFO) with xListAddHead
#include <x/base/list.h>
struct Item {
xList list;
int data;
};
void stack_push(xList *stack, struct Item *item) {
xListAddHead(stack, &item->list); /* insert at head = top of stack */
}
struct Item *stack_pop(xList *stack) {
if (xListEmpty(stack)) return NULL;
xList *first = stack->next;
xListDel(first);
return xContainerOf(first, struct Item, list);
}
Queue (FIFO) with xListAddTail
#include <x/base/list.h>
struct Entry {
xList list;
int data;
};
void queue_push(xList *queue, struct Entry *entry) {
xListAddTail(queue, &entry->list); /* insert at tail */
}
struct Entry *queue_pop(xList *queue) {
if (xListEmpty(queue)) return NULL;
xList *first = queue->next;
xListDel(first);
return xContainerOf(first, struct Entry, list);
}
Use Cases
-
Timer Entry Queue —
timer.hlinks timer entries via an embeddedxListnode for O(1) insertion and removal of timer callbacks. -
Connection List — Async socket implementations can chain active connections in a list, enabling O(1) connect/disconnect without external allocation.
-
Task Scheduling — A thread pool can maintain per-worker task lists using
xListAddHead/xListAddTail/xListDel, withxListForEachEntrySafefor graceful shutdown that drains and cancels pending tasks. -
Event Callback Chains — Multiple listeners on the same event can be linked in a list, each embedding an
xListnode in their handler struct.
Best Practices
- Always use the safe variants when deleting during iteration.
xListForEach/xListForEachEntrywill crash if the current node is deleted mid-loop. UsexListForEachSafe/xListForEachEntrySafeinstead. - Initialize before use. An uninitialized
xListhas indeterminate pointers. Always callxListInit()before any other operation. - Don't re-add a node without removing it first. Adding a node that is already in a list will corrupt both the old and new lists. Call
xListDel()before re-inserting. - Use
xListAddTail(head, ...)for tail insertion. In a circular list,xListAddTailinserts before the head sentinel, appending to the tail in O(1). Similarly, usexListAddHead(head, ...)for head insertion. - Check poison after removal for debugging. After
xListDel(),node->next == 0xDEADsignals a use-after-remove bug if you accidentally access the node's links.
Comparison with Other Libraries
| Feature | xbase list.h | Linux kernel list.h | C++ std::list | GLib GList | utlist |
|---|---|---|---|---|---|
| Style | Intrusive | Intrusive | Non-intrusive | Non-intrusive | Intrusive (macros) |
| Allocation | None (embedded) | None (embedded) | Per-node heap | Per-node heap | None (embedded) |
| Circular | Yes | Yes | No (sentinel node) | No (NULL-terminated) | Optional |
| Head/Tail Helpers | Yes (xListAddHead, xListAddTail) | Yes (list_add, list_add_tail) | Yes (push_front, push_back) | Yes (g_list_append, g_list_prepend) | No |
| Poison Pointers | Yes | Yes | No | No | No |
| Safe Iteration | Yes (macro) | Yes (macro) | Yes (iterator) | Yes (manual) | No |
| Thread Safety | Not thread-safe | Not thread-safe | Not thread-safe | Not thread-safe | Not thread-safe |
| Inline Implementation | Yes (header-only) | Yes (header-only) | No (template instantiation) | No (separate .c) | Yes (macros) |
Key Differentiator: xbase's list follows the same proven intrusive design as the Linux kernel's list.h, adapted for user-space C99 with xContainerOf (equivalent to kernel's container_of). The inline implementation and poison pointers provide zero-overhead operations and early detection of use-after-remove bugs.
array.h — Generic Auto-Growing Array
Introduction
array.h provides a type-erased dynamic array that stores fixed-size elements in contiguous memory. Unlike the intrusive list.h, xArray owns its element storage and manages capacity automatically by doubling when more space is needed.
The array stores elements by value (memcpy'd), so each slot is independently addressable. New slots pushed via xArrayPush() are zero-initialized. Lifecycle callbacks (xArrayCallbacks) let the array automatically manage per-element resources: retain on insertion, release on removal, and equality comparison for lookups.
Typical usage:
xArrayCallbacks cbs = { my_retain, my_release, my_equal };
xArray arr = xArrayCreate(sizeof(MyStruct), 0, &cbs);
MyStruct *slot = (MyStruct *)xArrayPush(&arr);
slot->field = value;
...
size_t idx = xArrayFind(arr, &key);
...
xArrayDestroy(arr);
Design Philosophy
-
Type-Erased Container — The array stores elements as raw bytes of a caller-specified size. Cast to the concrete type on access. This avoids macros, templates, or
void **double-indirection while remaining fully generic. -
Callback-Driven Lifecycle — Optional
retain,release, andequalcallbacks let the array own per-element heap resources (strings, sub-allocations) without the caller tracking them manually. If no callbacks are provided, the array behaves like a plainrealloc-based buffer. -
Opaque Handle —
xArrayis an opaque pointer (XDEF_HANDLE). The internal struct (xArray_) is defined only inarray.c, so callers cannot depend on layout details. Growth may relocate the entire object (header + data), which is whyxArrayPushandxArrayResizetakexArray *arrpand update the handle in place. -
Doubling Growth — When capacity is exhausted, the array doubles its capacity (starting from a default of 8). This yields amortised O(1)
Pushand avoids the O(n) per-insert reallocation of naive strategies. -
Zero-Initialised Slots — Every new element is
memsetto zero before the retain callback fires. This means callers can safely checkslot->ptr != NULLinside a release callback without special handling.
Architecture
graph TD
CREATE["xArrayCreate(elem_size, cap, cbs)"] --> ARR["xArray<br/>(opaque handle)"]
PUSH["xArrayPush(&arr)"] --> GROW["Grow if needed<br/>(double capacity)"]
GROW --> ZERO["Zero-init slot"]
ZERO --> RETAIN["retain callback?"]
RETAIN --> SLOT["Return pointer to slot"]
POP["xArrayPop(arr)"] --> RELEASE1["release callback?"]
RELEASE1 --> SHRINK1["len--"]
RESET["xArrayReset(arr)"] --> RELEASE_ALL["release each element"]
RELEASE_ALL --> LEN_ZERO["len = 0<br/>(cap unchanged)"]
DESTROY["xArrayDestroy(arr)"] --> RELEASE_ALL2["release each element"]
RELEASE_ALL2 --> FREE["free(array)"]
RESIZE["xArrayResize(&arr, n)"] --> GROW2["Grow if n > cap"]
RESIZE --> SHRINK2["Shrink if n < len<br/>(release removed)"]
REMOVE["xArrayRemoveRange(arr, start, count)"] --> RELEASE_RANGE["release [start, start+count)"]
RELEASE_RANGE --> SHIFT["memmove survivors left"]
FIND["xArrayFind(arr, key)"] --> EQUAL["equal callback?"]
EQUAL --> LINEAR["Linear scan"]
ARR --> PUSH
ARR --> POP
ARR --> RESET
ARR --> DESTROY
ARR --> RESIZE
ARR --> REMOVE
ARR --> FIND
style CREATE fill:#4a90d9,color:#fff
style PUSH fill:#50b86c,color:#fff
style POP fill:#e74c3c,color:#fff
style RESET fill:#e74c3c,color:#fff
style DESTROY fill:#e74c3c,color:#fff
style RESIZE fill:#f5a623,color:#fff
style REMOVE fill:#e74c3c,color:#fff
style FIND fill:#f5a623,color:#fff
Implementation Details
Internal Structure
struct xArray_ {
size_t elem_size; /* bytes per element */
size_t len; /* current element count */
size_t cap; /* allocated capacity (elements) */
xArrayCallbacks cbs; /* optional lifecycle callbacks */
char data[]; /* flexible array member */
};
The xArray_ struct is allocated as a single block: malloc(sizeof(xArray_) + cap * elem_size). The data flexible array member stores elements contiguously starting right after the header.
Growth Strategy
When xArrayPush needs more space than the current capacity allows:
- Compute the next power-of-two capacity that satisfies the demand (starting from
ARRAY_DEFAULT_CAP = 8). reallocthe entire block (header + data).- Update the caller's
xArrayhandle via thearrppointer.
This means any pointer obtained from xArrayAt / xArrayData is invalidated by a subsequent xArrayPush or xArrayResize that triggers growth.
Callback Semantics
| Callback | When Called | Element State |
|---|---|---|
retain | After xArrayPush or xArrayResize (growing) | Zero-initialised, before caller fills fields |
release | xArrayPop, xArrayReset, xArrayDestroy, xArrayResize (shrinking), xArrayRemoveRange | Still in its original memory location |
equal | xArrayFind | Read-only comparison |
Important: The release callback is invoked before the element's memory is overwritten or freed. This allows the callback to extract and free any heap-owned sub-resources the element holds.
Operations and Complexity
| Operation | Function | Time Complexity | Description |
|---|---|---|---|
| Create | xArrayCreate | O(1) | Allocate header + initial data buffer |
| Destroy | xArrayDestroy | O(n) | Release each element + free block |
| Reset | xArrayReset | O(n) | Release each element, keep capacity |
| Push | xArrayPush | Amortised O(1) | Append + grow if needed |
| Pop | xArrayPop | O(1) | Release last + decrement length |
| Resize | xArrayResize | O(n) | Grow or shrink to exact length |
| Remove range | xArrayRemoveRange | O(n) | Release range + memmove survivors |
| Element access | xArrayAt | O(1) | Pointer arithmetic into data |
| Length | xArrayLen | O(1) | Read len field |
| Capacity | xArrayCap | O(1) | Read cap field |
| Raw data | xArrayData | O(1) | Return pointer to first element |
| Find | xArrayFind | O(n) | Linear scan with equal callback |
API Reference
Types
| Type | Description |
|---|---|
xArray | Opaque handle to a dynamic array (XDEF_HANDLE). |
xArrayCallbacks | Struct with optional retain, release, and equal callbacks. |
xArrayRetainFunc | Callback type: void (*)(void *elem). Called when an element is added. |
xArrayReleaseFunc | Callback type: void (*)(void *elem). Called when an element is removed. |
xArrayEqualFunc | Callback type: int (*)(const void *elem, const void *key). Called by xArrayFind. |
Lifecycle Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xArrayCreate | xArray xArrayCreate(size_t elem_size, size_t initial_cap, const xArrayCallbacks *cbs) | Create a new array. elem_size must be > 0. initial_cap of 0 uses default (8). cbs may be NULL. | Not thread-safe |
xArrayDestroy | void xArrayDestroy(xArray arr) | Release all elements and free the array. NULL is a no-op. | Not thread-safe |
xArrayReset | void xArrayReset(xArray arr) | Release all elements but keep the allocated storage for reuse. | Not thread-safe |
Mutator Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xArrayPush | void *xArrayPush(xArray *arrp) | Append a zero-initialised element. May realloc (updates *arrp). Returns pointer to new slot, or NULL on failure. | Not thread-safe |
xArrayPop | xErrno xArrayPop(xArray arr) | Remove the last element (calls release). Returns xErrno_InvalidState if empty. | Not thread-safe |
xArrayResize | xErrno xArrayResize(xArray *arrp, size_t new_len) | Set exact length. Growing zero-inits + retain new slots; shrinking releases removed slots. | Not thread-safe |
xArrayRemoveRange | xErrno xArrayRemoveRange(xArray arr, size_t start, size_t count) | Remove elements in [start, start+count). Releases each, then shifts survivors left. | Not thread-safe |
Accessor Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xArrayAt | void *xArrayAt(xArray arr, size_t idx) | Pointer to element at idx. Returns NULL if out of range. | Not thread-safe |
xArrayLen | size_t xArrayLen(xArray arr) | Number of stored elements. | Not thread-safe |
xArrayCap | size_t xArrayCap(xArray arr) | Current capacity (elements before realloc needed). | Not thread-safe |
xArrayData | void *xArrayData(xArray arr) | Raw pointer to element storage. Valid until next mutation. NULL if empty. | Not thread-safe |
xArrayFind | size_t xArrayFind(xArray arr, const void *key) | Index of first element matching key via equal callback. Returns (size_t)-1 if not found or no equal callback. | Not thread-safe |
Usage Examples
Basic Push / Pop
#include <stdio.h>
#include <x/base/array.h>
int main(void) {
xArray arr = xArrayCreate(sizeof(int), 0, NULL);
/* Push some integers. */
for (int i = 0; i < 5; i++) {
int *slot = (int *)xArrayPush(&arr);
*slot = i * 10;
}
/* arr = [0, 10, 20, 30, 40], len = 5 */
/* Pop the last. */
xArrayPop(arr);
/* arr = [0, 10, 20, 30], len = 4 */
/* Read by index. */
for (size_t i = 0; i < xArrayLen(arr); i++) {
printf("arr[%zu] = %d\n", i, *(int *)xArrayAt(arr, i));
}
xArrayDestroy(arr);
return 0;
}
Owning Heap Strings (Release Callback)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <x/base/array.h>
struct Entry {
char *name;
int value;
};
static void entry_release(void *elem) {
struct Entry *e = (struct Entry *)elem;
free(e->name);
e->name = NULL;
}
int main(void) {
xArrayCallbacks cbs = { NULL, entry_release, NULL };
xArray arr = xArrayCreate(sizeof(struct Entry), 4, &cbs);
/* Push entries that own heap-allocated strings. */
const char *names[] = { "alice", "bob", "carol" };
for (int i = 0; i < 3; i++) {
struct Entry *slot = (struct Entry *)xArrayPush(&arr);
slot->name = strdup(names[i]);
slot->value = i;
}
/* Pop one — entry_release frees the string automatically. */
xArrayPop(arr);
/* Reset — releases remaining entries, keeps capacity. */
xArrayReset(arr);
xArrayDestroy(arr);
return 0;
}
Remove a Range
#include <stdio.h>
#include <x/base/array.h>
int main(void) {
xArray arr = xArrayCreate(sizeof(int), 0, NULL);
for (int i = 0; i < 6; i++) {
int *slot = (int *)xArrayPush(&arr);
*slot = i;
}
/* arr = [0, 1, 2, 3, 4, 5] */
/* Remove elements at indices 2, 3 (range [2, 4)) */
xArrayRemoveRange(arr, 2, 2);
/* arr = [0, 1, 4, 5] */
for (size_t i = 0; i < xArrayLen(arr); i++) {
printf("%d\n", *(int *)xArrayAt(arr, i));
}
/* Output: 0 1 4 5 */
xArrayDestroy(arr);
return 0;
}
Finding Elements (Equal Callback)
#include <stdio.h>
#include <string.h>
#include <x/base/array.h>
struct Item {
int id;
char label[32];
};
static int item_equal(const void *elem, const void *key) {
const struct Item *item = (const struct Item *)elem;
const int *id = (const int *)key;
return item->id == *id;
}
int main(void) {
xArrayCallbacks cbs = { NULL, NULL, item_equal };
xArray arr = xArrayCreate(sizeof(struct Item), 0, &cbs);
struct Item *a = (struct Item *)xArrayPush(&arr);
a->id = 10; strcpy(a->label, "alpha");
struct Item *b = (struct Item *)xArrayPush(&arr);
b->id = 20; strcpy(b->label, "beta");
int key = 20;
size_t idx = xArrayFind(arr, &key);
if (idx != (size_t)-1) {
struct Item *found = (struct Item *)xArrayAt(arr, idx);
printf("Found: id=%d label=%s\n", found->id, found->label);
}
xArrayDestroy(arr);
return 0;
}
Bulk Access with xArrayData
#include <stdio.h>
#include <x/base/array.h>
int main(void) {
xArray arr = xArrayCreate(sizeof(int), 0, NULL);
for (int i = 0; i < 100; i++) {
int *slot = (int *)xArrayPush(&arr);
*slot = i;
}
/* Access the raw buffer for fast iteration. */
int *data = (int *)xArrayData(arr);
size_t len = xArrayLen(arr);
long long sum = 0;
for (size_t i = 0; i < len; i++) {
sum += data[i];
}
printf("Sum of 0..99 = %lld\n", sum);
xArrayDestroy(arr);
return 0;
}
Use Cases
-
Session History — The xagent module stores AI session conversation history in an
xArrayofstruct xAgentSessionMsg_. The release callback frees each message's heap-owned strings (text, tool-use arguments, tool-result output), andxArrayRemoveRangehandles history trimming. -
Query Turn Buffers — The xagent module's
xAgentQuery_uses separatexArrayinstances for inputs, produced output, and pending tool calls. The release callbacks clean up per-element resources when the query is destroyed or reset. -
Timer Entry Queue — A timer subsystem can store active timer entries in an
xArray, usingxArrayRemoveRangeto cancel a batch of timers and the release callback to free timer-specific resources. -
General Dynamic Buffer — Any module that needs a grow-only list of fixed-size records (e.g. accumulated log entries, pending DNS queries) can use
xArraywith no callbacks for plain value storage.
Best Practices
- Always pass
xArray *arrptoxArrayPushandxArrayResize. These functions may reallocate the entire array object, invalidating the old handle. Never store the result ofxArrayAt/xArrayDataacross a Push or Resize call. - Use the release callback instead of manual cleanup. If your elements own heap memory, set a release callback that frees those sub-resources. This makes
xArrayPop,xArrayReset, andxArrayDestroysafe without caller-side loops. - Don't call
xArrayPopon an empty array. It returnsxErrno_InvalidState. CheckxArrayLen(arr) > 0first if the array might be empty. - Avoid retaining pointers across mutations.
xArrayAtandxArrayDatareturn pointers into the internal buffer. Any Push, Resize, or RemoveRange may move memory. Copy the data out if you need it to survive. - Prefer
xArrayResetover Destroy+Create. If you need to empty an array but expect to refill it soon,xArrayResetpreserves the allocated capacity, avoiding a fresh allocation cycle. - Use
xArrayRemoveRangefor front/trailing trims. To remove the first N elements:xArrayRemoveRange(arr, 0, N). To trim from the middle:xArrayRemoveRange(arr, start, count). The function handles release callbacks and memmove internally.
Comparison with Other Libraries
| Feature | xbase array.h | C++ std::vector | GLib GArray | apr_array_header_t (APR) |
|---|---|---|---|---|
| Style | Opaque handle | Template class | Opaque struct | Struct + macros |
| Language | C99 | C++ | C | C |
| Growth Strategy | Double | Implementation-defined (usually double) | Double | Manual (apr_array_push) |
| Element Size | Caller-specified | Template parameter | Caller-specified | Caller-specified |
| Lifecycle Callbacks | Yes (retain/release/equal) | No (RAII per element) | No (clear func) | No |
| Range Removal | xArrayRemoveRange | erase(first, last) | No built-in | No built-in |
| Find | xArrayFind (callback) | std::find (algorithm) | No built-in | No built-in |
| Opaque Handle | Yes | No (header-only template) | Yes | No |
| Thread Safety | Not thread-safe | Not thread-safe | Not thread-safe | Not thread-safe |
Key Differentiator: xbase's array combines the low-level control of a C dynamic array with optional lifecycle callbacks that automate per-element resource management — something GArray and APR arrays lack. The opaque handle design hides layout details and allows growth to relocate the entire object safely via the arrp indirection pattern.
string.h — SDS-Style Dynamic String
Introduction
string.h provides an SDS-style dynamic string (XString) that is fully compatible with all C string functions (printf %s, strcmp, strlen, …). The header (length + capacity) is hidden before the user-facing pointer, so every XString is a char* — zero interop friction.
Inspired by Redis SDS (Simple Dynamic Strings).
Typical usage:
XString s = XStringCreate("hello");
s = XStringAppend(s, " world");
printf("%s (len=%zu)\n", s, XStringLen(s));
size_t pos = XStringFindStr(s, "world");
if (pos != XSTRING_NONE) {
printf("found at index %zu\n", pos);
}
XStringDestroy(s);
Design Philosophy
-
Binary-Compatible with C Strings —
XStringis atypedef char *. Every XString can be passed directly to any C string API without conversion. It is always NUL-terminated. -
Hidden Header — The metadata (length, capacity) lives in a header placed before the user pointer. This means
XStringis indistinguishable from a regularchar*at the call site, yet length queries are O(1). -
Auto-Growing — Append operations automatically reallocate when capacity is exhausted. Callers must use the return value (
s = XStringAppend(s, "x")) because reallocation may move the string. -
Binary-Safe — Embedded NUL bytes are supported.
XStringCreateLenandXStringAppendLentreat the input as raw bytes. Length is tracked explicitly, not viastrlen. -
Dual-Strategy Search —
XStringFinduses naivememcmpfor short patterns (below a threshold) and platformmemmemfor longer ones, balancing call overhead against algorithmic advantage.
Architecture
graph TD
CREATE["XStringCreate(init)"] --> S["XString<br/>(char*)"]
CREATELEN["XStringCreateLen(data, len)"] --> S
APPEND["XStringAppend(s, str)"] --> GROW["Grow if needed"]
APPENDLEN["XStringAppendLen(s, data, len)"] --> GROW
APPENDFMT["XStringAppendFormat(s, fmt, ...)"] --> GROW
GROW --> UPDATE["Return updated pointer"]
FIND["XStringFind(haystack, needle, len)"] --> THRESH{"needle_len < 32?"}
THRESH -->|Yes| NAIVE["Naive memcmp scan"]
THRESH -->|No| MEMMEM["memmem (platform Two-Way)"]
DUP["XStringDup(s)"] --> S
TRUNCATE["XStringTruncate(s, new_len)"] --> S
CLEAR["XStringClear(s)"] --> S
DESTROY["XStringDestroy(s)"] --> FREE["free(header + data)"]
S --> APPEND
S --> APPENDLEN
S --> APPENDFMT
S --> FIND
S --> DUP
S --> TRUNCATE
S --> CLEAR
S --> DESTROY
style CREATE fill:#4a90d9,color:#fff
style CREATELEN fill:#4a90d9,color:#fff
style APPEND fill:#50b86c,color:#fff
style APPENDLEN fill:#50b86c,color:#fff
style APPENDFMT fill:#50b86c,color:#fff
style FIND fill:#f5a623,color:#fff
style DESTROY fill:#e74c3c,color:#fff
Implementation Details
Memory Layout
XStringHeader
┌──────────────┐
│ len (size_t) │
│ cap (size_t) │
└──────────────┘ ← hdr + 1 = user pointer
┌──────────────┐
XString (char*) → │ data … │ ← always NUL-terminated
│ cap + 1 │
└──────────────┘
The XStringHeader is allocated as part of a single malloc block: malloc(sizeof(XStringHeader) + cap + 1). The user receives a pointer to the data area, which is (XStringHeader*)ptr + 1. This layout means:
XStringLen(s)is O(1) — readshdr->lendirectly.scan be passed to anyconst char*API.- The NUL terminator is always written after
lenbytes.
Growth Strategy
When an append exceeds current capacity:
- If current capacity < 1 MB → double the capacity.
- If current capacity ≥ 1 MB → add 1 MB.
- Minimum capacity is
XSTRING_MIN_CAP = 64bytes.
This mirrors the Redis SDS growth policy and provides good amortised O(1) appends without wasting memory on large strings.
Search Strategy
xStringFind uses a threshold-based approach:
| Pattern Length | Algorithm | Rationale |
|---|---|---|
< XSTRING_FIND_THRESHOLD (32) | Naive memcmp scan | Avoids memmem call overhead for short patterns where O(n·m) is negligible. |
≥ XSTRING_FIND_THRESHOLD | Platform memmem | Leverages glibc's Two-Way algorithm (O(n+m) worst case) or equivalent. |
Not-found results return XSTRING_NONE ((size_t)-1), consistent with the ARRAY_NPOS convention used elsewhere in xbase.
Operations and Complexity
| Operation | Function | Time Complexity | Description |
|---|---|---|---|
| Create | xStringCreate | O(n) | Copy init string + allocate header |
| Create (binary) | xStringCreateLen | O(n) | Copy n bytes + allocate header |
| Destroy | xStringDestroy | O(1) | Free the single allocation |
| Duplicate | xStringDup | O(n) | Copy all data into new allocation |
| Append | xStringAppend | Amortised O(n) | May realloc, then memcpy |
| Append (binary) | xStringAppendLen | Amortised O(n) | May realloc, then memcpy |
| Append (format) | xStringAppendFormat | Amortised O(n) | vsnprintf into available space; grow + retry if needed |
| Truncate | xStringTruncate | O(1) | Write NUL, update len |
| Clear | xStringClear | O(1) | Write NUL at index 0, set len = 0 |
| Length | xStringLen | O(1) | Read header field |
| Capacity | xStringCap | O(1) | Read header field |
| Available | xStringAvail | O(1) | cap − len |
| Grow | xStringGrow | O(n) | Pre-allocate, may realloc |
| Shrink to fit | xStringShrinkToFit | O(n) | realloc to exact size |
| Find | xStringFind | O(n·m) or O(n+m) | Threshold-based: naive or memmem |
| Find (C string) | xStringFindStr | O(n·m) or O(n+m) | Delegates to xStringFind |
| Compare | xStringCmp | O(n) | Binary-safe memcmp |
| Equal | xStringEq | O(n) | xStringCmp == 0 |
API Reference
Types and Constants
| Type / Constant | Description |
|---|---|
xString | typedef char *. SDS-style dynamic string, compatible with all C string APIs. |
XSTRING_NONE | ((size_t)-1). Sentinel returned by xStringFind / xStringFindStr when the needle is not found. |
Lifecycle Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xStringCreate | xString xStringCreate(const char *init) | Create from C string. init may be NULL (→ empty). | Not thread-safe |
xStringCreateLen | xString xStringCreateLen(const void *init, size_t len) | Create from raw memory (binary-safe). init may be NULL if len == 0. | Not thread-safe |
xStringDestroy | void xStringDestroy(xString s) | Free the string. NULL is a no-op. | Not thread-safe |
xStringDup | xString xStringDup(const xString s) | Deep copy. NULL → NULL. | Not thread-safe |
Append Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xStringAppend | xString xStringAppend(xString s, const char *append) | Append C string. May realloc; use return value. | Not thread-safe |
xStringAppendLen | xString xStringAppendLen(xString s, const void *append, size_t len) | Append raw bytes (binary-safe). | Not thread-safe |
xStringAppendFormat | xString xStringAppendFormat(xString s, const char *fmt, ...) | Append printf-style formatted string. | Not thread-safe |
Truncate / Clear
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xStringTruncate | void xStringTruncate(xString s, size_t new_len) | Shorten to new_len. No-op if new_len > len. Does not shrink allocation. | Not thread-safe |
xStringClear | void xStringClear(xString s) | Reset to empty string "". Does not shrink allocation. | Not thread-safe |
Accessor Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xStringLen | size_t xStringLen(const xString s) | String length in O(1). NULL → 0. | Not thread-safe |
xStringCap | size_t xStringCap(const xString s) | Allocated capacity. NULL → 0. | Not thread-safe |
xStringAvail | size_t xStringAvail(const xString s) | Available space = cap − len. NULL → 0. | Not thread-safe |
Memory Control Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xStringGrow | xString xStringGrow(xString s, size_t add_len) | Pre-allocate for add_len more bytes. Does not change length. | Not thread-safe |
xStringShrinkToFit | xString xStringShrinkToFit(xString s) | Realloc to fit content exactly. On failure, keeps original allocation. | Not thread-safe |
Search Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xStringFind | size_t xStringFind(const xString haystack, const char *needle, size_t needle_len) | Binary-safe search. Returns byte index or XSTRING_NONE. | Not thread-safe |
xStringFindStr | size_t xStringFindStr(const xString haystack, const char *needle) | C string search. Equivalent to xStringFind(haystack, needle, strlen(needle)). Returns byte index or XSTRING_NONE. | Not thread-safe |
Comparison Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xStringCmp | int xStringCmp(const xString s1, const xString s2) | Binary-safe comparison. Returns <0, 0, >0. NULL sorts before non-NULL. | Not thread-safe |
xStringEq | int xStringEq(const xString s1, const xString s2) | Returns non-zero if equal. NULL == NULL is true. | Not thread-safe |
Usage Examples
Basic Create / Append / Destroy
#include <stdio.h>
#include <x/base/string.h>
int main(void) {
xString s = xStringCreate("hello");
s = xStringAppend(s, " world");
printf("%s (len=%zu, cap=%zu)\n", s, xStringLen(s), xStringCap(s));
/* Output: hello world (len=11, cap=64) */
xStringDestroy(s);
return 0;
}
Binary-Safe String (Embedded NUL)
#include <stdio.h>
#include <x/base/string.h>
int main(void) {
char data[] = { 'a', 'b', 'c', '\0', 'd', 'e', 'f' };
xString s = xStringCreateLen(data, 7);
printf("len=%zu\n", xStringLen(s)); /* len=7, NOT 3 */
size_t pos = xStringFind(s, "def", 3);
if (pos != XSTRING_NONE) {
printf("found 'def' at index %zu\n", pos); /* found 'def' at index 4 */
}
xStringDestroy(s);
return 0;
}
Formatted Append
#include <stdio.h>
#include <x/base/string.h>
int main(void) {
xString s = xStringCreate("count: ");
s = xStringAppendFormat(s, "%d items", 42);
printf("%s\n", s); /* count: 42 items */
xStringDestroy(s);
return 0;
}
Search with XSTRING_NONE
#include <stdio.h>
#include <x/base/string.h>
int main(void) {
xString s = xStringCreate("the quick brown fox");
size_t pos = xStringFindStr(s, "brown");
if (pos != XSTRING_NONE) {
printf("'brown' at index %zu\n", pos); /* 'brown' at index 10 */
}
pos = xStringFindStr(s, "cat");
if (pos == XSTRING_NONE) {
printf("'cat' not found\n");
}
xStringDestroy(s);
return 0;
}
Pre-allocation and Shrink
#include <stdio.h>
#include <x/base/string.h>
int main(void) {
xString s = xStringCreate("hello");
/* Pre-allocate 1 KB to avoid repeated reallocs. */
s = xStringGrow(s, 1024);
printf("avail=%zu\n", xStringAvail(s)); /* >= 1024 */
s = xStringAppend(s, " world");
s = xStringShrinkToFit(s);
printf("cap=%zu, len=%zu\n", xStringCap(s), xStringLen(s));
/* cap=11, len=11 */
xStringDestroy(s);
return 0;
}
Comparison and Equality
#include <stdio.h>
#include <x/base/string.h>
int main(void) {
xString a = xStringCreate("abc");
xString b = xStringCreate("abc");
xString c = xStringCreate("abd");
printf("a == b: %d\n", xStringEq(a, b)); /* 1 (true) */
printf("a == c: %d\n", xStringEq(a, c)); /* 0 (false) */
printf("a cmp c: %d\n", xStringCmp(a, c)); /* <0 */
xStringDestroy(a);
xStringDestroy(b);
xStringDestroy(c);
return 0;
}
Use Cases
-
Network Protocol Buffers — xString's binary safety and O(1) length make it ideal for building wire-format messages (HTTP headers, WebSocket frames, STUN attributes) where embedded NULs occur and
strlenis unreliable. -
Log Message Assembly —
xStringAppendFormatprovides a convenient way to build structured log lines incrementally, with automatic growth and no fixed-size buffer overflow risk. -
Configuration String Handling — xString can hold user-provided configuration values, supporting both C-string APIs and explicit-length operations.
xStringFindStrenables simple key-value parsing. -
General String Builder — Any module that needs to concatenate multiple strings or formatted output can use xString as a safer, more ergonomic alternative to manual
malloc/realloc/snprintfmanagement.
Best Practices
- Always use the return value from append/grow functions.
s = xStringAppend(s, "x")— the pointer may change after reallocation. The old pointer remains valid on failure, so you can still use it, but the new data won't be appended. - Use
XSTRING_NONEto check search results.if (xStringFindStr(s, "key") != XSTRING_NONE)is clearer and more idiomatic than comparing against(size_t)-1. - Prefer
xStringCreateLenfor binary data.xStringCreateusesstrleninternally and will stop at the first NUL byte.xStringCreateLencopies exactly the bytes you specify. - Use
xStringClearinstead of Destroy+Create for reuse.xStringClearresets to an empty string while preserving the allocated capacity, avoiding a fresh allocation cycle. - Pre-allocate with
xStringGrowfor known sizes. If you know the approximate final size,xStringGrowavoids multiple intermediate reallocations during incremental appends. - Don't store derived pointers across mutations. Pointers obtained from the
xString(e.g.s + offset) are invalidated by any append or grow operation that triggers reallocation.
Comparison with Other Libraries
| Feature | xbase string.h | Redis SDS | C++ std::string | bstring |
|---|---|---|---|---|
| Style | char* typedef | char* typedef | Class | Opaque struct |
| Language | C99 | C | C++ | C |
| C String Compatible | Yes | Yes | No (.c_str()) | No |
| Binary-Safe | Yes | Yes | Yes | Yes |
| O(1) Length | Yes | Yes | Yes | Yes |
| Auto-Growing Append | Yes | Yes | Yes | Yes |
| Formatted Append | xStringAppendFormat | sdscatprintf | std::format_to | No built-in |
| Search | xStringFind (threshold) | strstr only | find() | bfind |
| Thread Safety | Not thread-safe | Not thread-safe | Not thread-safe | Not thread-safe |
Key Differentiator: xString combines Redis SDS's zero-friction char* compatibility with a threshold-based search strategy and printf-style formatted append — a practical middle ground between the minimalism of Redis SDS and the full feature set of C++ std::string.
mpsc.h — Lock-Free MPSC Queue
Introduction
mpsc.h provides a lock-free, intrusive multi-producer single-consumer (MPSC) queue. Multiple threads can push nodes concurrently without locks, while a single consumer thread pops nodes. It is the backbone of xbase's poll-mode timer dispatch and the event loop's offload completion queue.
Design Philosophy
-
Intrusive Design — Nodes embed an
xMpscstruct directly, avoiding heap allocation per enqueue. This is critical for hot paths like timer expiry and offload completion where allocation overhead would be unacceptable. -
Lock-Free Push —
xMpscPush()uses a single atomic exchange (xAtomicXchg) on the tail pointer, making it wait-free for producers. No mutex, no CAS retry loop. -
Single-Consumer Pop —
xMpscPop()is designed for exactly one consumer thread. It uses atomic loads and a single CAS for the edge case of popping the last element. This simplification avoids the ABA problem that plagues multi-consumer designs. -
Minimal Memory Ordering — The implementation uses
xAtomicAcqRelfor the exchange andxAtomicAcquire/xAtomicReleasefor loads/stores, providing the minimum ordering needed for correctness without the overhead of sequential consistency.
Architecture
graph LR
P1["Producer 1"] -->|"xMpscPush"| TAIL["tail"]
P2["Producer 2"] -->|"xMpscPush"| TAIL
P3["Producer 3"] -->|"xMpscPush"| TAIL
HEAD["head"] -->|"xMpscPop"| C["Consumer"]
subgraph "Queue"
HEAD --> N1["Node 1"] --> N2["Node 2"] --> N3["Node 3"]
N3 --- TAIL
end
style P1 fill:#4a90d9,color:#fff
style P2 fill:#4a90d9,color:#fff
style P3 fill:#4a90d9,color:#fff
style C fill:#50b86c,color:#fff
Implementation Details
Data Structure
XDEF_STRUCT(xMpsc) {
xMpsc *volatile next; // Pointer to next node
};
The queue is represented by two external pointers:
head— Points to the oldest node (consumer reads from here)tail— Points to the newest node (producers append here)
Push Algorithm
void xMpscPush(xMpsc **head, xMpsc **tail, xMpsc *node) {
node->next = NULL;
xMpsc *prev_tail = xAtomicXchg(tail, node, xAtomicAcqRel);
if (prev_tail)
prev_tail->next = node; // Link to previous tail
else
xAtomicStore(head, node, xAtomicRelease); // First node
}
The key insight: xAtomicXchg atomically replaces the tail and returns the old value. If the old tail was non-NULL, we link it to the new node. If it was NULL (empty queue), we also update the head.
Pop Algorithm
The pop operation handles three cases:
- Empty queue —
headis NULL, return NULL. - Multiple nodes — Advance
headtohead->next, return old head. - Single node — CAS
tailto NULL. If CAS succeeds, also CASheadto NULL. If CAS fails (concurrent push in progress), spin untilhead->nextbecomes non-NULL.
flowchart TD
START["xMpscPop()"]
CHECK_HEAD{"head == NULL?"}
EMPTY["Return NULL"]
CHECK_NEXT{"head->next == NULL?"}
MULTI["Advance head<br/>Return old head"]
CAS_TAIL{"CAS tail → NULL?"}
CAS_HEAD["CAS head → NULL<br/>Return old head"]
SPIN["Spin until head->next != NULL"]
ADVANCE["Advance head<br/>Return old head"]
START --> CHECK_HEAD
CHECK_HEAD -->|Yes| EMPTY
CHECK_HEAD -->|No| CHECK_NEXT
CHECK_NEXT -->|No| MULTI
CHECK_NEXT -->|Yes| CAS_TAIL
CAS_TAIL -->|Success| CAS_HEAD
CAS_TAIL -->|Fail: concurrent push| SPIN
SPIN --> ADVANCE
style EMPTY fill:#e74c3c,color:#fff
style MULTI fill:#50b86c,color:#fff
style CAS_HEAD fill:#50b86c,color:#fff
style ADVANCE fill:#50b86c,color:#fff
Memory Ordering Analysis
| Operation | Ordering | Reason |
|---|---|---|
xAtomicXchg(tail, node) | AcqRel | Acquire: see previous tail's next field. Release: make node visible to consumer. |
xAtomicStore(head, node) | Release | Make the new head visible to the consumer. |
xAtomicLoad(head) | Acquire | See the node written by the producer. |
xAtomicLoad(&head->next) | Acquire | See the next pointer written by the producer. |
xAtomicCasStrong(tail, ...) | Release | Publish the NULL tail to concurrent pushers. |
Thread Safety
xMpscPush()— Thread-safe (multiple producers).xMpscPop()— Single-consumer only. Must not be called concurrently.xMpscEmpty()— Thread-safe (atomic load).
API Reference
Types
| Type | Description |
|---|---|
xMpsc | Intrusive queue node. Embed in your struct and use xContainerOf() to recover the enclosing struct. |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xMpscPush | void xMpscPush(xMpsc **head, xMpsc **tail, xMpsc *node) | Push a node. Wait-free for producers. | Thread-safe (multi-producer) |
xMpscPop | xMpsc *xMpscPop(xMpsc **head, xMpsc **tail) | Pop the oldest node. Returns NULL if empty. | Single-consumer only |
xMpscEmpty | bool xMpscEmpty(xMpsc **head) | Check if the queue is empty. | Thread-safe |
Usage Examples
Basic Producer-Consumer
#include <stdio.h>
#include <pthread.h>
#include <x/base/mpsc.h>
#include <x/base/base.h>
typedef struct {
xMpsc node; // Must embed xMpsc
int value;
} Message;
static xMpsc *g_head = NULL;
static xMpsc *g_tail = NULL;
static void *producer(void *arg) {
Message *msg = (Message *)arg;
xMpscPush(&g_head, &g_tail, &msg->node);
return NULL;
}
int main(void) {
Message msgs[] = {
{ .value = 1 },
{ .value = 2 },
{ .value = 3 },
};
// Push from multiple threads
pthread_t threads[3];
for (int i = 0; i < 3; i++)
pthread_create(&threads[i], NULL, producer, &msgs[i]);
for (int i = 0; i < 3; i++)
pthread_join(threads[i], NULL);
// Pop from single consumer
xMpsc *node;
while ((node = xMpscPop(&g_head, &g_tail)) != NULL) {
Message *msg = xContainerOf(node, Message, node);
printf("Received: %d\n", msg->value);
}
return 0;
}
Use Cases
-
Timer Poll Mode —
timer.huses the MPSC queue in poll mode to pass expired timer entries from the timer thread to the polling thread without locks. -
Event Loop Offload — The event loop's offload mechanism (
event.h) uses an MPSC queue to deliver completed work items from worker threads to the event loop thread. -
xlog Async Logger —
logger.huses the MPSC queue to pass log messages from application threads to the logger's flush thread.
Best Practices
- Embed
xMpscin your struct. Don't allocatexMpscnodes separately. UsexContainerOf()to recover the enclosing struct after popping. - Initialize head and tail to NULL. An empty queue has both pointers set to NULL.
- Only one thread may call
xMpscPop(). The single-consumer constraint is fundamental to the algorithm's correctness. Violating it causes data races. - Don't access a node after pushing it. Once pushed, the node is owned by the queue until popped.
Comparison with Other Libraries
| Feature | xbase mpsc.h | Dmitry Vyukov MPSC | concurrentqueue (C++) | Linux llist |
|---|---|---|---|---|
| Design | Intrusive, lock-free | Intrusive, lock-free | Non-intrusive, lock-free | Intrusive, lock-free |
| Push | Wait-free (1 atomic xchg) | Wait-free (1 atomic xchg) | Lock-free (CAS loop) | Wait-free (1 atomic xchg) |
| Pop | Lock-free (single consumer) | Lock-free (single consumer) | Lock-free (multi-consumer) | Batch pop (splice) |
| Memory Ordering | AcqRel / Acquire / Release | SeqCst | Relaxed + fences | Varies |
| Allocation | None (intrusive) | None (intrusive) | Per-element (internal) | None (intrusive) |
| Multi-Consumer | No | No | Yes | No (batch only) |
| Language | C99 | C/C++ | C++11 | C (kernel) |
Key Differentiator: xbase's MPSC queue is minimal and intrusive — zero allocation overhead, wait-free push, and carefully chosen memory orderings. It's designed specifically for the single-consumer patterns found in event loops and timer systems.
Benchmark
Environment: Apple M3 Pro, 36 GB RAM, macOS 26.4, Release build (
-O2). Source:xbase/mpsc_bench.cpp
| Benchmark | Time (ns) | CPU (ns) | Iterations | Throughput |
|---|---|---|---|---|
BM_Mpsc_SingleProducer | 3,712 | 3,712 | 187,897 | 275.9 M items/s |
BM_Mpsc_MultiProducer/2 | 609,432 | 87,797 | 8,075 | 227.8 M items/s |
BM_Mpsc_MultiProducer/4 | 1,327,965 | 148,356 | 4,768 | 269.6 M items/s |
BM_Mpsc_MultiProducer/8 | 4,466,805 | 292,260 | 1,000 | 273.7 M items/s |
Key Observations:
- Single-producer push/pop achieves ~276M items/s, demonstrating the minimal overhead of the lock-free algorithm.
- Multi-producer scaling maintains ~270M items/s aggregate throughput even with 8 concurrent producers, showing excellent scalability. The wall-clock time increases due to thread synchronization overhead, but per-CPU throughput remains stable.
- The gap between wall-clock time and CPU time in multi-producer benchmarks reflects the cost of thread creation and barrier synchronization, not the queue operations themselves.
atomic.h — Atomic Operations
Introduction
atomic.h provides a set of macro wrappers over GCC/Clang __atomic builtins, offering portable atomic operations with explicit memory ordering. These macros are used throughout xbase for reference counting (memory.h), lock-free queues (mpsc.h), and event loop internals (event.h).
Design Philosophy
-
Thin Macro Wrappers — Each macro maps directly to a compiler builtin with zero overhead. No abstraction layers, no runtime dispatch.
-
Explicit Memory Ordering — Every atomic operation requires an explicit memory order parameter (
xAtomicAcquire,xAtomicRelease, etc.), forcing the programmer to think about ordering requirements rather than defaulting to the expensiveSeqCst. -
GCC/Clang Builtins — The
__atomicbuiltins are supported by GCC ≥ 4.7 and all versions of Clang. They generate optimal instructions for each target architecture (x86:lockprefix, ARM:ldrex/strexor LSE atomics).
Architecture
graph TD
subgraph "xbase Atomic Users"
MEMORY["memory.h<br/>xRetain / xRelease<br/>(SeqCst refcount)"]
MPSC["mpsc.h<br/>xMpscPush / xMpscPop<br/>(AcqRel / Acquire / Release)"]
EVENT["event_private.h<br/>inflight counter<br/>(Relaxed)"]
TASK["task.c<br/>pending / done_count<br/>(stdatomic)"]
end
subgraph "atomic.h Macros"
LOAD["xAtomicLoad"]
STORE["xAtomicStore"]
XCHG["xAtomicXchg"]
CAS["xAtomicCas*"]
ADD["xAtomicAdd/Sub"]
FETCH["xAtomicFetch*"]
end
MEMORY --> ADD
MPSC --> XCHG
MPSC --> LOAD
MPSC --> STORE
MPSC --> CAS
EVENT --> FETCH
style MEMORY fill:#4a90d9,color:#fff
style MPSC fill:#f5a623,color:#fff
style EVENT fill:#50b86c,color:#fff
Implementation Details
Memory Order Constants
| Macro | Value | Meaning |
|---|---|---|
xAtomicRelaxed | __ATOMIC_RELAXED | No ordering constraints. Only guarantees atomicity. |
xAtomicConsume | __ATOMIC_CONSUME | Data-dependent ordering (rarely used in practice). |
xAtomicAcquire | __ATOMIC_ACQUIRE | Prevents reads/writes from being reordered before this operation. |
xAtomicRelease | __ATOMIC_RELEASE | Prevents reads/writes from being reordered after this operation. |
xAtomicAcqRel | __ATOMIC_ACQ_REL | Combines Acquire and Release. |
xAtomicSeqCst | __ATOMIC_SEQ_CST | Full sequential consistency. Most expensive. |
Operation Macros
Load / Store
| Macro | Expansion | Description |
|---|---|---|
xAtomicLoad(p, o) | __atomic_load_n(p, o) | Atomically read *p |
xAtomicStore(p, v, o) | __atomic_store_n(p, v, o) | Atomically write v to *p |
Exchange / CAS
| Macro | Expansion | Description |
|---|---|---|
xAtomicXchg(p, v, o) | __atomic_exchange_n(p, v, o) | Atomically swap *p with v, return old value |
xAtomicCasWeak(p, e, d, o) | __atomic_compare_exchange_n(p, e, d, true, o, Relaxed) | Weak CAS (may spuriously fail) |
xAtomicCasStrong(p, e, d, o) | __atomic_compare_exchange_n(p, e, d, false, o, Relaxed) | Strong CAS (no spurious failure) |
Note: Both CAS macros use
xAtomicRelaxedas the failure ordering. The success ordering is specified by theoparameter.
Arithmetic
| Macro | Expansion | Returns |
|---|---|---|
xAtomicAdd(p, v, o) | __atomic_add_fetch(p, v, o) | New value (*p + v) |
xAtomicSub(p, v, o) | __atomic_sub_fetch(p, v, o) | New value (*p - v) |
xAtomicFetchAdd(p, v, o) | __atomic_fetch_add(p, v, o) | Old value (before add) |
xAtomicFetchSub(p, v, o) | __atomic_fetch_sub(p, v, o) | Old value (before sub) |
Bitwise
| Macro | Expansion | Returns |
|---|---|---|
xAtomicAnd(p, v, o) | __atomic_and_fetch(p, v, o) | New value |
xAtomicOr(p, v, o) | __atomic_or_fetch(p, v, o) | New value |
xAtomicXor(p, v, o) | __atomic_xor_fetch(p, v, o) | New value |
xAtomicNand(p, v, o) | __atomic_nand_fetch(p, v, o) | New value |
xAtomicFetchAnd(p, v, o) | __atomic_fetch_and(p, v, o) | Old value |
xAtomicFetchOr(p, v, o) | __atomic_fetch_or(p, v, o) | Old value |
xAtomicFetchXor(p, v, o) | __atomic_fetch_xor(p, v, o) | Old value |
API Reference
See the Operation Macros section above for the complete list. All macros are defined in <x/base/atomic.h> and require no function calls — they expand directly to compiler builtins.
Usage Examples
Atomic Counter
#include <stdio.h>
#include <pthread.h>
#include <x/base/atomic.h>
static int g_counter = 0;
static void *increment(void *arg) {
(void)arg;
for (int i = 0; i < 100000; i++) {
xAtomicAdd(&g_counter, 1, xAtomicRelaxed);
}
return NULL;
}
int main(void) {
pthread_t threads[4];
for (int i = 0; i < 4; i++)
pthread_create(&threads[i], NULL, increment, NULL);
for (int i = 0; i < 4; i++)
pthread_join(threads[i], NULL);
printf("Counter: %d\n", xAtomicLoad(&g_counter, xAtomicRelaxed));
// Output: Counter: 400000
return 0;
}
Spinlock (Educational)
#include <x/base/atomic.h>
typedef struct { int locked; } Spinlock;
static inline void spin_lock(Spinlock *s) {
while (xAtomicXchg(&s->locked, 1, xAtomicAcquire) != 0) {
// Spin
}
}
static inline void spin_unlock(Spinlock *s) {
xAtomicStore(&s->locked, 0, xAtomicRelease);
}
Use Cases
-
Reference Counting —
memory.husesxAtomicAdd/xAtomicSubwithSeqCstordering for thread-safe reference count management. -
Lock-Free Data Structures —
mpsc.husesxAtomicXchgfor wait-free push andxAtomicCasStrongfor the single-element pop edge case. -
Event Loop Internals — The event loop uses
xAtomicFetchAdd/xAtomicFetchSubwithRelaxedordering to track in-flight offload workers.
Best Practices
- Use the weakest sufficient ordering.
Relaxedfor simple counters,Acquire/Releasefor producer-consumer patterns,SeqCstonly when you need a total order visible to all threads. - Prefer
xAtomicCasStrongoverxAtomicCasWeakunless you're in a retry loop where spurious failures are acceptable (e.g., lock-free stack push). - Note the CAS failure ordering. Both CAS macros hardcode
xAtomicRelaxedas the failure ordering. If you need stronger failure ordering, use the rawxAtomicCasmacro directly. - Don't mix with C11
<stdatomic.h>. While both use the same underlying compiler builtins, mixing the two styles in the same translation unit can be confusing. xbase uses<stdatomic.h>intask.cforatomic_size_tbutatomic.hmacros everywhere else.
Comparison with Other Libraries
| Feature | xbase atomic.h | C11 <stdatomic.h> | C++ <atomic> | Linux kernel atomics |
|---|---|---|---|---|
| Style | Macros over __atomic builtins | Language-level types | Template class | Inline functions + asm |
| Memory Order | Explicit parameter | Explicit parameter | Explicit parameter | Implicit (varies) |
| Types | Any scalar (via pointer) | _Atomic qualified types | std::atomic<T> | atomic_t, atomic64_t |
| CAS | xAtomicCasWeak/Strong | atomic_compare_exchange_* | compare_exchange_* | cmpxchg |
| Compiler | GCC ≥ 4.7, Clang | C11 | C++11 | GCC (kernel) |
| Portability | GCC/Clang only | Standard C11 | Standard C++11 | Linux kernel only |
Key Differentiator: xbase's atomic macros are the thinnest possible wrapper — they add naming consistency (xAtomic* prefix) and explicit ordering parameters without any abstraction overhead. They work with any scalar type via pointer, unlike C11's _Atomic qualifier which requires type annotations.
log.h — Thread-Local Log Callback
Introduction
log.h provides a per-thread, callback-based logging mechanism for moo's internal error reporting. Each thread can register its own log callback via xLogSetCallback(); when xLog() is called, the formatted message is dispatched to that callback. If no callback is registered, messages fall back to stderr. On fatal errors, a stack backtrace is captured and abort() is called.
Design Philosophy
-
Thread-Local Callbacks — Each thread has its own log callback and userdata, stored in
__thread(thread-local storage). This avoids global locks and allows different threads to route log messages to different destinations (e.g., the xlog async logger, a test harness, or a custom handler). -
Minimal and Non-Allocating —
xLog()formats into a fixed-size thread-local buffer (XLOG_BUF_SIZE, default 512 bytes). No heap allocation occurs during logging, making it safe to call from low-level code paths. -
Fatal with Backtrace — When
fatal = true,xLog()captures a stack trace viaxBacktrace()before callingabort(). This provides immediate diagnostic information for unrecoverable errors. -
Bridge to xlog — The callback mechanism is designed to integrate with the higher-level
xlogmodule. The xlog logger registers itself as the thread's log callback, so internal moo errors are automatically routed through the async logging pipeline.
Architecture
graph TD
subgraph "Thread 1"
LOG1["xLog()"] --> CB1["Custom Callback"]
end
subgraph "Thread 2"
LOG2["xLog()"] --> CB2["xlog Logger"]
end
subgraph "Thread 3 (no callback)"
LOG3["xLog()"] --> STDERR["stderr"]
end
CB1 --> FILE["Log File"]
CB2 --> XLOG["Async Logger Pipeline"]
style LOG1 fill:#4a90d9,color:#fff
style LOG2 fill:#4a90d9,color:#fff
style LOG3 fill:#4a90d9,color:#fff
Implementation Details
Thread-Local State
XDEF_STRUCT(xLogCtx) {
xLogCallback cb; // User callback (NULL = stderr fallback)
void *userdata; // Forwarded to callback
char buf[XLOG_BUF_SIZE]; // Format buffer (512 bytes)
char bt[XLOG_BT_SIZE]; // Backtrace buffer (2048 bytes)
};
static __thread xLogCtx tl_ctx;
Each thread gets ~2.5 KB of thread-local storage for logging. The buffers are reused across calls, so there's no allocation overhead.
xLog() Flow
flowchart TD
CALL["xLog(fatal, fmt, ...)"]
FMT["vsnprintf → tl_ctx.buf"]
CHECK_FATAL{"fatal?"}
BT["xBacktraceSkip(2, bt, size)"]
CHECK_CB{"callback set?"}
CB["cb(msg, backtrace, userdata)"]
STDERR["fprintf(stderr, msg)"]
ABORT["abort()"]
CALL --> FMT
FMT --> CHECK_FATAL
CHECK_FATAL -->|Yes| BT
CHECK_FATAL -->|No| CHECK_CB
BT --> CHECK_CB
CHECK_CB -->|Yes| CB
CHECK_CB -->|No| STDERR
CB --> CHECK_FATAL2{"fatal?"}
STDERR --> CHECK_FATAL2
CHECK_FATAL2 -->|Yes| ABORT
CHECK_FATAL2 -->|No| DONE["Return"]
style ABORT fill:#e74c3c,color:#fff
style DONE fill:#50b86c,color:#fff
Buffer Size Configuration
The format buffer size can be overridden at compile time:
#define XLOG_BUF_SIZE 1024 // Must be defined before #include <x/base/log.h>
#include <x/base/log.h>
API Reference
Macros
| Macro | Default | Description |
|---|---|---|
XLOG_BUF_SIZE | 512 | Format buffer size in bytes. Override before including the header. |
Types
| Type | Description |
|---|---|
xLogCallback | void (*)(const char *msg, const char *backtrace, void *userdata) — Log callback. backtrace is non-NULL only on fatal. |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xLogSetCallback | void xLogSetCallback(xLogCallback cb, void *userdata) | Register (or clear with NULL) the current thread's log callback. | Thread-local (each thread sets its own) |
xLog | void xLog(bool fatal, const char *fmt, ...) | Format and dispatch a log message. If fatal, captures backtrace and calls abort(). | Thread-local (uses calling thread's callback) |
Usage Examples
Basic Logging with Custom Callback
#include <stdio.h>
#include <x/base/log.h>
static void my_log_handler(const char *msg, const char *backtrace,
void *userdata) {
FILE *f = (FILE *)userdata;
fprintf(f, "[MyApp] %s\n", msg);
if (backtrace) {
fprintf(f, "Stack trace:\n%s", backtrace);
}
}
int main(void) {
// Route this thread's logs to a file
FILE *logfile = fopen("app.log", "w");
xLogSetCallback(my_log_handler, logfile);
xLog(false, "Application started, version %d.%d", 1, 0);
xLog(false, "Processing %d items", 42);
// Clear callback (revert to stderr)
xLogSetCallback(NULL, NULL);
xLog(false, "This goes to stderr");
fclose(logfile);
return 0;
}
Fatal Error with Backtrace
#include <x/base/log.h>
void dangerous_operation(void) {
// This will print the message, capture a backtrace, and abort()
xLog(true, "Unrecoverable error: corrupted state detected");
// Never reaches here
}
Use Cases
-
moo Internal Error Reporting — All moo modules use
xLog()to report internal errors (e.g., allocation failures, invalid states). By registering a callback, applications can capture these messages in their logging pipeline. -
xlog Integration — The
xlogmodule registers its logger as the thread's callback viaxLogSetCallback(), routing all internal moo messages through the async logging system. -
Test Frameworks — Test harnesses can register a callback that captures log messages for assertion, rather than letting them go to stderr.
Best Practices
- Register callbacks early. Set up
xLogSetCallback()before calling any moo functions to ensure all messages are captured. - Don't block in callbacks. The callback runs synchronously on the calling thread. Blocking delays the caller. For async logging, use the xlog module.
- Handle NULL backtrace. The
backtraceparameter is NULL for non-fatal messages. Always check before using it. - Be aware of buffer truncation. Messages longer than
XLOG_BUF_SIZEare truncated. Increase the size at compile time if needed.
Comparison with Other Libraries
| Feature | xbase log.h | syslog | fprintf(stderr) | GLib g_log |
|---|---|---|---|---|
| Callback | Per-thread | Global handler | N/A | Global handler |
| Thread Safety | Thread-local (no locks) | Thread-safe (kernel) | Thread-safe (stdio lock) | Thread-safe (global lock) |
| Backtrace | Built-in on fatal | No | No | Optional (G_DEBUG) |
| Allocation | None (stack buffer) | None (kernel) | None (stdio buffer) | Heap (GString) |
| Fatal Handling | abort() with backtrace | N/A | N/A | abort() (G_LOG_FLAG_FATAL) |
| Customization | Per-thread callback | openlog() | Redirect fd | g_log_set_handler() |
Key Differentiator: xbase's log is designed as a lightweight internal error channel, not a full logging framework. Its per-thread callback design avoids global locks and integrates naturally with the xlog async logger for production use.
backtrace.h — Platform-Adaptive Stack Backtrace
Introduction
backtrace.h captures the current call stack and formats it into a human-readable multi-line string. The unwinding backend is selected at build time with the following priority: libunwind > execinfo (macOS/glibc) > stub (unsupported platforms). It is used internally by xLog() to provide stack traces on fatal errors.
Design Philosophy
-
Build-Time Backend Selection — The backend is chosen via CMake-detected macros (
X_HAS_LIBUNWIND,X_HAS_EXECINFO). This avoids runtime overhead and ensures the best available unwinder is used on each platform. -
Graceful Degradation — On platforms without libunwind or execinfo, a stub backend returns a "not supported" message rather than crashing. This ensures
xBacktrace()is always safe to call. -
Automatic Frame Skipping — Internal frames (
xBacktrace→xBacktraceSkip→bt_capture) are automatically skipped so the output starts from the caller's perspective. Theskipparameter allows additional frames to be skipped (useful when called through wrapper functions likexLog). -
Buffer-Based Output — The caller provides a buffer; no heap allocation occurs. This makes it safe to call from signal handlers, fatal error paths, and low-memory situations.
Architecture
graph TD
API["xBacktrace() / xBacktraceSkip()"]
SELECT{"Build-time selection"}
LIBUNWIND["libunwind<br/>unw_step() loop"]
EXECINFO["execinfo<br/>backtrace() + backtrace_symbols()"]
STUB["stub<br/>'not supported' message"]
BUF["User buffer<br/>(formatted output)"]
API --> SELECT
SELECT -->|X_HAS_LIBUNWIND| LIBUNWIND
SELECT -->|X_HAS_EXECINFO| EXECINFO
SELECT -->|fallback| STUB
LIBUNWIND --> BUF
EXECINFO --> BUF
STUB --> BUF
style LIBUNWIND fill:#50b86c,color:#fff
style EXECINFO fill:#4a90d9,color:#fff
style STUB fill:#f5a623,color:#fff
Implementation Details
Backend Selection
| Backend | Macro | Platform | Quality |
|---|---|---|---|
| libunwind | X_HAS_LIBUNWIND | Linux (with libunwind installed) | Best — accurate unwinding, symbol + offset |
| execinfo | X_HAS_EXECINFO | macOS, Linux (glibc) | Good — requires -rdynamic on Linux for symbols |
| stub | (fallback) | Any | Minimal — returns "not supported" message |
Output Format
Each frame is formatted as:
#0 0x7fff8a1b2c3d symbol_name+0x1a
#1 0x7fff8a1b2c3d another_function+0x42
#2 0x7fff8a1b2c3d <unknown>
#N— Frame number (0 = most recent)0xADDR— Instruction pointer addresssymbol+offset— Function name and offset (if available)<unknown>— When symbol resolution fails
Frame Skipping
Call stack:
bt_capture() ← INTERNAL_SKIP (2 frames)
xBacktraceSkip() ← INTERNAL_SKIP
xLog() ← user skip = 2 (from xLog)
user_function() ← first visible frame
main()
xBacktrace() calls xBacktraceSkip(0, ...), which adds INTERNAL_SKIP = 2 to skip its own frames. xLog() calls xBacktraceSkip(2, ...) to also skip xLog and xLogSetCallback frames.
libunwind Backend
Uses unw_getcontext() → unw_init_local() → unw_step() loop. For each frame:
unw_get_reg(UNW_REG_IP)— Get instruction pointerunw_get_proc_name()— Get symbol name and offset
execinfo Backend
Uses backtrace() to capture frame addresses, then backtrace_symbols() to resolve names. On Linux, link with -rdynamic to export symbols for resolution.
API Reference
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xBacktrace | int xBacktrace(char *buf, size_t size) | Capture the call stack into buf. Equivalent to xBacktraceSkip(0, buf, size). | Thread-safe (uses only local/stack state) |
xBacktraceSkip | int xBacktraceSkip(int skip, char *buf, size_t size) | Capture the call stack, skipping skip additional frames beyond internal frames. | Thread-safe |
Parameters
| Parameter | Description |
|---|---|
skip | Number of additional frames to skip (0 = no extra skipping) |
buf | Destination buffer. May be NULL (returns 0). |
size | Size of buf in bytes. |
Return Value
Number of bytes written (excluding trailing \0), or 0 if buf is NULL or size is 0.
Usage Examples
Capture and Print Stack Trace
#include <stdio.h>
#include <x/base/backtrace.h>
void foo(void) {
char buf[4096];
int n = xBacktrace(buf, sizeof(buf));
if (n > 0) {
printf("Stack trace:\n%s", buf);
}
}
void bar(void) { foo(); }
int main(void) {
bar();
return 0;
}
Output (with execinfo on macOS):
Stack trace:
#0 0x100003f20 foo+0x20
#1 0x100003f80 bar+0x10
#2 0x100003fa0 main+0x10
Skip Wrapper Frames
#include <x/base/backtrace.h>
// Custom error reporter that skips its own frame
void report_error(const char *msg) {
char bt[2048];
xBacktraceSkip(1, bt, sizeof(bt)); // Skip report_error itself
fprintf(stderr, "Error: %s\nBacktrace:\n%s", msg, bt);
}
Use Cases
-
Fatal Error Diagnostics —
xLog()captures a backtrace on fatal errors, providing immediate context for debugging crashes. -
Debug Assertions — Custom assertion macros can include
xBacktrace()to show where the assertion failed. -
Memory Leak Detection — Record allocation backtraces to identify where leaked objects were created.
Best Practices
- Provide a large enough buffer. 4096 bytes is usually sufficient for 20-30 frames. The output is truncated (not corrupted) if the buffer is too small.
- Link with
-rdynamicon Linux. Without it, the execinfo backend shows only addresses, not symbol names. - Install libunwind for best results on Linux. It provides more accurate unwinding than execinfo, especially through optimized code and signal handlers.
- Don't call from signal handlers with execinfo.
backtrace_symbols()callsmalloc(), which is not async-signal-safe. libunwind is safer in this context.
Comparison with Other Libraries
| Feature | xbase backtrace.h | glibc backtrace() | libunwind | Boost.Stacktrace | Windows CaptureStackBackTrace |
|---|---|---|---|---|---|
| Platform | macOS + Linux + stub | Linux (glibc) | Linux + macOS | Cross-platform | Windows |
| Accuracy | Backend-dependent | Good (glibc) | Excellent | Backend-dependent | Good |
| Symbol Resolution | Built-in | backtrace_symbols() | unw_get_proc_name() | Backend-dependent | SymFromAddr() |
| Allocation | None (user buffer) | malloc() for symbols | None | Heap | None |
| Signal Safety | libunwind: yes, execinfo: no | No (malloc) | Yes | No | Yes |
| Frame Skipping | Built-in (skip param) | Manual | Manual | Manual | FramesToSkip param |
Key Differentiator: xbase's backtrace provides a simple, buffer-based API with automatic frame skipping and graceful degradation across platforms. It's designed for integration into error reporting paths where heap allocation is undesirable.
socket.h — Async Socket
Introduction
socket.h provides an async socket abstraction built on top of xEventLoop. It wraps the POSIX socket API with automatic non-blocking setup, event loop registration, and idle-timeout support. When a socket becomes readable, writable, or times out, a single unified callback is invoked with the appropriate event mask.
Design Philosophy
-
Thin Wrapper, Not a Framework —
xSocketadds just enough abstraction to eliminate boilerplate (non-blocking setup,FD_CLOEXEC, event registration) without hiding the underlying fd. You can always retrieve the raw fd viaxSocketFd()for direct system calls. -
Idle-Timeout Semantics — Read and write timeouts are reset on every corresponding I/O event, implementing idle-timeout behavior. This is ideal for detecting dead connections: if no data arrives within the timeout period, the callback fires with
xEvent_Timeout. -
Unified Callback — A single
xSocketFunccallback handles all events (read, write, timeout). Themaskparameter tells you what happened, and thexEvent_Timeoutflag is OR'd withxEvent_ReadorxEvent_Writeto indicate which direction timed out. -
Lifecycle Tied to Event Loop — A socket is created and destroyed in the context of an event loop.
xSocketDestroy()cancels timers, removes the event source, closes the fd, and frees the handle in one call.
Architecture
graph TD
APP["Application"] -->|"xSocketCreate()"| SOCKET["xSocket"]
SOCKET -->|"xEventAdd()"| LOOP["xEventLoop"]
LOOP -->|"I/O ready"| TRAMP["trampoline()"]
TRAMP -->|"reset timers"| TIMER["Timer Heap"]
TRAMP -->|"forward"| CB["callback(sock, mask, userp)"]
TIMER -->|"timeout"| TIMEOUT_CB["timeout_cb()"]
TIMEOUT_CB -->|"xEvent_Timeout"| CB
style SOCKET fill:#4a90d9,color:#fff
style LOOP fill:#f5a623,color:#fff
style CB fill:#50b86c,color:#fff
Implementation Details
Internal Structure
struct xSocket_ {
int fd; // Underlying file descriptor
xEventLoop loop; // Bound event loop
xEventSource source; // Registered event source
xEventMask mask; // Current event mask
xSocketFunc callback; // User callback
void *userp; // User data
xEventTimer read_timer; // Read idle timeout timer
xEventTimer write_timer; // Write idle timeout timer
int read_timeout_ms; // Read timeout setting (0 = disabled)
int write_timeout_ms; // Write timeout setting (0 = disabled)
};
Trampoline Pattern
The socket registers an internal trampoline() function as the event callback with the event loop. This trampoline:
- Resets idle timers — On
xEvent_Read, cancels and re-arms the read timer. OnxEvent_Write, cancels and re-arms the write timer. - Forwards to user callback — Calls
callback(sock, mask, userp)with the original event mask.
This ensures idle timers are always reset transparently, without requiring the user to manage them manually.
Socket Creation
xSocketCreate() performs these steps atomically:
socket(family, type, protocol)— On Linux/BSD withSOCK_CLOEXEC | SOCK_NONBLOCK, both flags are set in one syscall. On other platforms,fcntl()is used as a fallback.xEventAdd(loop, fd, mask, trampoline, socket)— Registers with the event loop.- Returns the opaque
xSockethandle.
Timeout Mechanism
sequenceDiagram
participant App
participant Socket as xSocket
participant L as xEventLoop
participant Timer as Timer Heap
App->>Socket: xSocketSetTimeout(sock, 5000, 3000)
Socket->>Timer: arm read timer (5s)
Socket->>Timer: arm write timer (3s)
Note over L: Data arrives on fd
L->>Socket: trampoline(fd, xEvent_Read)
Socket->>Timer: cancel + re-arm read timer (5s)
Socket->>App: callback(sock, xEvent_Read)
Note over Timer: 5 seconds of silence...
Timer->>Socket: read_timeout_cb()
Socket->>App: callback(sock, xEvent_Timeout | xEvent_Read)
API Reference
Types
| Type | Description |
|---|---|
xSocket | Opaque handle to an async socket |
xSocketFunc | void (*)(xSocket sock, xEventMask mask, void *arg) — Socket event callback |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xSocketCreate | xSocket xSocketCreate(xEventLoop loop, int family, int type, int protocol, xEventMask mask, xSocketFunc callback, void *userp) | Create a non-blocking socket and register with the event loop. | Not thread-safe |
xSocketDestroy | void xSocketDestroy(xEventLoop loop, xSocket sock) | Cancel timers, remove from event loop, close fd, free handle. Safe with NULL. | Not thread-safe |
xSocketSetMask | xErrno xSocketSetMask(xEventLoop loop, xSocket sock, xEventMask mask) | Change the watched event mask. | Not thread-safe |
xSocketSetTimeout | xErrno xSocketSetTimeout(xSocket sock, int read_timeout_ms, int write_timeout_ms) | Set idle timeouts. Pass 0 to cancel. Replaces previous settings. | Not thread-safe |
xSocketFd | int xSocketFd(xSocket sock) | Return the underlying fd, or -1 if NULL. | Thread-safe (read-only) |
xSocketMask | xEventMask xSocketMask(xSocket sock) | Return the current event mask, or 0 if NULL. | Thread-safe (read-only) |
Callback Mask Values
| Mask | Meaning |
|---|---|
xEvent_Read | Socket is readable |
xEvent_Write | Socket is writable |
xEvent_Timeout | xEvent_Read | Read idle timeout fired |
xEvent_Timeout | xEvent_Write | Write idle timeout fired |
Usage Examples
TCP Echo Client with Timeout
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <x/base/socket.h>
static xEventLoop g_loop;
static void on_socket(xSocket sock, xEventMask mask, void *arg) {
(void)arg;
if (mask & xEvent_Timeout) {
printf("Timeout on %s\n",
(mask & xEvent_Read) ? "read" : "write");
xSocketDestroy(g_loop, sock);
xEventLoopStop(g_loop);
return;
}
if (mask & xEvent_Read) {
char buf[1024];
ssize_t n;
while ((n = read(xSocketFd(sock), buf, sizeof(buf))) > 0) {
printf("Received: %.*s\n", (int)n, buf);
}
}
if (mask & xEvent_Write) {
const char *msg = "Hello, server!";
write(xSocketFd(sock), msg, strlen(msg));
// Switch to read-only after sending
xSocketSetMask(g_loop, sock, xEvent_Read);
}
}
int main(void) {
g_loop = xEventLoopCreate();
xSocket sock = xSocketCreate(g_loop, AF_INET, SOCK_STREAM, 0,
xEvent_Write, on_socket, NULL);
if (!sock) return 1;
// Set 5-second read idle timeout
xSocketSetTimeout(sock, 5000, 0);
// Connect (non-blocking)
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_port = htons(8080),
};
inet_pton(AF_INET, "127.0.0.1", &addr.sin_addr);
connect(xSocketFd(sock), (struct sockaddr *)&addr, sizeof(addr));
xEventLoopRun(g_loop);
xEventLoopDestroy(g_loop);
return 0;
}
UDP Receiver with Idle Timeout
#include <stdio.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <x/base/socket.h>
static void on_udp(xSocket sock, xEventMask mask, void *arg) {
xEventLoop loop = (xEventLoop)arg;
if (mask & xEvent_Timeout) {
printf("No data for 10 seconds, shutting down.\n");
xSocketDestroy(loop, sock);
xEventLoopStop(loop);
return;
}
if (mask & xEvent_Read) {
char buf[65536];
ssize_t n;
while ((n = read(xSocketFd(sock), buf, sizeof(buf))) > 0) {
printf("UDP: %.*s\n", (int)n, buf);
}
}
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xSocket sock = xSocketCreate(loop, AF_INET, SOCK_DGRAM, 0,
xEvent_Read, on_udp, loop);
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_port = htons(9999),
.sin_addr.s_addr = INADDR_ANY,
};
bind(xSocketFd(sock), (struct sockaddr *)&addr, sizeof(addr));
// 10-second read idle timeout
xSocketSetTimeout(sock, 10000, 0);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
Use Cases
-
Network Servers — Create listening sockets, accept connections, and manage each client with its own
xSocket+ idle timeout. Dead connections are automatically detected. -
Protocol Clients — Build async clients (HTTP, Redis, etc.) that connect, send requests, and wait for responses with timeout protection.
-
Real-Time Data Feeds — Monitor UDP multicast sockets with idle timeouts to detect feed outages.
Best Practices
- Always drain in edge-triggered mode. Since the underlying event loop is edge-triggered, read/write until
EAGAINin every callback. - Use idle timeouts for connection health. Set
read_timeout_msto detect dead peers. The timeout resets automatically on each read event. - Destroy sockets before the event loop.
xSocketDestroy()callsxEventDel()andxEventLoopTimerCancel(), which require a valid event loop. - Check the timeout direction. When
xEvent_Timeoutfires, checkmask & xEvent_Readvs.mask & xEvent_Writeto know which direction timed out. - Don't close the fd manually.
xSocketDestroy()closes it for you. Closing it separately leads to double-close bugs.
Comparison with Other Libraries
| Feature | xbase socket.h | POSIX socket API | libuv uv_tcp_t | Boost.Asio |
|---|---|---|---|---|
| Non-blocking Setup | Automatic (SOCK_NONBLOCK + FD_CLOEXEC) | Manual (fcntl) | Automatic | Automatic |
| Event Registration | Automatic (via xEventLoop) | Manual (epoll_ctl / kevent) | Automatic | Automatic |
| Idle Timeout | Built-in (xSocketSetTimeout) | Manual (timer + bookkeeping) | Manual (uv_timer) | Manual (deadline_timer) |
| Callback Style | Single unified callback with mask | N/A (blocking or manual poll) | Separate read/write callbacks | Separate handlers |
| Raw fd Access | xSocketFd() | Direct | uv_fileno() | native_handle() |
| Buffered I/O | No (raw fd) | No | Yes (uv_read_start) | Yes (async_read) |
| Platform | macOS + Linux | POSIX | Cross-platform | Cross-platform |
Key Differentiator: xbase's socket abstraction is intentionally thin — it handles the boilerplate (non-blocking, event registration, idle timeout) but leaves data reading/writing to the caller via the raw fd. This gives maximum flexibility without imposing a buffering strategy.
io.h — Abstract I/O Interfaces
Introduction
io.h defines four lightweight I/O interfaces — xReader, xWriter, xSeeker, xCloser — inspired by Go's io.Reader / io.Writer / io.Seeker / io.Closer. Each interface is a small struct containing a function pointer and an opaque void *ctx, making it trivial to adapt any object that provides the matching function signature.
On top of these interfaces, io.h provides a set of convenience functions (xRead, xReadFull, xReadAll, xWrite, xWritev, xSeek, xClose) that operate generically on any implementation, enabling code reuse across TCP connections, TLS streams, file descriptors, in-memory buffers, and more.
Design Philosophy
-
Value-Type Interfaces — Each interface is a plain struct (function pointer + context), not a heap-allocated object. They are cheap to copy, pass by value, and require no memory management.
-
POSIX Semantics — Function signatures mirror their POSIX counterparts:
read(2),writev(2),lseek(2),close(2). This makes the learning curve near-zero for C developers. -
Composable Helpers — Higher-level functions like
xReadFullandxReadAllare built on top ofxReader, so any object that provides a reader automatically gains these capabilities. -
Zero-Initialized = Invalid — A zero-initialized struct (all NULL) is treated as "not set". Convenience functions can detect this and return an error instead of crashing.
Architecture
graph TD
subgraph "Interfaces"
R["xReader<br/>ssize_t read(ctx, buf, len)"]
W["xWriter<br/>ssize_t writev(ctx, iov, iovcnt)"]
S["xSeeker<br/>off_t seek(ctx, offset, whence)"]
C["xCloser<br/>int close(ctx)"]
end
subgraph "Convenience Functions"
XR["xRead"]
XRF["xReadFull"]
XRA["xReadAll"]
XW["xWrite"]
XWV["xWritev"]
XS["xSeek"]
XC["xClose"]
end
subgraph "Implementations"
TCP["xTcpConn<br/>xTcpConnReader / xTcpConnWriter"]
IOB["xIOBuffer<br/>(read/writev funcs)"]
FD["File Descriptor<br/>(custom wrapper)"]
end
XR --> R
XRF --> R
XRA --> R
XW --> W
XWV --> W
XS --> S
XC --> C
TCP -.->|"adapts to"| R
TCP -.->|"adapts to"| W
IOB -.->|"adapts to"| R
IOB -.->|"adapts to"| W
FD -.->|"adapts to"| R
FD -.->|"adapts to"| W
style R fill:#4a90d9,color:#fff
style W fill:#4a90d9,color:#fff
style S fill:#4a90d9,color:#fff
style C fill:#4a90d9,color:#fff
style XRF fill:#50b86c,color:#fff
style XRA fill:#50b86c,color:#fff
Implementation Details
Interface Structs
Each interface is a two-field struct:
| Interface | Function Pointer | Semantics |
|---|---|---|
xReader | ssize_t (*read)(void *ctx, void *buf, size_t len) | Returns bytes read, 0 on EOF, -1 on error |
xWriter | ssize_t (*writev)(void *ctx, const struct iovec *iov, int iovcnt) | Returns bytes written, -1 on error |
xSeeker | off_t (*seek)(void *ctx, off_t offset, int whence) | Returns resulting offset, -1 on error |
xCloser | int (*close)(void *ctx) | Returns 0 on success, -1 on failure |
xReadFull — Retry Logic
xReadFull loops calling r.read until exactly len bytes are read or EOF is reached. It automatically retries on EAGAIN and EINTR, making it suitable for both blocking and non-blocking file descriptors:
while (total < len):
n = r.read(ctx, buf + total, len - total)
if n > 0: total += n
if n == 0: break // EOF
if n == -1:
if EAGAIN or EINTR: continue
else: return -1 // real error
return total
xReadAll — Dynamic Buffer Growth
xReadAll reads until EOF into a dynamically allocated buffer. It starts with a 4096-byte allocation and doubles the capacity each time the buffer fills up:
cap = 4096, buf = malloc(cap)
loop:
if total == cap: realloc(buf, cap * 2)
n = r.read(ctx, buf + total, cap - total)
if n > 0: total += n
if n == 0: *out = buf, *out_len = total, return 0
if n == -1:
if EAGAIN or EINTR: continue
else: free(buf), return -1
The caller is responsible for freeing the returned buffer with free().
xWrite — Single Buffer Convenience
xWrite wraps a contiguous buffer into a single struct iovec and delegates to w.writev, avoiding the need for callers to construct iovec arrays for simple writes:
ssize_t xWrite(xWriter w, const void *buf, size_t len) {
struct iovec iov = { .iov_base = (void *)buf, .iov_len = len };
return w.writev(w.ctx, &iov, 1);
}
API Reference
Types
| Type | Description |
|---|---|
xReader | Abstract reader — { ssize_t (*read)(void*, void*, size_t), void *ctx } |
xWriter | Abstract writer — { ssize_t (*writev)(void*, const struct iovec*, int), void *ctx } |
xSeeker | Abstract seeker — { off_t (*seek)(void*, off_t, int), void *ctx } |
xCloser | Abstract closer — { int (*close)(void*), void *ctx } |
Functions
| Function | Signature | Description |
|---|---|---|
xRead | ssize_t xRead(xReader r, void *buf, size_t len) | Single read; returns bytes read, 0 on EOF, -1 on error |
xWrite | ssize_t xWrite(xWriter w, const void *buf, size_t len) | Write a contiguous buffer (wraps into single iovec) |
xWritev | ssize_t xWritev(xWriter w, const struct iovec *iov, int iovcnt) | Scatter-gather write |
xSeek | off_t xSeek(xSeeker s, off_t offset, int whence) | Reposition offset (SEEK_SET / SEEK_CUR / SEEK_END) |
xClose | int xClose(xCloser c) | Close the underlying resource |
xReadFull | ssize_t xReadFull(xReader r, void *buf, size_t len) | Read exactly len bytes, retrying on partial reads and EAGAIN/EINTR |
xReadAll | int xReadAll(xReader r, void **out, size_t *out_len) | Read until EOF into a malloc'd buffer; caller must free(*out) |
Usage Examples
Creating a Custom Reader
#include <x/base/io.h>
#include <unistd.h>
// Adapt a file descriptor into an xReader
static ssize_t fd_read(void *ctx, void *buf, size_t len) {
int fd = (int)(intptr_t)ctx;
return read(fd, buf, len);
}
xReader make_fd_reader(int fd) {
xReader r;
r.read = fd_read;
r.ctx = (void *)(intptr_t)fd;
return r;
}
Reading Exactly N Bytes
#include <x/base/io.h>
void read_header(xReader r) {
char header[64];
ssize_t n = xReadFull(r, header, sizeof(header));
if (n < 0) {
// error
} else if ((size_t)n < sizeof(header)) {
// EOF before full header
} else {
// got all 64 bytes
}
}
Reading All Data Until EOF
#include <x/base/io.h>
#include <stdlib.h>
void read_body(xReader r) {
void *data;
size_t data_len;
if (xReadAll(r, &data, &data_len) == 0) {
// process data (data_len bytes at data)
free(data);
} else {
// error
}
}
Using with xTcpConn
xTcpConn (from <x/net/tcp.h>) provides adapter functions that return xReader and xWriter bound to the connection's transport layer. This allows TCP connections to be used with all generic I/O helpers:
#include <x/base/io.h>
#include <x/net/tcp.h>
void handle_connection(xTcpConn conn) {
// Get I/O adapters from the TCP connection
xReader r = xTcpConnReader(conn);
xWriter w = xTcpConnWriter(conn);
// Read a fixed-size header
char header[16];
ssize_t n = xReadFull(r, header, sizeof(header));
if (n < (ssize_t)sizeof(header)) return;
// Read the entire body until the peer closes
void *body;
size_t body_len;
if (xReadAll(r, &body, &body_len) != 0) return;
// Echo back through the generic writer
xWrite(w, body, body_len);
free(body);
}
Scatter-Gather Write
#include <x/base/io.h>
void send_http_response(xWriter w) {
const char *header = "HTTP/1.1 200 OK\r\nContent-Length: 5\r\n\r\n";
const char *body = "Hello";
struct iovec iov[2] = {
{ .iov_base = (void *)header, .iov_len = strlen(header) },
{ .iov_base = (void *)body, .iov_len = 5 },
};
xWritev(w, iov, 2);
}
Integration with xTcpConn
xTcpConn provides two adapter functions that bridge the TCP connection to the generic I/O interfaces:
| Function | Returns | Description |
|---|---|---|
xTcpConnReader(conn) | xReader | Reader bound to transport.read — equivalent to xTcpConnRecv |
xTcpConnWriter(conn) | xWriter | Writer bound to transport.writev — equivalent to xTcpConnSendIov |
These adapters are zero-allocation: they copy the function pointer and context from the connection's internal xTransport into a stack-allocated struct. The returned interfaces are valid as long as the connection (and its transport) remains alive.
Why no xCloser adapter? xTcpConnClose() requires an xEventLoop parameter to properly unregister the socket from the event loop, which does not fit the int (*close)(void *ctx) signature.
Best Practices
- Prefer
xReadFullover manual loops when you need an exact number of bytes. It handlesEAGAIN,EINTR, and partial reads correctly. - Always
free()the buffer fromxReadAllon success. On error, the function cleans up internally. - Use
xWritefor simple writes,xWritevfor multi-buffer writes.xWriteis a thin wrapper that constructs a single iovec — no performance penalty. - Check for zero-initialized interfaces before passing them to helpers. If
xTcpConnReader(NULL)returns a zero struct, callingxReadon it will dereference a NULL function pointer. - Obtain adapters once, use many times. Since
xTcpConnReader/xTcpConnWriterare value types, you can call them once at the start of a handler and reuse the result throughout.
Comparison with Other Libraries
| Feature | xbase io.h | Go io.Reader/Writer | POSIX read/write | C++ std::iostream |
|---|---|---|---|---|
| Abstraction | Struct (fn ptr + ctx) | Interface (vtable) | Raw syscall | Class hierarchy |
| Allocation | Zero (stack value) | Heap (interface value) | N/A | Heap (stream object) |
| Composability | Via helper functions | Via io.Copy, io.ReadAll, etc. | Manual loops | Via stream operators |
| Scatter-Gather | Built-in (xWritev) | No (use io.MultiWriter) | writev(2) | No |
| Read-Until-EOF | xReadAll (malloc'd buffer) | io.ReadAll ([]byte) | Manual loop | std::istreambuf_iterator |
| Error Model | Return value (-1 + errno) | (n, error) tuple | Return value (-1 + errno) | Stream state flags |
command.h — Async Command Executor
Introduction
command.h provides an asynchronous command executor that spawns child processes over xEventLoop with stdout/stderr capture, streaming, or discard modes. It uses fork() + execvp() with independent process groups for clean timeout/cancellation via killpg(). Child exit detection is done through SIGCHLD delivered via xEventLoopSignalWatch().
Design Philosophy
-
Event-Loop Integrated — Commands are spawned asynchronously and their lifecycle (I/O readiness, timeout, exit) is managed entirely through the event loop. No blocking
waitpid()polling is needed. -
Independent Process Groups — Each child is placed in its own process group via
setpgid(). This ensures thatkillpg()on timeout/cancellation kills the entire process tree (including any grandchildren), avoiding orphaned processes. -
Flexible Output Handling — Three output modes (Capture, Stream, Discard) cover the full spectrum from "I need the full output" to "I just want a live feed" to "I don't care about output at all." Each of stdout and stderr can be configured independently.
-
PTY Support — An optional pseudo-terminal mode (
xCommandInput_Pty) allocates a PTY for the child, merging stdout and stderr into a single stream. This is essential for programs that behave differently when connected to a terminal (e.g., colored output, interactive prompts). -
Graceful Cancellation —
xCommandExecutorCancel()sendsSIGTERMfirst, then escalates toSIGKILLafter a grace period. This gives well-behaved processes a chance to clean up.
Architecture
graph TD
APP["Application"] -->|"xCommandExecutorSubmit()"| EXEC["xCommandExecutor<br/>(Executor)"]
EXEC -->|"fork() + execvp()"| CHILD["Child Process"]
subgraph "Event Loop"
EXEC -->|"SIGCHLD watch"| SIGCHLD["Signal Watch"]
EXEC -->|"stdout/stderr fd"| IOWATCH["I/O Watch"]
EXEC -->|"timeout_ms"| TIMER["Timer Watch"]
end
CHILD -->|"exit"| SIGCHLD
CHILD -->|"stdout/stderr data"| IOWATCH
TIMER -->|"timeout fired"| EXEC
SIGCHLD -->|"on_done"| APP
IOWATCH -->|"on_stdout / on_stderr"| APP
style APP fill:#4a90d9,color:#fff
style EXEC fill:#f5a623,color:#fff
style CHILD fill:#50b86c,color:#fff
Implementation Details
Output Modes
| Mode | stdout/stderr behavior | xCommandResult fields |
|---|---|---|
xCommandOutput_Capture | Accumulate into internal buffers | stdout_buf / stderr_buf + stdout_len / stderr_len populated |
xCommandOutput_Stream | Deliver chunks via callbacks | stdout_buf / stderr_buf are NULL; use on_stdout / on_stderr callbacks |
xCommandOutput_Discard | Redirect to /dev/null | stdout_buf / stderr_buf are NULL |
Input Modes
| Mode | Description |
|---|---|
xCommandInput_Pipe | Default: stdin is inherited from the parent process (no PTY). stdout and stderr are captured/streamed separately via pipes. |
xCommandInput_Pty | Allocate a pseudo-terminal for the child. The child's stdin, stdout, and stderr are all connected to the PTY slave side. The parent reads from the PTY master fd. |
PTY mode implications:
- stdout and stderr are merged into a single stream (the PTY master).
stderr_modeis effectively ignored — there is no separate stderr stream.- In Capture mode, all output goes to
result.stdout_bufonly;result.stderr_bufis always NULL. - The
on_stderrcallback is never invoked. result.pty_fdis set to the master fd while the command is running, allowing the caller to write to the child's stdin. It is set to-1after the command completes.
Process Lifecycle
flowchart TD
SUBMIT["xCommandExecutorSubmit()"]
FORK["fork() + execvp()"]
SETPGID["setpgid() → own process group"]
RUNNING["Command running"]
CHECK_SIGCHLD{"SIGCHLD received?"}
CHECK_EXIT{"Normal exit?"}
DONE["on_done(result)"]
TIMEOUT{"Timeout expired?"}
CANCEL{"xCommandExecutorCancel()?"}
SIGTERM["killpg(SIGTERM)"]
GRACE{"Grace period (5s)"}
SIGKILL["killpg(SIGKILL)"]
SUBMIT --> FORK
FORK --> SETPGID
SETPGID --> RUNNING
RUNNING --> CHECK_SIGCHLD
CHECK_SIGCHLD -->|Yes| CHECK_EXIT
CHECK_EXIT -->|Yes| DONE
CHECK_EXIT -->|No| RUNNING
CHECK_SIGCHLD -->|No| TIMEOUT
TIMEOUT -->|No| CANCEL
CANCEL -->|No| RUNNING
TIMEOUT -->|Yes| SIGTERM
CANCEL -->|Yes| SIGTERM
SIGTERM --> GRACE
GRACE --> CHECK_EXIT
GRACE -->|"still alive"| SIGKILL
SIGKILL --> DONE
style SUBMIT fill:#4a90d9,color:#fff
style DONE fill:#50b86c,color:#fff
style SIGKILL fill:#e74c3c,color:#fff
Sequential Execution
An xCommandExecutor can only run one command at a time. Calling xCommandExecutorSubmit() while a command is running returns xErrno_Busy. After on_done fires, the executor can be reused for a new command — there is no need to destroy and recreate it.
API Reference
Types
| Type | Description |
|---|---|
xCommandOutputMode | Enum: xCommandOutput_Capture, xCommandOutput_Stream, xCommandOutput_Discard |
xCommandInputMode | Enum: xCommandInput_Pipe (default), xCommandInput_Pty |
xCommandConf | Configuration struct for a command invocation |
xCommandResult | Result struct populated on command completion |
xCommandExecutor | Opaque handle to a command executor |
xCommandExecutorOutputFunc | void (*)(xCommandExecutor, const char *data, size_t len, void *ud) — streaming output callback |
xCommandExecutorDoneFunc | void (*)(xCommandExecutor, const xCommandResult *result, void *ud) — completion callback |
xCommandConf Fields
| Field | Type | Description |
|---|---|---|
cmd | const char * | Program path (required, searched in $PATH) |
argv | const char ** | Argument vector (NULL-terminated, may be NULL) |
envp | const char ** | Environment (NULL = inherit parent) |
cwd | const char * | Working directory (NULL = inherit) |
timeout_ms | uint64_t | Timeout in milliseconds (0 = no timeout) |
stdout_cap | size_t | Max stdout bytes to capture (0 = unlimited) |
stderr_cap | size_t | Max stderr bytes to capture (0 = unlimited, ignored in PTY mode) |
stdout_mode | xCommandOutputMode | How to handle stdout |
stderr_mode | xCommandOutputMode | How to handle stderr (ignored in PTY mode) |
input_mode | xCommandInputMode | xCommandInput_Pipe (default) or xCommandInput_Pty |
xCommandResult Fields
| Field | Type | Description |
|---|---|---|
exit_code | int | Exit status (valid if signaled == 0) |
signaled | int | Non-zero if killed by signal; holds signal number |
timed_out | int | Non-zero if killed due to timeout |
stdout_buf | const char * | Captured stdout (NULL in Stream/Discard mode) |
stdout_len | size_t | Length of captured stdout |
stderr_buf | const char * | Captured stderr (NULL in Stream/Discard/PTY mode) |
stderr_len | size_t | Length of captured stderr |
elapsed_ms | uint64_t | Wall-clock duration from spawn to exit |
pty_fd | int | PTY master fd (valid while running, -1 otherwise) |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xCommandExecutorCreate | xCommandExecutor xCommandExecutorCreate(xEventLoop loop) | Create a command executor bound to the given event loop. Registers a SIGCHLD watch. | Not thread-safe |
xCommandExecutorDestroy | void xCommandExecutorDestroy(xCommandExecutor exec) | Destroy an executor. If running, kills the child process group (SIGKILL) and waits. NULL-safe. | Not thread-safe |
xCommandExecutorSubmit | xErrno xCommandExecutorSubmit(xCommandExecutor exec, const xCommandConf *conf, xCommandExecutorOutputFunc on_stdout, xCommandExecutorOutputFunc on_stderr, xCommandExecutorDoneFunc on_done, void *ud) | Submit a command for asynchronous execution. Returns xErrno_Busy if already running. | Not thread-safe (call from event loop thread) |
xCommandExecutorCancel | xErrno xCommandExecutorCancel(xCommandExecutor exec) | Cancel a running command (SIGTERM → SIGKILL after 5s). Returns xErrno_InvalidState if not running. | Not thread-safe |
xCommandExecutorPid | int xCommandExecutorPid(xCommandExecutor exec) | Return the PID of the running child, or -1 if idle. NULL-safe. | Thread-safe (atomic) |
xCommandExecutorIsRunning | int xCommandExecutorIsRunning(xCommandExecutor exec) | Return non-zero if a command is currently running. NULL-safe. | Thread-safe (atomic) |
xCommandExecutorPtyFd | int xCommandExecutorPtyFd(xCommandExecutor exec) | Return the PTY master fd, or -1 if not in PTY mode or not running. NULL-safe. | Thread-safe |
Usage Examples
Capture stdout
#include <stdio.h>
#include <x/base/command.h>
#include <x/base/event.h>
static void on_done(xCommandExecutor exec, const xCommandResult *result, void *ud) {
xEventLoop loop = (xEventLoop)ud;
if (result->exit_code == 0) {
printf("Output: %.*s\n", (int)result->stdout_len, result->stdout_buf);
}
xEventLoopStop(loop);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xCommandExecutor exec = xCommandExecutorCreate(loop);
const char *argv[] = {"hello", "world", NULL};
xCommandConf conf = {};
conf.cmd = "/bin/echo";
conf.argv = argv;
conf.stdout_mode = xCommandOutput_Capture;
conf.stderr_mode = xCommandOutput_Discard;
xCommandExecutorSubmit(exec, &conf, NULL, NULL, on_done, loop);
xEventLoopRun(loop);
xCommandExecutorDestroy(exec);
xEventLoopDestroy(loop);
return 0;
}
Stream stdout in real time
#include <stdio.h>
#include <x/base/command.h>
#include <x/base/event.h>
static void on_stdout(xCommandExecutor exec, const char *data, size_t len, void *ud) {
fwrite(data, 1, len, stdout);
}
static void on_done(xCommandExecutor exec, const xCommandResult *result, void *ud) {
xEventLoop loop = (xEventLoop)ud;
xEventLoopStop(loop);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xCommandExecutor exec = xCommandExecutorCreate(loop);
const char *argv[] = {"-c", "for i in 1 2 3; do echo line $i; done", NULL};
xCommandConf conf = {};
conf.cmd = "/bin/sh";
conf.argv = argv;
conf.stdout_mode = xCommandOutput_Stream;
conf.stderr_mode = xCommandOutput_Discard;
xCommandExecutorSubmit(exec, &conf, on_stdout, NULL, on_done, loop);
xEventLoopRun(loop);
xCommandExecutorDestroy(exec);
xEventLoopDestroy(loop);
return 0;
}
Timeout and cancellation
#include <stdio.h>
#include <x/base/command.h>
#include <x/base/event.h>
static void on_done(xCommandExecutor exec, const xCommandResult *result, void *ud) {
xEventLoop loop = (xEventLoop)ud;
if (result->timed_out) {
printf("Command timed out after %llu ms\n",
(unsigned long long)result->elapsed_ms);
}
xEventLoopStop(loop);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xCommandExecutor exec = xCommandExecutorCreate(loop);
const char *argv[] = {"60", NULL};
xCommandConf conf = {};
conf.cmd = "/bin/sleep";
conf.argv = argv;
conf.timeout_ms = 3000; /* 3-second timeout */
conf.stdout_mode = xCommandOutput_Discard;
conf.stderr_mode = xCommandOutput_Discard;
xCommandExecutorSubmit(exec, &conf, NULL, NULL, on_done, loop);
xEventLoopRun(loop);
xCommandExecutorDestroy(exec);
xEventLoopDestroy(loop);
return 0;
}
PTY mode with stdin
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <x/base/command.h>
#include <x/base/event.h>
static void on_done(xCommandExecutor exec, const xCommandResult *result, void *ud) {
xEventLoop loop = (xEventLoop)ud;
if (result->stdout_buf) {
printf("Output: %.*s\n", (int)result->stdout_len, result->stdout_buf);
}
xEventLoopStop(loop);
}
static void on_stdout(xCommandExecutor exec, const char *data, size_t len, void *ud) {
fwrite(data, 1, len, stdout);
fflush(stdout);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xCommandExecutor exec = xCommandExecutorCreate(loop);
const char *argv[] = {NULL};
xCommandConf conf = {};
conf.cmd = "/bin/cat"; /* cat echoes stdin to stdout */
conf.argv = argv;
conf.stdout_mode = xCommandOutput_Stream;
conf.stderr_mode = xCommandOutput_Discard;
conf.input_mode = xCommandInput_Pty;
xCommandExecutorSubmit(exec, &conf, on_stdout, NULL, on_done, loop);
/* Write to the child's stdin via the PTY master fd */
int pty_fd = xCommandExecutorPtyFd(exec);
if (pty_fd >= 0) {
write(pty_fd, "hello\n", 6);
}
xEventLoopRun(loop);
xCommandExecutorDestroy(exec);
xEventLoopDestroy(loop);
return 0;
}
Custom working directory and environment
#include <stdio.h>
#include <x/base/command.h>
#include <x/base/event.h>
static void on_done(xCommandExecutor exec, const xCommandResult *result, void *ud) {
xEventLoop loop = (xEventLoop)ud;
printf("Exit code: %d\n", result->exit_code);
if (result->stdout_buf) {
printf("pwd: %.*s\n", (int)result->stdout_len, result->stdout_buf);
}
xEventLoopStop(loop);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xCommandExecutor exec = xCommandExecutorCreate(loop);
const char *envp[] = {"MY_VAR=42", NULL};
xCommandConf conf = {};
conf.cmd = "/bin/pwd";
conf.cwd = "/tmp";
conf.envp = envp;
conf.stdout_mode = xCommandOutput_Capture;
conf.stderr_mode = xCommandOutput_Discard;
xCommandExecutorSubmit(exec, &conf, NULL, NULL, on_done, loop);
xEventLoopRun(loop);
xCommandExecutorDestroy(exec);
xEventLoopDestroy(loop);
return 0;
}
Use Cases
-
Shell Command Execution — Run system commands (e.g.,
git,docker, build tools) asynchronously and capture their output without blocking the event loop. -
Process Pipeline Integration — Use streaming mode to feed a child process's output into another system in real time (e.g., log aggregation, progress monitoring).
-
Interactive Programs — PTY mode enables interaction with programs that require a terminal (e.g., SSH sessions, REPLs, text editors with colored output).
-
Build/Deploy Automation — Run build scripts with timeout enforcement. If a build hangs, it is automatically killed after the configured timeout.
-
Health Checks — Periodically execute diagnostic commands and parse their output to determine system health.
Best Practices
-
Always set
on_done. The completion callback is the only way to know when a command finishes. It fires even on timeout or cancellation, so you can always clean up in one place. -
Reuse executors for sequential commands. After
on_donefires, the samexCommandExecutorcan be used for the next command. There is no need to destroy and recreate it. -
Use
stdout_cap/stderr_capto limit memory. Unbounded capture can exhaust memory if a command produces large output. Set a cap to prevent this. -
Use Discard mode when output is not needed. This avoids the overhead of reading and buffering output entirely.
-
Be aware of PTY line editing. In PTY mode, the child's terminal driver may echo input and insert
\rbefore\n. Strip\rif you need clean output. -
Don't call
xCommandExecutorSubmit()from theon_donecallback. Although the executor is idle at that point, callingxCommandExecutorSubmit()insideon_donewill start a new command immediately while the event loop is still processing I/O events from the previous one. Instead, usexEventLoopPost()to defer the next run.
Comparison with Other Libraries
| Feature | xbase command.h | popen() / pclose() | posix_spawn() | libuv uv_spawn |
|---|---|---|---|---|
| Async / Event-Loop | Yes (xEventLoop) | No (blocking) | No (blocking wait) | Yes (uv_loop) |
| stdout + stderr | Separate capture/stream | stdout only | Manual pipe setup | Separate pipes |
| Streaming | Yes (callbacks) | Line-by-line only | Manual | Yes (callbacks) |
| PTY Support | Yes (xCommandInput_Pty) | No | No | No (external) |
| Timeout | Built-in (timeout_ms) | Manual | Manual | Manual (uv_timer) |
| Cancellation | xCommandExecutorCancel() (SIGTERM→SIGKILL) | kill() + pclose() | kill() + waitpid() | uv_process_kill() |
| Process Groups | Yes (independent via setpgid) | No | No | No (manual) |
| Platform | macOS + Linux | POSIX | POSIX | Cross-platform |
Key Differentiator: xbase's command executor is deeply integrated with the event loop, providing built-in timeout, cancellation with graceful escalation, independent process groups, and PTY support — features that require significant boilerplate with lower-level APIs.
flag.h — Command-Line Flag Parser
Introduction
flag.h is a self-contained POSIX/GNU-style command-line parser. It replaces ad-hoc getopt(3) usage across examples and applications, producing structured values in caller-owned storage and auto-generating a usage screen. It is deliberately scoped to a single, flat flag set — subcommand trees, environment fallback, shell-completion, and long-name prefix matching are left to a future higher-level xcli module layered on top.
Design Philosophy
-
Zero-Copy, Caller-Owned Storage — Each
xFlagAdd*call takes a typed pointer (bool *,int *,const char **, …).xFlagParse()writes directly into that storage. String values point intoargvmemory, matchinggetopt'soptargconvention — no hidden allocations on the hot path. -
Never Calls
exit()— The parser returns a structuredxErrno; the caller decides what to do.--help/--versionare surfaced asxErrno_Againafter the text is printed on stdout, so applications stay in full control of their exit path. -
POSIX/GNU Syntax, Strict Matching — Short bundling (
-abc), glued values (-fvalue),--long=value,--end-of-options, and the bare-stdin idiom are all supported. Long-name prefix matching (--fifor--file) is deliberately omitted: exact match only, to keep scripts forward-compatible when new flags are added. -
Auto-Generated Help — Every flag carries a one-line description, an optional argument placeholder, and an optional default.
xFlagPrintHelp()formats a standard usage block (USAGE:line →Arguments:→Options:→ epilog) with two-column alignment. Hidden flags (xFlagAttr_Hidden) are omitted. -
Built-in Validation — Integer flags accept decimal,
0xhex,0bbinary, and0-prefixed octal, with overflow detection. Choice flags enforce a fixed whitelist and report valid values on mismatch. Required flags fail parse if absent.
Architecture
graph TD
APP["Application"]
SET["xFlagSet<br/>(registered flags)"]
PARSE["xFlagParse()"]
STORAGE["Caller Storage<br/>(bool, int, const char*, ...)"]
HELP["xFlagPrintHelp()"]
ERR["err_out (char*)"]
APP -->|xFlagSetCreate| SET
APP -->|xFlagAddString / Bool / Int / ...| SET
APP -->|xFlagParse argc/argv| PARSE
SET --> PARSE
PARSE -->|on success| STORAGE
PARSE -->|on --help| HELP
PARSE -->|on error| ERR
APP -->|use values| STORAGE
style APP fill:#4a90d9,color:#fff
style SET fill:#f5a623,color:#fff
style PARSE fill:#50b86c,color:#fff
Implementation Details
Supported Syntax
| Form | Meaning |
|---|---|
-f value | Short flag with a separate argument |
-fvalue | Short flag with a glued argument |
-abc | Bundled no-arg shorts; the last one may take an argument |
--file value | Long flag with a separate argument |
--file=value | Long flag with an =-form argument |
--flag | Long boolean or counter |
-- | End-of-options; everything after is positional |
- | Treated as a positional argument (stdin idiom) |
Not Supported (by design, in v1)
- Subcommand trees (deferred to a future
xclimodule) - Environment / config-file fallback
- Shell-completion generation
- Long-name prefix matching (
--fifor--file): exact match required - i18n
- Dynamic registration after
xFlagParse()has started
Flag Attributes
xFlagAttr is a bitmask passed as the final argument to every xFlagAdd* call.
| Attribute | Meaning |
|---|---|
xFlagAttr_None | Default (no attribute) |
xFlagAttr_Required | Parse fails with xErrno_InvalidArg if the flag is absent |
xFlagAttr_Hidden | Omit from --help output (useful for internal/debug flags) |
xFlagAttr_Multi | Allow repetition; each occurrence is collected into an internal array. Only meaningful for string flags |
Help / Version Handling
--help/-hare always recognised (unless the caller has already registeredh).--version/-Vare recognised only afterxFlagSetVersion()has been called (and only if those names are free).- Both cause
xFlagParse()to print to stdout and returnxErrno_Again. No flag storage is written.
Integer Parsing
xFlagAddInt / xFlagAddI64 / xFlagAddU64 accept:
| Prefix | Base |
|---|---|
0x / 0X | Hexadecimal (e.g. -n 0xff) |
0b / 0B | Binary (e.g. -n 0b1010) |
0 + digit | Octal (e.g. -n 0755) |
| (anything else) | Decimal |
Overflow or trailing garbage produces xErrno_InvalidArg with a descriptive err_out.
Memory Ownership
Owned by xFlagSet (freed on xFlagSetDestroy) | Owned by caller |
|---|---|
Copies of every name, help, meta, def, summary, prog, epilog string | Storage pointers (bool *, const char **, …) |
Arrays collected for xFlagAttr_Multi | choices array for xFlagAddChoice (must outlive the set) |
Tail positional array allocated by xFlagAddPositionalTail | argv itself (used zero-copy for string values) |
Error string written to *err_out | (the caller must free() *err_out) |
Parsed string values point into argv. If you need them to outlive main's argv, strdup() them.
API Reference
Types
| Type | Description |
|---|---|
xFlagSet | Opaque handle representing a set of registered flags |
xFlagAttr | Per-flag attribute bitmask (see Flag Attributes) |
Lifecycle
| Function | Signature | Description |
|---|---|---|
xFlagSetCreate | xFlagSet xFlagSetCreate(const char *prog, const char *summary) | Create a flag set. prog is shown in usage (typically argv[0] or a fixed string); summary is an optional one-line description |
xFlagSetDestroy | void xFlagSetDestroy(xFlagSet set) | Destroy a flag set and release owned memory. NULL-safe. Does not touch caller-owned storage |
xFlagSetEpilog | void xFlagSetEpilog(xFlagSet set, const char *text) | Append an epilog section printed after the options block (e.g. "Examples:" or "Notes:"). Pass NULL to clear |
xFlagSetVersion | void xFlagSetVersion(xFlagSet set, const char *version) | Register a version string; enables --version / -V handling. Pass NULL to disable |
Scalar Flag Registration
All xFlagAdd* functions return xErrno_Ok, xErrno_InvalidArg (bad arguments), xErrno_AlreadyExists (duplicate name/shortc), or xErrno_NoMemory.
| Function | Signature | Description |
|---|---|---|
xFlagAddString | xErrno xFlagAddString(xFlagSet set, const char *name, char shortc, const char *meta, const char *help, const char **storage, const char *def, int attrs) | String flag (--url ws://... / -u ws://...) |
xFlagAddBool | xErrno xFlagAddBool(xFlagSet set, const char *name, char shortc, const char *help, bool *storage, int attrs) | Boolean switch; presence → true; takes no argument |
xFlagAddInt | xErrno xFlagAddInt(xFlagSet set, const char *name, char shortc, const char *meta, const char *help, int *storage, int def, int attrs) | Signed 32-bit integer |
xFlagAddI64 | xErrno xFlagAddI64(xFlagSet set, const char *name, char shortc, const char *meta, const char *help, int64_t *storage, int64_t def, int attrs) | Signed 64-bit integer |
xFlagAddU64 | xErrno xFlagAddU64(xFlagSet set, const char *name, char shortc, const char *meta, const char *help, uint64_t *storage, uint64_t def, int attrs) | Unsigned 64-bit integer |
xFlagAddDouble | xErrno xFlagAddDouble(xFlagSet set, const char *name, char shortc, const char *meta, const char *help, double *storage, double def, int attrs) | Double-precision float |
xFlagAddChoice | xErrno xFlagAddChoice(xFlagSet set, const char *name, char shortc, const char *meta, const char *help, const char *const *choices, const char **storage, const char *def, int attrs) | String flag restricted to a fixed whitelist. choices is a NULL-terminated array that must outlive set |
xFlagAddCounter | xErrno xFlagAddCounter(xFlagSet set, const char *name, char shortc, const char *help, int *storage, int attrs) | Counter; each occurrence increments storage by 1 (e.g. -vvv → 3). Takes no argument |
Shared parameter conventions:
| Parameter | Meaning |
|---|---|
name | Long name without dashes (e.g. "file"). May be NULL for short-only flags. Must be unique |
shortc | Single-character short name (e.g. 'f'). Pass 0 for long-only flags. Must be unique |
meta | Placeholder shown in usage (e.g. "FILE"). NULL → the flag takes no argument in usage formatting. Ignored by xFlagAddBool / xFlagAddCounter |
help | One-line description (NULL → empty) |
storage | Pointer to caller-owned variable filled on successful parse. Must outlive xFlagParse() |
def | Default value written to *storage before parsing; also shown as [default: ...] in usage |
attrs | Bitmask of xFlagAttr values |
Positional Registration
| Function | Signature | Description |
|---|---|---|
xFlagAddPositional | xErrno xFlagAddPositional(xFlagSet set, const char *name, const char *help, const char **storage, int attrs) | Register a single positional argument. Positionals are matched in registration order. Use xFlagAttr_Required to mark mandatory ones |
xFlagAddPositionalTail | xErrno xFlagAddPositionalTail(xFlagSet set, const char *name, const char *help, const char ***storage, size_t *count, int attrs) | Register a tail positional that captures all remaining argv after previously-registered positionals. Only one tail is allowed, and it must be registered last. The resulting NUL-terminated array is owned by the set |
Parse & Output
| Function | Signature | Description |
|---|---|---|
xFlagParse | xErrno xFlagParse(xFlagSet set, int argc, char *const argv[], char **err_out) | Parse argv and populate every registered storage pointer. Returns xErrno_Ok on success, xErrno_Again if --help or --version was handled (text already printed to stdout), xErrno_InvalidArg on bad input (*err_out filled with a one-line message the caller must free()), or xErrno_NoMemory. Never calls exit() |
xFlagPrintUsage | void xFlagPrintUsage(xFlagSet set, void *fp) | Print the USAGE: ... summary line to fp (typically stdout or stderr; typed as void * to keep <stdio.h> out of the header) |
xFlagPrintHelp | void xFlagPrintHelp(xFlagSet set, void *fp) | Print the full help screen (usage + arguments + options + epilog) to fp |
Usage Examples
Minimal boolean + string flag
#include <stdio.h>
#include <stdlib.h>
#include <x/base/flag.h>
int main(int argc, char *argv[]) {
xFlagSet set = xFlagSetCreate("demo", "a tiny example");
bool ipv6 = false;
const char *url = NULL;
xFlagAddBool (set, "ipv6", '6', "enable IPv6", &ipv6, xFlagAttr_None);
xFlagAddString(set, "url", 'u', "URL", "signal server",
&url, "ws://127.0.0.1:8080/ws", xFlagAttr_None);
char *err = NULL;
xErrno rc = xFlagParse(set, argc, argv, &err);
if (rc == xErrno_Again) { xFlagSetDestroy(set); return 0; }
if (rc != xErrno_Ok) {
fprintf(stderr, "%s\n", err ? err : "parse error");
free(err);
xFlagSetDestroy(set);
return 1;
}
printf("ipv6 = %s, url = %s\n", ipv6 ? "true" : "false", url);
xFlagSetDestroy(set);
return 0;
}
Integer, counter and choice
#include <stdio.h>
#include <stdlib.h>
#include <x/base/flag.h>
int main(int argc, char *argv[]) {
xFlagSet set = xFlagSetCreate("srv", "demo server");
int port = 0;
int verbose = 0; /* -vvv → 3 */
const char *level = NULL; /* one of debug/info/warn/error */
static const char *const levels[] = {
"debug", "info", "warn", "error", NULL,
};
xFlagAddInt (set, "port", 'p', "PORT", "listen port",
&port, 8080, xFlagAttr_None);
xFlagAddCounter(set, "verbose", 'v', "increase verbosity",
&verbose, xFlagAttr_None);
xFlagAddChoice (set, "level", 'l', "LEVEL", "log level",
levels, &level, "info", xFlagAttr_None);
char *err = NULL;
xErrno rc = xFlagParse(set, argc, argv, &err);
if (rc == xErrno_Again) { xFlagSetDestroy(set); return 0; }
if (rc != xErrno_Ok) {
fprintf(stderr, "%s\n", err ? err : "parse error");
free(err);
xFlagSetDestroy(set);
return 1;
}
printf("port=%d verbose=%d level=%s\n", port, verbose, level);
xFlagSetDestroy(set);
return 0;
}
Invocation examples that all succeed:
srv --port 9000 -vvv --level=debug
srv -p 0x1f90 -v -v -v -l debug
srv # uses defaults: port=8080 verbose=0 level=info
Positional arguments and a tail
#include <stddef.h>
#include <stdio.h>
#include <stdlib.h>
#include <x/base/flag.h>
int main(int argc, char *argv[]) {
xFlagSet set = xFlagSetCreate("tar", "mini tar(1)");
const char *archive = NULL;
const char **members = NULL;
size_t n = 0;
/* Positionals are matched in registration order.
* Layout on the command line: tar ARCHIVE MEMBERS...
* So register ARCHIVE first, then the MEMBERS tail. */
xFlagAddPositional (set, "ARCHIVE", "archive path", &archive,
xFlagAttr_Required);
xFlagAddPositionalTail(set, "MEMBERS", "files to add", &members, &n,
xFlagAttr_None);
char *err = NULL;
xErrno rc = xFlagParse(set, argc, argv, &err);
if (rc == xErrno_Again) { xFlagSetDestroy(set); return 0; }
if (rc != xErrno_Ok) {
fprintf(stderr, "%s\n", err ? err : "parse error");
free(err);
xFlagSetDestroy(set);
return 1;
}
printf("archive = %s\n", archive);
for (size_t i = 0; i < n; ++i) printf(" + %s\n", members[i]);
xFlagSetDestroy(set);
return 0;
}
Note: positionals are matched in the order they are registered, and a tail positional must be registered last. A trailing required positional after a tail (e.g.
cp SRC... DST) is not supported in v1 — you would need to consume the last element manually after parsing, or skip the tail and iterateargvyourself.
Handling -- and stdin shorthand
#include <stddef.h>
#include <stdio.h>
#include <stdlib.h>
#include <x/base/flag.h>
int main(int argc, char *argv[]) {
xFlagSet set = xFlagSetCreate("grep", "tiny grep");
bool invert = false;
const char *pattern = NULL;
const char **files = NULL;
size_t nfiles = 0;
xFlagAddBool (set, "invert", 'v', "invert match", &invert,
xFlagAttr_None);
xFlagAddPositional (set, "PATTERN", "regex", &pattern,
xFlagAttr_Required);
xFlagAddPositionalTail(set, "FILE", "input files (use - for stdin)",
&files, &nfiles, xFlagAttr_None);
char *err = NULL;
xErrno rc = xFlagParse(set, argc, argv, &err);
if (rc == xErrno_Again) { xFlagSetDestroy(set); return 0; }
if (rc != xErrno_Ok) {
fprintf(stderr, "%s\n", err ? err : "parse error");
free(err);
xFlagSetDestroy(set);
return 1;
}
/* `grep -- -v foo.txt` treats "-v" as the PATTERN (positional),
* because "--" ends option parsing.
* `grep foo -` leaves files = {"-"} so the caller reads from stdin. */
xFlagSetDestroy(set);
return 0;
}
Generated help screen
With the flags from the "Integer, counter and choice" example plus xFlagSetVersion(set, "1.2.3"), running srv --help prints something like:
srv - demo server
USAGE: srv [OPTIONS]
Options:
-p, --port PORT listen port [default: 8080]
-v, --verbose increase verbosity
-l, --level LEVEL log level (one of: debug, info, warn, error) [default: info]
-V, --version show version
-h, --help show this help
Use Cases
-
Example / Demo Programs — Replace
getopt_long()boilerplate inexamples/with a fewxFlagAdd*calls and get a formatted help screen for free. -
CLI Tools — Small moo-based utilities (benchmarks, migration scripts, diagnostic tools) that want conventional POSIX/GNU syntax without pulling in
argpor a heavyweight parser. -
Application Front-Ends — Projects under
cli/that wrap moo modules into standalone binaries can useflag.hfor their startup configuration, and later upgrade toxclionce subcommand trees are needed. -
Configuration Overrides — Parse command-line overrides before loading a config file;
xFlagAttr_Requiredmarks mandatory knobs and[default: ...]documents the rest in--help.
Best Practices
-
Always handle
xErrno_Again. This signals that--help/--versionwas processed. The parser has already written to stdout; the caller should exit0cleanly. -
free()the error string. On failure,*err_outis heap-allocated. Forgetting to free leaks one string per failed invocation — minor, but tools like leak sanitisers will flag it. -
strdup()strings you need to outlivemain. Parsed string values point intoargv. If you stash them into a long-lived config struct, copy them. -
Register positionals last, tail last of all. Long flags and short flags can be registered in any order, but positionals are matched in registration order, and a tail positional must come at the end.
-
Prefer
xFlagAddChoiceover free-form strings. The parser does the enum validation for you and shows the allowed values in--help, saving you astrcmpladder and giving users a self-documenting interface. -
Don't depend on prefix matching.
--filwill not match--file. This is deliberate — scripts that relied on a prefix would silently break when a new flag with the same prefix is added. -
Use
xFlagAttr_Hiddensparingly. Reserve it for internal / debug / deprecated flags. A hidden flag that users need to discover is a support-channel footgun.
Comparison with Other Parsers
| Feature | xbase flag.h | getopt(3) | getopt_long(3) | argp (glibc) |
|---|---|---|---|---|
| POSIX short / GNU long | Both | Short only | Both | Both |
Auto-generated --help | Yes | No | No | Yes |
Typed storage (bool, int, …) | Yes | No (string only) | No (string only) | Partial (via parser fn) |
| Choice validation | Yes | No | No | Manual |
Counter flags (-vvv) | Built-in | Manual | Manual | Manual |
| Default values in help | Yes | No | No | No |
| Positional + tail support | Yes | Manual | Manual | Via parser fn |
Never calls exit() | Yes | Yes | Yes | No (default handlers) |
| Subcommand trees | No (future xcli) | No | No | Yes |
| Environment / config fallback | No | No | No | No |
| Platform | macOS + Linux | POSIX | GNU | glibc |
Key Differentiator: flag.h gives you argp-class ergonomics (typed storage, auto-help, validation) in a header-plus-.c pair that is portable across macOS and Linux, without exit()-by-default behaviour or glibc dependencies.
xbuf — Buffer Toolkit
Introduction
xbuf is moo's buffer module, providing three distinct buffer types optimized for different use cases: a linear auto-growing buffer, a fixed-size ring buffer, and a reference-counted block-chain I/O buffer. Together they cover the full spectrum of buffering needs — from simple byte accumulation to zero-copy network I/O.
Design Philosophy
-
One Buffer Does Not Fit All — Rather than a single "universal" buffer, xbuf offers three specialized types. Each makes different trade-offs between simplicity, performance, and memory efficiency.
-
Flexible Array Member Layout — Both
xBufferandxRingBufferallocate header + data in a singlemalloc()call using C99 flexible array members. This eliminates pointer indirection and improves cache locality. -
Reference-Counted Block Sharing —
xIOBufferuses reference-counted blocks that can be shared across multiple buffers. This enables zero-copy split and append operations critical for high-performance network protocols. -
I/O Integration — All three types provide
ReadFd/WriteFdhelpers that handleEINTRretries and scatter-gather I/O (readv/writev), making them ready for event-driven network programming.
Architecture
graph TD
subgraph "xbuf Module"
BUF["xBuffer<br/>Linear auto-growing<br/>Single contiguous allocation"]
RING["xRingBuffer<br/>Fixed-size circular<br/>Power-of-2 masking"]
IO["xIOBuffer<br/>Block-chain<br/>Reference-counted"]
end
subgraph "Shared Infrastructure"
POOL["Block Pool<br/>Treiber stack freelist"]
ATOMIC["xbase/atomic.h<br/>Lock-free operations"]
end
IO --> POOL
POOL --> ATOMIC
subgraph "I/O Layer"
READ["read() / readv()"]
WRITE["write() / writev()"]
end
BUF --> READ
BUF --> WRITE
RING --> READ
RING --> WRITE
IO --> READ
IO --> WRITE
style BUF fill:#4a90d9,color:#fff
style RING fill:#f5a623,color:#fff
style IO fill:#50b86c,color:#fff
Sub-Module Overview
| Header | Type | Description | Doc |
|---|---|---|---|
buf.h | xBuffer | Linear auto-growing byte buffer with flexible array member layout | buf.md |
ring.h | xRingBuffer | Fixed-size circular buffer with power-of-2 bitmask indexing | ring.md |
io.h | xIOBuffer | Reference-counted block-chain I/O buffer with zero-copy operations | io.md |
How to Choose
| Criterion | xBuffer | xRingBuffer | xIOBuffer |
|---|---|---|---|
| Memory layout | Contiguous | Contiguous (circular) | Non-contiguous (block chain) |
| Growth | Auto-growing (2x realloc) | Fixed size (never grows) | Auto-growing (new blocks) |
| Best for | Accumulating variable-length data | Fixed-capacity producer-consumer | High-throughput network I/O |
| Zero-copy split | No | No | Yes |
| Zero-copy append | No | No | Yes (between xIOBuffers) |
| Scatter-gather I/O | No (single buffer) | Yes (up to 2 iovecs) | Yes (N iovecs) |
| Memory overhead | Minimal (1 allocation) | Minimal (1 allocation) | Per-block overhead + ref array |
| Thread safety | Not thread-safe | Not thread-safe | Block pool is thread-safe |
Decision Guide
Need to accumulate data of unknown size?
→ xBuffer (simple, auto-growing)
Need a fixed-capacity FIFO between producer and consumer?
→ xRingBuffer (no allocation after creation)
Need zero-copy operations or scatter-gather I/O for networking?
→ xIOBuffer (block-chain with reference counting)
Quick Start
#include <stdio.h>
#include <x/buf/buf.h>
#include <x/buf/ring.h>
#include <x/buf/io.h>
int main(void) {
// 1. Linear buffer: accumulate data
xBuffer buf = xBufferCreate(256);
xBufferAppend(&buf, "Hello, ", 7);
xBufferAppend(&buf, "xbuf!", 5);
printf("buf: %.*s\n", (int)xBufferLen(buf), (const char *)xBufferData(buf));
xBufferDestroy(buf);
// 2. Ring buffer: fixed-capacity FIFO
xRingBuffer ring = xRingBufferCreate(1024);
xRingBufferWrite(ring, "circular", 8);
char out[16];
size_t n = xRingBufferRead(ring, out, sizeof(out));
printf("ring: %.*s\n", (int)n, out);
xRingBufferDestroy(ring);
// 3. IO buffer: block-chain with zero-copy
xIOBuffer io;
xIOBufferInit(&io);
xIOBufferAppend(&io, "block-chain I/O", 15);
char linear[64];
xIOBufferCopyTo(&io, linear);
printf("io: %.*s\n", (int)xIOBufferLen(&io), linear);
xIOBufferDeinit(&io);
return 0;
}
Relationship with Other Modules
- xbase —
xIOBufferusesatomic.hfor lock-free block pool management and reference counting. - xhttp — The HTTP client (
client.h) usesxIOBufferfor response body accumulation and SSE stream parsing. - xlog — The async logger (
logger.h) may usexBufferfor log message formatting.
buf.h — Linear Auto-Growing Buffer
Introduction
buf.h provides xBuffer, a simple contiguous byte buffer that automatically grows when more space is needed. It maintains separate read and write positions, supporting efficient append-and-consume patterns. The buffer header and data area are allocated in a single malloc() call using a C99 flexible array member, avoiding an extra pointer indirection.
Design Philosophy
-
Single Allocation — Header and data live in one contiguous block (
struct + flexible array member). This means onemalloc(), onefree(), and excellent cache locality. -
Handle Indirection — Because
realloc()may relocate the entire object, write APIs takexBuffer *bufp(pointer to handle) so the caller's handle stays valid after growth. -
Compact Before Grow — When the buffer needs more space, it first tries to compact (slide unread data to the front) before resorting to
realloc(). This reclaims consumed space without allocation. -
2x Growth — When reallocation is necessary, capacity doubles each time, providing amortized O(1) append.
Architecture
graph LR
subgraph "xBuffer Lifecycle"
CREATE["xBufferCreate(cap)"] --> USE["Append / Read / Consume"]
USE --> GROW{"Need more space?"}
GROW -->|Compact| USE
GROW -->|Realloc 2x| USE
USE --> DESTROY["xBufferDestroy()"]
end
style CREATE fill:#4a90d9,color:#fff
style DESTROY fill:#e74c3c,color:#fff
Implementation Details
Memory Layout
Single malloc() allocation:
┌──────────────────┬──────────────────────────────────────────┐
│ xBuffer_ header │ data[cap] (flexible array member) │
│ rpos, wpos, cap │ │
└──────────────────┴──────────────────────────────────────────┘
↑ ↑ ↑
data+rpos data+wpos data+cap
│←readable→│←────writable──────→│
Internal Structure
XDEF_STRUCT(xBuffer_) {
size_t rpos; // Read position (start of unread data)
size_t wpos; // Write position (end of unread data)
size_t cap; // Total data capacity
char data[]; // Flexible array member
};
Growth Strategy
flowchart TD
APPEND["xBufferAppend(bufp, data, len)"]
CHECK{"wpos + len <= cap?"}
WRITE["memcpy at wpos, advance wpos"]
COMPACT{"rpos > 0 AND<br/>unread + len <= cap?"}
MEMMOVE["memmove data to front<br/>rpos=0, wpos=unread"]
REALLOC["realloc(cap * 2)"]
UPDATE["Update *bufp"]
APPEND --> CHECK
CHECK -->|Yes| WRITE
CHECK -->|No| COMPACT
COMPACT -->|Yes| MEMMOVE --> WRITE
COMPACT -->|No| REALLOC --> UPDATE --> WRITE
style WRITE fill:#50b86c,color:#fff
style REALLOC fill:#f5a623,color:#fff
Operations and Complexity
| Operation | Time Complexity | Notes |
|---|---|---|
xBufferAppend | Amortized O(1) per byte | May trigger compact or realloc |
xBufferConsume | O(1) | Advances read position |
xBufferCompact | O(n) | memmove of unread data |
xBufferData | O(1) | Returns data + rpos |
xBufferLen | O(1) | Returns wpos - rpos |
xBufferReadFd | O(1) | Single read() syscall |
xBufferWriteFd | O(1) | Single write() syscall |
API Reference
Lifecycle
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xBufferCreate | xBuffer xBufferCreate(size_t initial_cap) | Create a buffer. Min capacity is 64. | Not thread-safe |
xBufferDestroy | void xBufferDestroy(xBuffer buf) | Free the buffer. NULL is a no-op. | Not thread-safe |
xBufferReset | void xBufferReset(xBuffer buf) | Discard all data, keep memory. | Not thread-safe |
Write
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xBufferAppend | xErrno xBufferAppend(xBuffer *bufp, const void *data, size_t len) | Append bytes, growing if needed. | Not thread-safe |
xBufferAppendStr | xErrno xBufferAppendStr(xBuffer *bufp, const char *str) | Append a C string (excluding NUL). | Not thread-safe |
xBufferReserve | xErrno xBufferReserve(xBuffer *bufp, size_t additional) | Ensure at least additional writable bytes. | Not thread-safe |
Read
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xBufferData | const void *xBufferData(xBuffer buf) | Pointer to readable data. Valid until next mutation. | Not thread-safe |
xBufferLen | size_t xBufferLen(xBuffer buf) | Number of readable bytes. | Not thread-safe |
xBufferCap | size_t xBufferCap(xBuffer buf) | Total allocated capacity. | Not thread-safe |
xBufferWritable | size_t xBufferWritable(xBuffer buf) | Writable bytes (cap - wpos). | Not thread-safe |
xBufferConsume | void xBufferConsume(xBuffer buf, size_t n) | Advance read position by n bytes. | Not thread-safe |
xBufferCompact | void xBufferCompact(xBuffer buf) | Move unread data to front, maximize writable space. | Not thread-safe |
I/O Helpers
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xBufferReadFd | ssize_t xBufferReadFd(xBuffer *bufp, int fd) | Read from fd into buffer (ensures 4KB space). | Not thread-safe |
xBufferWriteFd | ssize_t xBufferWriteFd(xBuffer buf, int fd) | Write readable data to fd, consume written bytes. | Not thread-safe |
Usage Examples
Basic Append and Read
#include <stdio.h>
#include <x/buf/buf.h>
int main(void) {
xBuffer buf = xBufferCreate(256);
// Append data
xBufferAppend(&buf, "Hello, ", 7);
xBufferAppendStr(&buf, "World!");
// Read data
printf("Content: %.*s\n", (int)xBufferLen(buf),
(const char *)xBufferData(buf));
// Output: Content: Hello, World!
// Consume partial data
xBufferConsume(buf, 7);
printf("After consume: %.*s\n", (int)xBufferLen(buf),
(const char *)xBufferData(buf));
// Output: After consume: World!
// Compact to reclaim consumed space
xBufferCompact(buf);
xBufferDestroy(buf);
return 0;
}
Network I/O
#include <x/buf/buf.h>
#include <unistd.h>
void handle_connection(int sockfd) {
xBuffer buf = xBufferCreate(4096);
// Read from socket
ssize_t n = xBufferReadFd(&buf, sockfd);
if (n > 0) {
// Process data...
// Write response back
xBufferAppendStr(&buf, "HTTP/1.1 200 OK\r\n\r\n");
xBufferWriteFd(buf, sockfd);
}
xBufferDestroy(buf);
}
Use Cases
-
HTTP Response Accumulation — Accumulate response body chunks of unknown total size. The auto-growing behavior handles variable-length responses.
-
Protocol Parsing — Append incoming data, parse complete messages from the front, consume parsed bytes. The compact operation reclaims space without reallocation.
-
Log Message Formatting — Build log messages incrementally with multiple append calls before flushing.
Best Practices
- Always pass
&bufto write APIs. Functions that may grow the buffer takexBuffer *bufpbecauserealloc()may relocate the object. - Call
xBufferCompact()periodically if you consume data incrementally. This avoids unnecessary reallocation by reclaiming consumed space. - Check return values.
xBufferAppend()andxBufferReserve()returnxErrno_NoMemoryon allocation failure. - Don't cache
xBufferData()pointers across mutating calls. Any append/reserve/compact may invalidate the pointer.
Comparison with Other Libraries
| Feature | xbuf buf.h | Go bytes.Buffer | Rust Vec<u8> | C++ std::vector<char> |
|---|---|---|---|---|
| Layout | Header + data in one allocation (FAM) | Separate header + slice | Heap-allocated array | Heap-allocated array |
| Growth | 2x realloc + compact | 2x (with copy) | 2x (with copy) | Implementation-defined |
| Read/Write cursors | Yes (rpos/wpos) | Yes (read offset) | No (manual tracking) | No (manual tracking) |
| Compact | Built-in (xBufferCompact) | Built-in (implicit) | Manual | Manual |
| I/O helpers | ReadFd/WriteFd | ReadFrom/WriteTo | Via Read/Write traits | No |
| Handle invalidation | Caller updates via *bufp | GC handles | Borrow checker | Iterator invalidation |
Key Differentiator: xBuffer's single-allocation layout (flexible array member) eliminates one level of pointer indirection compared to typical buffer implementations. The compact-before-grow strategy minimizes reallocation frequency for append-consume workloads.
Benchmark
Environment: Apple M3 Pro, 36 GB RAM, macOS 26.4, Release build (
-O2). Source:xbuf/buf_bench.cpp
| Benchmark | Chunk Size | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Buffer_Append | 16 | 4,776 | 4,776 | 3.1 GiB/s |
BM_Buffer_Append | 64 | 4,400 | 4,400 | 13.5 GiB/s |
BM_Buffer_Append | 256 | 7,892 | 7,892 | 30.2 GiB/s |
BM_Buffer_Append | 1,024 | 21,834 | 21,811 | 43.7 GiB/s |
BM_Buffer_Append | 4,096 | 91,029 | 90,958 | 41.9 GiB/s |
BM_Buffer_AppendConsume | 64 | 4,999 | 4,999 | 11.9 GiB/s |
BM_Buffer_AppendConsume | 256 | 8,241 | 8,240 | 28.9 GiB/s |
BM_Buffer_AppendConsume | 1,024 | 22,859 | 22,859 | 41.7 GiB/s |
Key Observations:
- Append throughput peaks at ~44 GiB/s for 1KB chunks, limited by
memcpybandwidth and reallocation overhead. - AppendConsume (interleaved append + consume) achieves comparable throughput to pure append, validating the compact-before-grow strategy — consumed space is reclaimed without reallocation.
- Small chunks (16B) show lower throughput due to per-call overhead dominating the
memcpycost.
ring.h — Fixed-Size Ring Buffer
Introduction
ring.h provides xRingBuffer, a fixed-capacity circular buffer that never reallocates. It is ideal for bounded producer-consumer scenarios where a fixed memory budget is required. The capacity is rounded up to the next power of two internally, enabling bitmask indexing instead of expensive modulo operations.
Design Philosophy
-
Fixed Capacity, Zero Reallocation — Once created, the ring buffer never grows. Writes that exceed capacity are truncated to the available space (partial write). This makes memory usage predictable and avoids allocation latency spikes.
-
Power-of-Two Masking — The internal capacity is always a power of two. Index computation uses
head & maskinstead ofhead % cap, which is significantly faster on most architectures. -
Monotonic Cursors —
head(write) andtail(read) grow monotonically and never wrap. The actual array index is computed via bitmask. This simplifies the full/empty distinction:head - tailgives the exact readable byte count. -
Single Allocation — Like
xBuffer, the header and data area are allocated together using a flexible array member. -
Scatter-Gather I/O — The ring buffer provides
ReadIov/WriteIovhelpers that filliovecarrays for efficientreadv()/writev()syscalls, handling the wrap-around transparently.
Architecture
graph LR
PRODUCER["Producer"] -->|"xRingBufferWrite"| RB["xRingBuffer<br/>(fixed capacity)"]
RB -->|"xRingBufferRead"| CONSUMER["Consumer"]
RB -->|"xRingBufferReadIov"| IOV1["iovec[2]"] -->|"writev()"| FD1["fd"]
FD2["fd"] -->|"readv()"| IOV2["iovec[2]"] -->|"xRingBufferWriteIov"| RB
style RB fill:#f5a623,color:#fff
Implementation Details
Memory Layout
Single malloc() allocation:
┌───────────────────────┬──────────────────────────────────────┐
│ xRingBuffer_ header │ data[cap] (flexible array member) │
│ cap, mask, head, tail│ │
└───────────────────────┴──────────────────────────────────────┘
Circular data layout (cap=8, mask=7):
tail & mask head & mask
↓ ↓
┌───┬───┬───┬───┬───┬───┬───┬───┐
│ │ │ R │ R │ R │ W │ │ │
└───┴───┴───┴───┴───┴───┴───┴───┘
0 1 2 3 4 5 6 7
R = readable data (tail..head)
W = next write position
Internal Structure
XDEF_STRUCT(xRingBuffer_) {
size_t cap; // Capacity (power of two)
size_t mask; // cap - 1 (for bitmask indexing)
size_t head; // Write cursor (monotonic)
size_t tail; // Read cursor (monotonic)
char data[];// Flexible array member
};
Power-of-Two Rounding
static size_t next_pow2(size_t v) {
if (v < 16) v = 16;
v--;
v |= v >> 1;
v |= v >> 2;
v |= v >> 4;
v |= v >> 8;
v |= v >> 16;
// v |= v >> 32; (on 64-bit)
return v + 1;
}
This ensures cap is always a power of two, so mask = cap - 1 produces a valid bitmask. For example, cap = 8 → mask = 0b111.
Bitmask Indexing
Instead of:
size_t idx = head % cap; // Expensive division
The ring buffer uses:
size_t idx = head & mask; // Single AND instruction
This works because cap is a power of two: x % (2^n) == x & (2^n - 1).
Wrap-Around Write
flowchart TD
WRITE["xRingBufferWrite(rb, data, len)"]
CHECK{"len <= writable?"}
CLAMP["len = writable"]
POS["pos = head & mask"]
FIRST["first = cap - pos"]
WRAP{"len <= first?"}
SINGLE["memcpy(data+pos, src, len)"]
SPLIT["memcpy(data+pos, src, first)<br/>memcpy(data, src+first, len-first)"]
ADVANCE["head += len<br/>return len"]
ZERO["return 0"]
WRITE --> CHECK
CHECK -->|No| CLAMP --> POS
CHECK -->|Yes| POS
CHECK -->|writable == 0| ZERO
POS --> FIRST --> WRAP
WRAP -->|Yes| SINGLE --> ADVANCE
WRAP -->|No| SPLIT --> ADVANCE
style ZERO fill:#e74c3c,color:#fff
style ADVANCE fill:#50b86c,color:#fff
Operations and Complexity
| Operation | Time Complexity | Notes |
|---|---|---|
xRingBufferWrite | O(n) | Up to 2 memcpy calls |
xRingBufferRead | O(n) | Up to 2 memcpy calls |
xRingBufferPeek | O(n) | Like Read but doesn't advance tail |
xRingBufferDiscard | O(1) | Just advances tail |
xRingBufferLen | O(1) | head - tail |
xRingBufferReadFd | O(1) | Single readv() syscall |
xRingBufferWriteFd | O(1) | Single writev() syscall |
API Reference
Lifecycle
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xRingBufferCreate | xRingBuffer xRingBufferCreate(size_t min_cap) | Create a ring buffer. Capacity rounded up to power of 2. | Not thread-safe |
xRingBufferDestroy | void xRingBufferDestroy(xRingBuffer rb) | Free the ring buffer. NULL is a no-op. | Not thread-safe |
xRingBufferReset | void xRingBufferReset(xRingBuffer rb) | Discard all data, keep memory. | Not thread-safe |
Query
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xRingBufferLen | size_t xRingBufferLen(xRingBuffer rb) | Readable bytes. | Not thread-safe |
xRingBufferCap | size_t xRingBufferCap(xRingBuffer rb) | Total capacity. | Not thread-safe |
xRingBufferWritable | size_t xRingBufferWritable(xRingBuffer rb) | Writable bytes. | Not thread-safe |
xRingBufferEmpty | bool xRingBufferEmpty(xRingBuffer rb) | True if no readable data. | Not thread-safe |
xRingBufferFull | bool xRingBufferFull(xRingBuffer rb) | True if no writable space. | Not thread-safe |
Write
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xRingBufferWrite | size_t xRingBufferWrite(xRingBuffer rb, const void *data, size_t len) | Write bytes. Returns number of bytes actually written (partial write if full). | Not thread-safe |
Read
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xRingBufferRead | size_t xRingBufferRead(xRingBuffer rb, void *out, size_t len) | Read and consume bytes. Returns actual count. | Not thread-safe |
xRingBufferPeek | size_t xRingBufferPeek(xRingBuffer rb, void *out, size_t len) | Read without consuming. | Not thread-safe |
xRingBufferDiscard | size_t xRingBufferDiscard(xRingBuffer rb, size_t n) | Discard bytes without copying. | Not thread-safe |
I/O Helpers
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xRingBufferReadIov | int xRingBufferReadIov(xRingBuffer rb, struct iovec iov[2]) | Fill iovecs with readable regions (for writev). | Not thread-safe |
xRingBufferWriteIov | int xRingBufferWriteIov(xRingBuffer rb, struct iovec iov[2]) | Fill iovecs with writable regions (for readv). | Not thread-safe |
xRingBufferReadFd | ssize_t xRingBufferReadFd(xRingBuffer rb, int fd) | Read from fd using readv(). | Not thread-safe |
xRingBufferWriteFd | ssize_t xRingBufferWriteFd(xRingBuffer rb, int fd) | Write to fd using writev(). | Not thread-safe |
Usage Examples
Basic FIFO
#include <stdio.h>
#include <x/buf/ring.h>
int main(void) {
// Request 1000 bytes; actual capacity will be 1024 (next power of 2)
xRingBuffer rb = xRingBufferCreate(1000);
printf("Capacity: %zu\n", xRingBufferCap(rb)); // 1024
// Write data
const char *msg = "Hello, Ring!";
xRingBufferWrite(rb, msg, 12);
// Read data
char out[32];
size_t n = xRingBufferRead(rb, out, sizeof(out));
printf("Read %zu bytes: %.*s\n", n, (int)n, out);
xRingBufferDestroy(rb);
return 0;
}
Network Socket Buffer
#include <x/buf/ring.h>
void event_loop_handler(int sockfd) {
xRingBuffer rb = xRingBufferCreate(65536); // 64KB ring
// Read from socket into ring buffer
ssize_t n = xRingBufferReadFd(rb, sockfd);
if (n > 0) {
// Process data...
// Write processed data back
xRingBufferWriteFd(rb, sockfd);
}
xRingBufferDestroy(rb);
}
Use Cases
-
Fixed-Budget Network Buffers — When you need predictable memory usage per connection (e.g., 64KB per socket), the ring buffer provides a hard capacity limit.
-
Logging Ring Buffer — Capture the last N bytes of log output, automatically discarding old data when the buffer wraps.
-
Inter-Thread Communication — With external synchronization, a ring buffer can serve as a bounded channel between producer and consumer threads.
Best Practices
- Choose capacity carefully. The ring buffer never grows. If you write more than the available space, only a partial write is performed. Size it for your worst-case scenario.
- Use scatter-gather I/O.
xRingBufferReadFd/WriteFdusereadv()/writev()to handle wrap-around in a single syscall, avoiding the need to linearize data. - Be aware of power-of-two rounding. Requesting 1000 bytes gives you 1024. Requesting 1025 gives you 2048. Plan accordingly.
- Check the return value of
xRingBufferWrite()to detect partial writes and handle back-pressure.
Comparison with Other Libraries
| Feature | xbuf ring.h | Linux kfifo | Boost circular_buffer | DPDK rte_ring |
|---|---|---|---|---|
| Capacity | Fixed, power-of-2 | Fixed, power-of-2 | Fixed, any size | Fixed, power-of-2 |
| Indexing | Bitmask | Bitmask | Modulo | Bitmask |
| Layout | FAM (single alloc) | Separate alloc | Heap array | Huge pages |
| Thread Safety | Not thread-safe | Single-producer/single-consumer | Not thread-safe | Multi-producer/multi-consumer |
| I/O Helpers | readv/writev | kfifo_to_user/kfifo_from_user | No | No (packet-oriented) |
| Language | C99 | C (kernel) | C++ | C |
Key Differentiator: xbuf's ring buffer combines the power-of-two bitmask optimization (like kfifo) with scatter-gather I/O helpers (readv/writev) in a single-allocation design. It's purpose-built for event-driven network programming where fixed memory budgets and efficient syscalls are essential.
Benchmark
Environment: Apple M3 Pro, 36 GB RAM, macOS 26.4, Release build (
-O2). Source:xbuf/ring_bench.cpp
| Benchmark | Size | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_Ring_WriteRead | 64 | 6.05 | 6.05 | 19.7 GiB/s |
BM_Ring_WriteRead | 256 | 16.8 | 16.8 | 28.4 GiB/s |
BM_Ring_WriteRead | 1,024 | 27.4 | 27.4 | 69.6 GiB/s |
BM_Ring_WriteRead | 4,096 | 99.2 | 99.2 | 76.9 GiB/s |
BM_Ring_Throughput | 4,096 | 225 | 225 | 17.0 GiB/s |
BM_Ring_Throughput | 16,384 | 806 | 806 | 18.9 GiB/s |
BM_Ring_Throughput | 65,536 | 3,198 | 3,198 | 19.1 GiB/s |
Key Observations:
- WriteRead (single write + read cycle) achieves up to ~77 GiB/s at 4KB chunks, demonstrating the efficiency of the bitmask-based wrap-around and
memcpyfor larger transfers. - Throughput (sustained writes until full) stabilizes at ~19 GiB/s regardless of capacity, showing consistent performance as the ring scales.
- The ring buffer's zero-overhead indexing (bitmask instead of modulo) keeps per-operation cost extremely low — just 6ns for a 64-byte write+read cycle.
io.h — Reference-Counted Block-Chain I/O Buffer
Introduction
io.h provides xIOBuffer, a non-contiguous byte buffer composed of a chain of reference-counted memory blocks. It supports zero-copy split, append, and scatter-gather I/O (readv/writev). Inspired by brpc's IOBuf, it is designed for high-throughput network I/O where avoiding memory copies is critical.
Design Philosophy
-
Block-Chain Architecture — Data is stored across multiple fixed-size blocks (default 8KB each), linked through a reference array. This avoids large contiguous allocations and enables zero-copy operations.
-
Reference Counting — Each
xIOBlockis reference-counted. MultiplexIOBufferinstances can share the same block (e.g., after aCutoperation). Blocks are freed (returned to pool) when the last reference is released. -
Zero-Copy Operations —
xIOBufferAppendIOBuffer()transfers block references without copying data.xIOBufferCut()splits a buffer by adjusting offsets and sharing blocks at the boundary. -
Lock-Free Block Pool — Released blocks are returned to a global Treiber stack (lock-free) for reuse, avoiding
malloc/freeoverhead in steady state. -
Inline Ref Array — Small buffers (≤ 8 refs) use an inline array, avoiding heap allocation for the ref array itself. Larger buffers transition to a heap-allocated array.
Architecture
graph TD
subgraph "xIOBuffer API"
APPEND["Append / AppendStr"]
APPEND_IO["AppendIOBuffer<br/>(zero-copy)"]
READ["Read / CopyTo"]
CUT["Cut<br/>(zero-copy split)"]
CONSUME["Consume"]
IO_READ["ReadFd"]
IO_WRITE["WriteFd<br/>(writev)"]
end
subgraph "Block Management"
ACQUIRE["xIOBlockAcquire"]
RETAIN["xIOBlockRetain"]
RELEASE["xIOBlockRelease"]
end
subgraph "Block Pool (Treiber Stack)"
POOL["g_pool_head"]
WARMUP["xIOBlockPoolWarmup"]
DRAIN["xIOBlockPoolDrain"]
end
APPEND --> ACQUIRE
IO_READ --> ACQUIRE
CUT --> RETAIN
CONSUME --> RELEASE
READ --> RELEASE
ACQUIRE --> POOL
RELEASE --> POOL
WARMUP --> POOL
DRAIN --> POOL
style POOL fill:#f5a623,color:#fff
Implementation Details
Block Structure
XDEF_STRUCT(xIOBlock) {
size_t refs; // Reference count (atomic)
size_t size; // Usable data size
char data[XIOBUFFER_BLOCK_SIZE]; // 8KB inline data
};
Reference Structure
XDEF_STRUCT(xIOBufferRef) {
xIOBlock *block; // Pointer to the underlying block
size_t offset; // Start offset within block->data
size_t length; // Number of valid bytes from offset
};
IOBuffer Structure
XDEF_STRUCT(xIOBuffer) {
xIOBufferRef inlined[XIOBUFFER_INLINE_REFS]; // Inline ref storage (8)
xIOBufferRef *refs; // Pointer to ref array (inlined or heap)
size_t nrefs; // Number of active refs
size_t cap; // Capacity of refs array
size_t nbytes; // Total logical byte count (cached)
};
Block-Chain Architecture
graph TD
subgraph "xIOBuffer"
REF1["Ref 0<br/>block=A, off=0, len=8192"]
REF2["Ref 1<br/>block=B, off=0, len=8192"]
REF3["Ref 2<br/>block=C, off=0, len=3000"]
end
subgraph "Shared Blocks"
A["xIOBlock A<br/>refs=1, 8KB"]
B["xIOBlock B<br/>refs=2, 8KB"]
C["xIOBlock C<br/>refs=1, 8KB"]
end
REF1 --> A
REF2 --> B
REF3 --> C
subgraph "Another xIOBuffer (after Cut)"
REF4["Ref 0<br/>block=B, off=4096, len=4096"]
end
REF4 --> B
style A fill:#4a90d9,color:#fff
style B fill:#f5a623,color:#fff
style C fill:#50b86c,color:#fff
Treiber Stack Block Pool
The global block pool uses a lock-free Treiber stack:
// Pool node overlays xIOBlock memory
XDEF_STRUCT(PoolNode_) {
PoolNode_ *next;
};
static PoolNode_ *volatile g_pool_head = NULL;
Push (return to pool):
do {
head = atomic_load(g_pool_head)
node->next = head
} while (!CAS(g_pool_head, head, node))
Pop (acquire from pool):
do {
head = atomic_load(g_pool_head)
if (!head) return malloc(new block)
next = head->next
} while (!CAS(g_pool_head, head, next))
return head
Zero-Copy Cut
xIOBufferCut(io, dst, n) moves the first n bytes from io to dst:
- Fully consumed refs — Ownership transfers directly (no refcount change).
- Boundary ref — The block is shared:
xIOBlockRetain()increments the refcount, and both buffers hold a ref with different offset/length.
flowchart TD
CUT["xIOBufferCut(io, dst, n)"]
LOOP{"More bytes to cut?"}
FULL{"ref.length <= remaining?"}
TRANSFER["Transfer entire ref to dst<br/>(no refcount change)"]
SPLIT["Share block: Retain + split ref<br/>dst gets [offset, chunk]<br/>io keeps [offset+chunk, rest]"]
SHIFT["Shift consumed refs out of io"]
DONE["Update nbytes for both"]
CUT --> LOOP
LOOP -->|Yes| FULL
FULL -->|Yes| TRANSFER --> LOOP
FULL -->|No| SPLIT --> SHIFT --> DONE
LOOP -->|No| SHIFT
style TRANSFER fill:#50b86c,color:#fff
style SPLIT fill:#f5a623,color:#fff
Append Strategy
xIOBufferAppend(io, data, len):
- First tries to fill the tail block's remaining space (avoids allocating a new block for small appends).
- Allocates new blocks for remaining data, each up to
XIOBUFFER_BLOCK_SIZEbytes.
API Reference
Configuration
| Macro | Default | Description |
|---|---|---|
XIOBUFFER_BLOCK_SIZE | 8192 | Block data size in bytes |
XIOBUFFER_INLINE_REFS | 8 | Inline ref array capacity |
Block API
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xIOBlockAcquire | xIOBlock *xIOBlockAcquire(void) | Get a block from pool (or malloc). refs=1. | Thread-safe (lock-free pool) |
xIOBlockRetain | void xIOBlockRetain(xIOBlock *blk) | Increment refcount. | Thread-safe (atomic) |
xIOBlockRelease | void xIOBlockRelease(xIOBlock *blk) | Decrement refcount; return to pool at 0. | Thread-safe (atomic + lock-free pool) |
xIOBlockPoolWarmup | xErrno xIOBlockPoolWarmup(size_t n) | Pre-allocate n blocks into pool. | Thread-safe |
xIOBlockPoolDrain | void xIOBlockPoolDrain(void) | Free all pooled blocks. Call at shutdown. | Not thread-safe (no concurrent use) |
IOBuffer Lifecycle
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xIOBufferInit | void xIOBufferInit(xIOBuffer *io) | Initialize an empty IOBuffer. | Not thread-safe |
xIOBufferDeinit | void xIOBufferDeinit(xIOBuffer *io) | Release all refs and free ref array. | Not thread-safe |
xIOBufferReset | void xIOBufferReset(xIOBuffer *io) | Release all refs, keep ref array. | Not thread-safe |
IOBuffer Query
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xIOBufferLen | size_t xIOBufferLen(const xIOBuffer *io) | Total readable bytes. | Not thread-safe |
xIOBufferEmpty | bool xIOBufferEmpty(const xIOBuffer *io) | True if no data. | Not thread-safe |
xIOBufferRefCount | size_t xIOBufferRefCount(const xIOBuffer *io) | Number of block refs. | Not thread-safe |
IOBuffer Write
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xIOBufferAppend | xErrno xIOBufferAppend(xIOBuffer *io, const void *data, size_t len) | Append bytes (allocates blocks as needed). | Not thread-safe |
xIOBufferAppendStr | xErrno xIOBufferAppendStr(xIOBuffer *io, const char *str) | Append C string. | Not thread-safe |
xIOBufferAppendIOBuffer | xErrno xIOBufferAppendIOBuffer(xIOBuffer *io, xIOBuffer *other) | Zero-copy: move all refs from other. | Not thread-safe |
IOBuffer Read
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xIOBufferRead | size_t xIOBufferRead(xIOBuffer *io, void *out, size_t len) | Copy and consume bytes. | Not thread-safe |
xIOBufferCut | size_t xIOBufferCut(xIOBuffer *io, xIOBuffer *dst, size_t n) | Zero-copy split: move first n bytes to dst. | Not thread-safe |
xIOBufferConsume | size_t xIOBufferConsume(xIOBuffer *io, size_t n) | Discard first n bytes. | Not thread-safe |
xIOBufferCopyTo | size_t xIOBufferCopyTo(const xIOBuffer *io, void *out) | Linearize: copy all data to contiguous buffer. | Not thread-safe |
IOBuffer I/O
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xIOBufferReadIov | int xIOBufferReadIov(const xIOBuffer *io, struct iovec *iov, int max_iov) | Fill iovecs for writev(). | Not thread-safe |
xIOBufferReadFd | ssize_t xIOBufferReadFd(xIOBuffer *io, int fd) | Read from fd into IOBuffer. | Not thread-safe |
xIOBufferWriteFd | ssize_t xIOBufferWriteFd(xIOBuffer *io, int fd) | Write to fd using writev(). | Not thread-safe |
Usage Examples
Basic Usage
#include <stdio.h>
#include <x/buf/io.h>
int main(void) {
xIOBuffer io;
xIOBufferInit(&io);
// Append data (may span multiple blocks)
xIOBufferAppend(&io, "Hello, ", 7);
xIOBufferAppend(&io, "IOBuffer!", 9);
printf("Length: %zu, Refs: %zu\n",
xIOBufferLen(&io), xIOBufferRefCount(&io));
// Linearize for processing
char buf[64];
xIOBufferCopyTo(&io, buf);
printf("Content: %.*s\n", (int)xIOBufferLen(&io), buf);
xIOBufferDeinit(&io);
return 0;
}
Zero-Copy Split (Protocol Parsing)
#include <x/buf/io.h>
void parse_protocol(xIOBuffer *io) {
// Cut the 4-byte header from the front
xIOBuffer header;
xIOBufferInit(&header);
size_t cut = xIOBufferCut(io, &header, 4);
if (cut == 4) {
char hdr[4];
xIOBufferRead(&header, hdr, 4);
// Parse header...
// io now contains only the body (zero-copy!)
}
xIOBufferDeinit(&header);
}
High-Throughput Network I/O
#include <x/buf/io.h>
void handle_data(int sockfd) {
// Pre-warm the block pool at startup
xIOBlockPoolWarmup(64);
xIOBuffer io;
xIOBufferInit(&io);
// Read from socket (allocates blocks from pool)
ssize_t n = xIOBufferReadFd(&io, sockfd);
if (n > 0) {
// Write back using scatter-gather I/O
xIOBufferWriteFd(&io, sockfd);
}
xIOBufferDeinit(&io);
// At shutdown
xIOBlockPoolDrain();
}
Use Cases
-
HTTP Response Body — The
xhttpmodule usesxIOBufferto accumulate response chunks from libcurl without copying between buffers. -
Protocol Framing — Use
xIOBufferCut()to split headers from body in a zero-copy fashion, then process each part independently. -
Data Pipeline — Chain multiple processing stages that each append to or cut from
xIOBufferinstances, sharing blocks to minimize copies.
Best Practices
- Call
xIOBlockPoolWarmup()at startup to pre-allocate blocks and avoid allocation spikes during initial traffic. - Call
xIOBlockPoolDrain()at shutdown for clean valgrind reports. - Use
xIOBufferAppendIOBuffer()instead of copying when combining buffers. It transfers ownership without data copies. - Use
xIOBufferCut()for protocol parsing. It's more efficient thanxIOBufferRead()when you need to pass the cut data to another component. - Monitor
xIOBufferRefCount()to understand memory fragmentation. Many small refs may indicate suboptimal block utilization.
Comparison with Other Libraries
| Feature | xbuf io.h | brpc IOBuf | Netty ByteBuf | Go bytes.Buffer |
|---|---|---|---|---|
| Architecture | Block-chain (ref array) | Block-chain (linked list) | Composite buffer | Contiguous slice |
| Block Size | 8KB (configurable) | 8KB | Configurable | N/A |
| Reference Counting | Atomic (per block) | Atomic (per block) | Atomic (per buffer) | GC |
| Zero-Copy Split | xIOBufferCut | cutn | slice | No |
| Zero-Copy Append | xIOBufferAppendIOBuffer | append(IOBuf) | addComponent | No |
| Block Pool | Treiber stack (lock-free) | Thread-local + global | Arena allocator | N/A |
| Scatter-Gather I/O | writev via ReadIov | writev via pappend | nioBuffers | No |
| Inline Optimization | 8 inline refs | No | No | N/A |
| Language | C99 | C++ | Java | Go |
Key Differentiator: xbuf's xIOBuffer combines brpc-style block-chain architecture with a lock-free Treiber stack block pool and inline ref optimization. The zero-copy Cut and AppendIOBuffer operations make it ideal for protocol parsing and data pipeline scenarios in C.
Benchmark
Environment: Apple M3 Pro, 36 GB RAM, macOS 26.4, Release build (
-O2). Source:xbuf/io_bench.cpp
| Benchmark | Size | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|---|
BM_IOBuffer_Append | 64 | 3,720 | 3,720 | 16.0 GiB/s |
BM_IOBuffer_Append | 256 | 7,569 | 7,568 | 31.5 GiB/s |
BM_IOBuffer_Append | 1,024 | 22,341 | 22,340 | 42.7 GiB/s |
BM_IOBuffer_Append | 4,096 | 79,796 | 79,794 | 47.8 GiB/s |
BM_IOBuffer_Append | 8,192 | 187,167 | 187,165 | 40.8 GiB/s |
BM_IOBuffer_AppendConsume | 64 | 5,230 | 5,230 | 11.4 GiB/s |
BM_IOBuffer_AppendConsume | 256 | 8,232 | 8,232 | 29.0 GiB/s |
BM_IOBuffer_AppendConsume | 1,024 | 23,040 | 23,040 | 41.4 GiB/s |
BM_IOBuffer_Cut | 8,192 | 167 | 167 | 45.6 GiB/s |
BM_IOBuffer_Cut | 65,536 | 1,651 | 1,651 | 37.0 GiB/s |
BM_IOBuffer_Cut | 262,144 | 8,122 | 8,122 | 30.1 GiB/s |
BM_IOBuffer_AppendIOBuffer | 1,024 | 3,196 | 3,196 | 29.8 GiB/s |
BM_IOBuffer_AppendIOBuffer | 4,096 | 9,307 | 9,307 | 41.0 GiB/s |
BM_IOBuffer_AppendIOBuffer | 8,192 | 17,604 | 17,602 | 43.3 GiB/s |
BM_IOBuffer_BlockPool | — | 8.91 | 8.89 | — |
Key Observations:
- Append peaks at ~48 GiB/s for 4KB chunks. The slight drop at 8KB reflects block boundary crossing overhead.
- Cut (zero-copy split) is extremely fast — 167ns for 8KB — because it only manipulates reference metadata, not data. This validates the block-chain architecture for protocol parsing.
- AppendIOBuffer (zero-copy concatenation) achieves ~43 GiB/s, confirming that block ownership transfer avoids data copies.
- BlockPool acquire/release cycle takes ~9ns, showing the lock-free Treiber stack's efficiency for block recycling.
xnet — Networking Primitives
Introduction
xnet is moo's networking utility module, providing three foundational components for network programming: a lightweight URL parser, an asynchronous DNS resolver, and shared TLS configuration types. These building blocks are used internally by higher-level modules like xhttp, and are also available for direct use in application code.
Design Philosophy
-
Zero-Copy URL Parsing —
xUrlParse()makes a single internal copy of the input string. All component fields (scheme, host, port, etc.) are pointer+length pairs referencing this copy, avoiding per-field allocations. -
Async DNS via Thread-Pool Offload — DNS resolution uses
getaddrinfo()offloaded to the event loop's thread pool. The callback is always invoked on the event loop thread, keeping the async programming model consistent with the rest of moo. -
Shared TLS Types —
xTlsConfis a plain data structure shared across modules. It decouples TLS configuration from any specific TLS backend (OpenSSL, mbedTLS). -
Async TCP with Transport Abstraction —
xTcpConnectchains DNS → connect → optional TLS handshake into a single async operation.xTcpConnwraps anxSocket+xTransportvtable, providingRecv/Send/SendIovhelpers that work transparently over plain TCP or TLS.
Architecture
graph TD
subgraph "xnet Module"
URL["xUrl<br/>URL Parser<br/>url.h"]
DNS["xDnsResolve<br/>Async DNS<br/>dns.h"]
TLS["xTlsConf<br/>TLS Config Types<br/>tls.h"]
TCP["xTcpConn / xTcpConnect / xTcpListener<br/>Async TCP<br/>tcp.h"]
end
subgraph "xbase Infrastructure"
EV["xEventLoop<br/>event.h"]
POOL["Thread Pool<br/>xEventLoopSubmit()"]
ATOMIC["Atomic Ops<br/>atomic.h"]
end
subgraph "Consumers"
HTTP_C["xhttp Client"]
HTTP_S["xhttp Server"]
WS["WebSocket"]
end
DNS --> EV
DNS --> POOL
DNS --> ATOMIC
TCP --> EV
TCP --> DNS
TCP --> TLS
HTTP_C --> URL
HTTP_C --> TCP
HTTP_S --> TCP
WS --> URL
WS --> TCP
style URL fill:#4a90d9,color:#fff
style DNS fill:#50b86c,color:#fff
style TLS fill:#f5a623,color:#fff
style TCP fill:#e74c3c,color:#fff
Sub-Module Overview
| Header | Component | Description | Doc |
|---|---|---|---|
url.h | xUrl | Lightweight URL parser | url.md |
dns.h | xDnsResolve | Async DNS resolution | dns.md |
tls.h | xTlsConf | Shared TLS config types | tls.md |
tcp.h | xTcpConn / xTcpConnect / xTcpListener | Async TCP connection, connector & listener | tcp.md |
Quick Start
#include <stdio.h>
#include <x/base/event.h>
#include <x/net/url.h>
#include <x/net/dns.h>
#include <x/net/tls.h>
// 1. Parse a URL
static void url_example(void) {
xUrl url;
xErrno err = xUrlParse(
"wss://example.com:8443/ws?token=abc", &url);
if (err == xErrno_Ok) {
printf("scheme: %.*s\n",
(int)url.scheme_len, url.scheme);
printf("host: %.*s\n",
(int)url.host_len, url.host);
printf("port: %u\n", xUrlPort(&url));
printf("path: %.*s\n",
(int)url.path_len, url.path);
xUrlFree(&url);
}
}
// 2. Async DNS resolution
static void on_resolved(xDnsResult *result, void *arg) {
(void)arg;
if (result->error == xErrno_Ok) {
int count = 0;
for (xDnsAddr *a = result->addrs; a; a = a->next)
count++;
printf("Resolved %d address(es)\n", count);
}
xDnsResultFree(result);
// stop the loop after resolution
}
static void dns_example(xEventLoop loop) {
xDnsResolve(loop, "example.com", "443",
NULL, on_resolved, NULL);
}
// 3. TLS configuration
static void tls_example(void) {
xTlsConf client_tls = {0};
client_tls.ca = "ca.pem";
xTlsConf server_tls = {
.cert = "server.pem",
.key = "server-key.pem",
};
(void)client_tls;
(void)server_tls;
}
Relationship with Other Modules
- xbase — The DNS resolver depends on
xEventLoopfor thread-pool offload and usesatomic.hfor the cancellation flag. - xhttp — The HTTP client uses
xUrlfor URL parsing,xDnsResolvefor hostname resolution, andxTlsConffor TLS configuration. The WebSocket client supports bothxTlsConfand a sharedxTlsCtxforwss://connections. See the TLS Deployment Guide for end-to-end examples. - WebSocket — The WebSocket client uses
xUrlto parsews://andwss://URLs, and optionally accepts a sharedxTlsCtxto avoid per-connection TLS context creation.
url.h — Lightweight URL Parser
Introduction
url.h provides xUrl, a lightweight URL parser that decomposes a URL string into its RFC 3986 components: scheme, userinfo, host, port, path, query, and fragment. The parser makes a single internal copy of the input; all component fields are pointer+length pairs referencing this copy, so the caller may discard the original string immediately after parsing.
Design Philosophy
-
Single Copy, Zero Per-Field Allocation —
xUrlParse()callsstrdup()once. All output fields point into this copy, avoiding per-component heap allocations. -
Pointer+Length Pairs — Fields use
const char *+size_tpairs rather than NUL-terminated strings. This avoids mutating the internal copy and supports efficient substring access. -
Scheme-Aware Default Ports —
xUrlPort()returns well-known default ports (80 for http/ws, 443 for https/wss) when no explicit port is present, simplifying connection logic. -
IPv6 Literal Support — The parser correctly handles bracketed IPv6 addresses (
[::1]:8080), extracting the bare address without brackets.
Architecture
flowchart LR
INPUT["Raw URL string"]
PARSE["xUrlParse()"]
COPY["strdup() internal copy"]
FIELDS["Pointer+Length fields"]
PORT["xUrlPort()"]
FREE["xUrlFree()"]
INPUT --> PARSE
PARSE --> COPY
COPY --> FIELDS
FIELDS --> PORT
FIELDS --> FREE
style PARSE fill:#4a90d9,color:#fff
style FREE fill:#e74c3c,color:#fff
Implementation Details
URL Format
scheme://[userinfo@]host[:port][/path][?query][#fragment]
Parsing Steps
flowchart TD
START["Input: raw URL string"]
SCHEME["Find '://' → extract scheme"]
AUTH["Parse authority section"]
USERINFO{"Contains '@'?"}
UI_YES["Extract userinfo"]
HOST{"Starts with '['?"}
IPV6["Parse IPv6 bracket literal"]
IPV4["Scan backwards for ':'"]
PORT["Extract port (if present)"]
PATH{"Starts with '/'?"}
PATH_YES["Extract path"]
QUERY{"Starts with '?'?"}
QUERY_YES["Extract query"]
FRAG{"Starts with '#'?"}
FRAG_YES["Extract fragment"]
DONE["Return xErrno_Ok"]
START --> SCHEME --> AUTH
AUTH --> USERINFO
USERINFO -->|Yes| UI_YES --> HOST
USERINFO -->|No| HOST
HOST -->|Yes| IPV6 --> PORT
HOST -->|No| IPV4 --> PORT
PORT --> PATH
PATH -->|Yes| PATH_YES --> QUERY
PATH -->|No| QUERY
QUERY -->|Yes| QUERY_YES --> FRAG
QUERY -->|No| FRAG
FRAG -->|Yes| FRAG_YES --> DONE
FRAG -->|No| DONE
style DONE fill:#50b86c,color:#fff
Memory Layout
xUrl struct (stack or heap):
┌──────────┬──────────────────────────────────┐
│ raw_ │→ strdup("https://host:443/path") │
│ scheme │→ ───────┘ │
│ host │→ ──────────────┘ │
│ port │→ ───────────────────┘ │
│ path │→ ────────────────────────┘ │
│ ... │ │
└──────────┴──────────────────────────────────┘
All pointers reference the single raw_ copy.
Operations and Complexity
| Operation | Complexity | Notes |
|---|---|---|
xUrlParse | O(n) | Single pass over the URL string |
xUrlPort | O(1) | Converts port string or returns default |
xUrlFree | O(1) | Frees the internal copy, zeroes struct |
API Reference
Lifecycle
| Function | Signature | Description |
|---|---|---|
xUrlParse | xErrno xUrlParse(const char *raw, xUrl *url) | Parse a URL into components |
xUrlFree | void xUrlFree(xUrl *url) | Free internal copy, zero all fields |
Query
| Function | Signature | Description |
|---|---|---|
xUrlPort | uint16_t xUrlPort(const xUrl *url) | Numeric port (explicit or default by scheme) |
xUrl Fields
| Field | Type | Description |
|---|---|---|
scheme / scheme_len | const char * / size_t | e.g. "https" |
userinfo / userinfo_len | const char * / size_t | e.g. "user:pass" (optional) |
host / host_len | const char * / size_t | e.g. "example.com" or "::1" |
port / port_len | const char * / size_t | e.g. "8443" (optional) |
path / path_len | const char * / size_t | e.g. "/ws/chat" (optional) |
query / query_len | const char * / size_t | e.g. "key=val" (optional) |
fragment / fragment_len | const char * / size_t | e.g. "section1" (optional) |
Note: Optional fields have
ptr=NULL, len=0when absent. Theraw_field is internal — do not access it.
Usage Examples
Basic URL Parsing
#include <stdio.h>
#include <x/net/url.h>
int main(void) {
xUrl url;
xErrno err = xUrlParse("https://user:[email protected]:8443/ws/chat?token=abc#top", &url);
if (err != xErrno_Ok) {
fprintf(stderr, "parse failed\n");
return 1;
}
printf("scheme: %.*s\n", (int)url.scheme_len, url.scheme);
printf("userinfo: %.*s\n", (int)url.userinfo_len, url.userinfo);
printf("host: %.*s\n", (int)url.host_len, url.host);
printf("port: %.*s (numeric: %u)\n", (int)url.port_len, url.port, xUrlPort(&url));
printf("path: %.*s\n", (int)url.path_len, url.path);
printf("query: %.*s\n", (int)url.query_len, url.query);
printf("fragment: %.*s\n", (int)url.fragment_len, url.fragment);
xUrlFree(&url);
return 0;
}
Output:
scheme: https
userinfo: user:pass
host: example.com
port: 8443 (numeric: 8443)
path: /ws/chat
query: token=abc
fragment: top
IPv6 Address
xUrl url;
xUrlParse("http://[::1]:8080/test", &url);
printf("host: %.*s\n", (int)url.host_len, url.host);
// Output: host: ::1 (brackets stripped)
printf("port: %u\n", xUrlPort(&url));
// Output: port: 8080
xUrlFree(&url);
Default Port by Scheme
xUrl url;
xUrlParse("wss://echo.example.com/sock", &url);
// No explicit port in URL
printf("port field: %s\n", url.port ? "present" : "absent");
// Output: port field: absent
// xUrlPort() returns 443 for wss://
printf("effective port: %u\n", xUrlPort(&url));
// Output: effective port: 443
xUrlFree(&url);
Ownership Semantics
// xUrl owns its data — the original string can be freed
char *heap = strdup("ws://example.com:9090/ws");
xUrl url;
xUrlParse(heap, &url);
free(heap); // safe: xUrl has its own copy
// url fields are still valid here
printf("host: %.*s\n", (int)url.host_len, url.host);
xUrlFree(&url);
// After free, all fields are zeroed (NULL)
Error Handling
| Input | Result |
|---|---|
NULL raw or url pointer | xErrno_InvalidArg |
Missing :// separator | xErrno_InvalidArg |
Empty host (e.g. http:///path) | xErrno_InvalidArg |
| Unclosed IPv6 bracket | xErrno_InvalidArg |
malloc failure | xErrno_NoMemory |
On error, the xUrl struct is zeroed — no cleanup needed.
Best Practices
- Always check the return value of
xUrlParse(). On error the struct is zeroed, so accessing fields is safe but yields empty values. - Use
xUrlPort()instead of parsing the port string yourself. It handles default ports and validates the numeric range (0–65535). - Call
xUrlFree()when done. Forgetting to free leaks the internal string copy. - Don't cache field pointers past
xUrlFree(). All pointers become invalid after the free call.
dns.h — Asynchronous DNS Resolution
Introduction
dns.h provides asynchronous DNS resolution by offloading getaddrinfo() to the event loop's thread pool. The completion callback is always invoked on the event loop thread, maintaining moo's single-threaded callback model. Queries can be cancelled before the callback fires.
Design Philosophy
-
Thread-Pool Offload —
getaddrinfo()is a blocking POSIX call. Rather than introducing a dedicated DNS thread, xnet reuses the event loop's existing thread pool viaxEventLoopSubmit(). -
Event-Loop-Thread Callbacks — The done callback runs on the event loop thread, so user code never needs synchronization. This is consistent with every other callback in moo.
-
Linked-List Result — Resolved addresses are returned as a linked list of
xDnsAddrnodes, preserving the fullgetaddrinfo()result (family, socktype, protocol) for each address. -
Cancellation Support —
xDnsCancel()sets an atomic flag. If the worker has already finished, the done callback silently discards the result instead of invoking the user callback. -
IP Literal Fast Path — If the hostname is an IPv4 or IPv6 literal,
AI_NUMERICHOSTis set automatically, skipping the actual DNS lookup.
Architecture
sequenceDiagram
participant App as Application
participant EL as Event Loop Thread
participant TP as Thread Pool Worker
App->>EL: xDnsResolve(loop, "example.com", ...)
EL->>TP: xEventLoopSubmit(dns_work_fn)
Note over TP: getaddrinfo() (blocking)
TP-->>EL: dns_done_fn(result)
alt Not cancelled
EL->>App: callback(result, arg)
else Cancelled
EL->>EL: xDnsResultFree(result)
end
Implementation Details
Internal Request Lifecycle
stateDiagram-v2
[*] --> Created: xDnsResolve()
Created --> Queued: xEventLoopSubmit()
Queued --> Working: Thread pool picks up
Working --> Done: getaddrinfo() returns
Done --> Delivered: callback invoked
Done --> Discarded: cancelled flag set
Queued --> Cancelled: xDnsCancel()
Working --> Cancelled: xDnsCancel()
Cancelled --> Discarded: done_fn checks flag
Delivered --> [*]: request freed
Discarded --> [*]: request freed
Error Mapping
getaddrinfo() returns EAI_* codes. These are mapped to moo error codes:
| EAI Code | xErrno | Meaning |
|---|---|---|
0 (success) | xErrno_Ok | Resolution succeeded |
EAI_NONAME | xErrno_DnsNotFound | Host not found |
EAI_AGAIN | xErrno_DnsTempFail | Temporary failure |
EAI_MEMORY | xErrno_NoMemory | Out of memory |
| Other | xErrno_DnsError | Generic DNS error |
IP Literal Detection
Before calling getaddrinfo(), the worker checks if the hostname is an IP literal using inet_pton(). If it is, AI_NUMERICHOST is added to the hints, which tells getaddrinfo() to skip DNS lookup entirely.
// Pseudocode
if (inet_pton(AF_INET, hostname, buf) == 1 ||
inet_pton(AF_INET6, hostname, buf) == 1) {
hints.ai_flags |= AI_NUMERICHOST;
}
API Reference
Core Functions
| Function | Signature | Description |
|---|---|---|
xDnsResolve | xDnsQuery xDnsResolve(xEventLoop loop, const char *hostname, const char *service, const struct addrinfo *hints, xDnsCallback callback, void *arg) | Start async DNS resolution |
xDnsCancel | void xDnsCancel(xEventLoop loop, xDnsQuery query) | Cancel a pending query |
xDnsResultFree | void xDnsResultFree(xDnsResult *result) | Free a resolution result |
Types
| Type | Description |
|---|---|
xDnsQuery | Opaque handle to a pending query |
xDnsResult | Resolution result: error + addrs linked list |
xDnsAddr | Single resolved address node |
xDnsCallback | void (*)(xDnsResult *result, void *arg) |
xDnsResult Fields
| Field | Type | Description |
|---|---|---|
error | xErrno | xErrno_Ok on success |
addrs | xDnsAddr * | Linked list of addresses, or NULL |
xDnsAddr Fields
| Field | Type | Description |
|---|---|---|
addr | struct sockaddr_storage | Resolved socket address |
addrlen | socklen_t | Length of the address |
family | int | AF_INET or AF_INET6 |
socktype | int | SOCK_STREAM or SOCK_DGRAM |
protocol | int | IPPROTO_TCP or IPPROTO_UDP |
next | xDnsAddr * | Next address, or NULL |
Parameter Details for xDnsResolve
| Parameter | Required | Description |
|---|---|---|
loop | Yes | Event loop (must not be NULL) |
hostname | Yes | Hostname or IP literal (non-empty) |
service | No | Port string (e.g. "443") or NULL |
hints | No | addrinfo hints; NULL defaults to AF_UNSPEC + SOCK_STREAM |
callback | Yes | Completion callback (must not be NULL) |
arg | No | User argument forwarded to callback |
Returns a xDnsQuery handle, or NULL on invalid arguments.
Usage Examples
Basic Resolution
#include <stdio.h>
#include <arpa/inet.h>
#include <x/base/event.h>
#include <x/net/dns.h>
static void on_resolved(xDnsResult *result, void *arg) {
xEventLoop loop = (xEventLoop)arg;
if (result->error != xErrno_Ok) {
fprintf(stderr, "DNS failed: %d\n", result->error);
xDnsResultFree(result);
xEventLoopStop(loop);
return;
}
for (xDnsAddr *a = result->addrs; a; a = a->next) {
char buf[INET6_ADDRSTRLEN];
if (a->family == AF_INET) {
struct sockaddr_in *sin = (struct sockaddr_in *)&a->addr;
inet_ntop(AF_INET, &sin->sin_addr, buf, sizeof(buf));
} else {
struct sockaddr_in6 *sin6 = (struct sockaddr_in6 *)&a->addr;
inet_ntop(AF_INET6, &sin6->sin6_addr, buf, sizeof(buf));
}
printf(" %s (family=%d)\n", buf, a->family);
}
xDnsResultFree(result);
xEventLoopStop(loop);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xDnsResolve(loop, "example.com", "443", NULL, on_resolved, loop);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
IPv4-Only Resolution
struct addrinfo hints = {0};
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
xDnsResolve(loop, "example.com", "80", &hints, on_resolved, loop);```
### Cancelling a Query
```c
xDnsQuery q = xDnsResolve(loop, "slow.example.com", NULL, NULL, on_resolved, NULL);
// Cancel immediately — callback will NOT fire
xDnsCancel(loop, q);
IP Literal (No DNS Lookup)
// Resolves instantly via AI_NUMERICHOST
xDnsResolve(loop, "127.0.0.1", "8080", NULL, on_resolved, loop);
xDnsResolve(loop, "::1", "8080", NULL, on_resolved, loop);
Thread Safety
| Operation | Thread Safety |
|---|---|
xDnsResolve() | Call from event loop thread only |
xDnsCancel() | Call from event loop thread only |
xDnsResultFree() | Call from any thread (result is owned) |
xDnsCallback | Always invoked on event loop thread |
Error Handling
| Scenario | Behavior |
|---|---|
NULL loop, hostname, or callback | Returns NULL (no query created) |
| Empty hostname | Returns NULL |
malloc failure | Returns NULL |
getaddrinfo() failure | Callback receives result->error != xErrno_Ok |
| Cancelled query | Callback is not invoked; result is freed internally |
Best Practices
- Always call
xDnsResultFree()in your callback. The callee owns the result. - Check
result->errorbefore iteratingaddrs. On failure,addrsisNULL. - Use
xDnsCancel()for cleanup. If you destroy the object that owns the callback context, cancel the query first to prevent a use-after-free. - Pass
NULLhints for typical use. The defaults (AF_UNSPEC+SOCK_STREAM) cover most HTTP/WebSocket connection scenarios. xDnsCancel(loop, NULL)is safe — it's a no-op, so you don't need to guard against NULL handles.
tcp.h — Async TCP Connection, Connector & Listener
Introduction
tcp.h provides three async TCP building blocks on top of moo's event loop:
- xTcpConn — a thin resource wrapper that pairs an
xSocketwith anxTransport, plus convenienceRecv/Send/SendIovhelpers. - xTcpConnect — an async connector that performs DNS → socket → non-blocking connect → optional TLS handshake, delivering a ready-to-use
xTcpConnvia callback. - xTcpListener — an async listener that accepts connections (with optional TLS) and delivers each as an
xTcpConn.
All callbacks run on the event loop thread, consistent with the rest of moo.
Design Philosophy
-
Resource Wrapper, Not Callback Framework — Unlike
xWsCallbacks, we intentionally do not provideon_data/on_closecallbacks at the TCP layer. WebSocket callbacks work well because the protocol defines message boundaries, close handshakes, and ping/pong — the library does real work before invoking user code. Raw TCP is a byte stream with no framing; anon_datacallback would still deliver arbitrary fragments, leaving the user to reassemble and parse — no better than callingxTcpConnRecvdirectly. Instead, users register their ownxSocketFunccallback viaxSocketSetCallback()and drive I/O withxTcpConnRecv/xTcpConnSend. -
Transport Transparency —
xTcpConnwraps anxTransportvtable. For plain TCP,read/writevmap toread(2)/writev(2). For TLS, they map toSSL_read/SSL_write. TheRecv/Send/SendIovhelpers hide this detail so users never need to reach intoxTransportinternals. -
Full Async Connector Pipeline —
xTcpConnectchains DNS resolution → socket creation → non-blockingconnect()→ optional TLS handshake into a single async operation with a timeout. Each phase is driven by event loop callbacks. -
Ownership Transfer —
xTcpConnTakeSocketandxTcpConnTakeTransportallow higher-level protocols (e.g. WebSocket upgrade) to extract the underlying resources without closing them.
Architecture
Connector State Machine
stateDiagram-v2
[*] --> DNS: xTcpConnect()
DNS --> TcpConnect: resolved
DNS --> Failed: DNS error
TcpConnect --> TlsHandshake: connected + TLS configured
TcpConnect --> Succeed: connected (plain TCP)
TcpConnect --> Failed: connect error
TlsHandshake --> Succeed: handshake done
TlsHandshake --> Failed: handshake error
Succeed --> [*]: callback(conn, Ok)
Failed --> [*]: callback(NULL, err)
note right of DNS: Async via xDnsResolve
note right of TcpConnect: Non-blocking connect()
note right of TlsHandshake: Async SSL_do_handshake
Listener Accept Flow
sequenceDiagram
participant EL as Event Loop
participant L as xTcpListener
participant PC as PendingConn (TLS only)
participant App as User Callback
EL->>L: xEvent_Read (new connection)
L->>L: accept()
alt Plain TCP
L->>App: callback(listener, conn, addr)
else TLS
L->>PC: create PendingConn
loop Handshake rounds
EL->>PC: xEvent_Read / xEvent_Write
PC->>PC: SSL_do_handshake()
end
PC->>App: callback(listener, conn, addr)
end
xTcpConn Resource Ownership
graph LR
CONN["xTcpConn"]
SOCK["xSocket<br/>(event loop registration)"]
TP["xTransport<br/>(plain / TLS vtable)"]
FD["fd"]
CONN --> SOCK
CONN --> TP
SOCK --> FD
style CONN fill:#4a90d9,color:#fff
style SOCK fill:#50b86c,color:#fff
style TP fill:#f5a623,color:#fff
xTcpConnClose() destroys in order: transport → socket → conn shell. Use xTcpConnTakeSocket() / xTcpConnTakeTransport() to extract resources before closing.
API Reference
xTcpConn — Connection
| Function | Signature | Description |
|---|---|---|
xTcpConnRecv | ssize_t xTcpConnRecv(xTcpConn conn, void *buf, size_t len) | Read up to len bytes; returns bytes read, 0 on EOF, -1 on error |
xTcpConnSend | ssize_t xTcpConnSend(xTcpConn conn, const char *buf, size_t len) | Write len bytes; returns bytes written, -1 on error |
xTcpConnSendIov | ssize_t xTcpConnSendIov(xTcpConn conn, const struct iovec *iov, int iovcnt) | Scatter-gather write; returns total bytes written, -1 on error |
xTcpConnTransport | xTransport *xTcpConnTransport(xTcpConn conn) | Get the internal transport vtable |
xTcpConnSocket | xSocket xTcpConnSocket(xTcpConn conn) | Get the underlying socket handle |
xTcpConnTakeSocket | xSocket xTcpConnTakeSocket(xTcpConn conn) | Extract socket ownership (conn no longer owns it) |
xTcpConnTakeTransport | xTransport xTcpConnTakeTransport(xTcpConn conn) | Extract transport ownership (conn no longer owns it) |
xTcpConnReader | xReader xTcpConnReader(xTcpConn conn) | Get an xReader adapter bound to the connection's transport (see io.h) |
xTcpConnWriter | xWriter xTcpConnWriter(xTcpConn conn) | Get an xWriter adapter bound to the connection's transport (see io.h) |
xTcpConnClose | void xTcpConnClose(xEventLoop loop, xTcpConn conn) | Close connection and free all resources |
xTcpConnect — Async Connector
| Function | Signature | Description |
|---|---|---|
xTcpConnect | xErrno xTcpConnect(xEventLoop loop, const char *host, uint16_t port, const xTcpConnectConf *conf, xTcpConnectFunc callback, void *arg) | Initiate async TCP connection |
xTcpConnectConf Fields
| Field | Type | Default | Description |
|---|---|---|---|
tls_ctx | xTlsCtx | NULL | Pre-created shared TLS context (preferred); NULL for plain TCP or auto-create from tls |
tls | const xTlsConf * | NULL | TLS config for auto-created ctx; ignored when tls_ctx is set; NULL for plain TCP |
timeout_ms | int | 10000 | Connect timeout in milliseconds |
nodelay | int | 0 | Set TCP_NODELAY if non-zero |
keepalive | int | 0 | Set SO_KEEPALIVE if non-zero |
TLS context resolution order: tls_ctx (shared, not owned) → auto-create from tls → defaults (system CA, verify enabled). When tls_ctx is provided, the connector does not create or destroy the context — the caller retains ownership.
xTcpConnectFunc
typedef void (*xTcpConnectFunc)(xTcpConn conn, xErrno err, void *arg);
On success: conn is valid, err is xErrno_Ok. On failure: conn is NULL, err indicates the error.
xTcpListener — Async Listener
| Function | Signature | Description |
|---|---|---|
xTcpListenerCreate | xTcpListener xTcpListenerCreate(xEventLoop loop, const char *host, uint16_t port, const xTcpListenerConf *conf, xTcpListenerFunc callback, void *arg) | Create and start a TCP listener |
xTcpListenerDestroy | void xTcpListenerDestroy(xTcpListener listener) | Stop listening and free resources |
xTcpListenerConf Fields
| Field | Type | Default | Description |
|---|---|---|---|
tls_ctx | xTlsCtx | NULL | TLS context from xTlsCtxCreate(); NULL for plain TCP |
backlog | int | 128 | listen() backlog |
reuseport | int | 0 | Set SO_REUSEPORT if non-zero |
xTcpListenerFunc
typedef void (*xTcpListenerFunc)(xTcpListener listener, xTcpConn conn,
const struct sockaddr *addr, socklen_t addrlen,
void *arg);
Invoked for each accepted connection. The callee takes ownership of conn.
Usage Examples
Echo Server
#include <string.h>
#include <x/base/event.h>
#include <x/base/socket.h>
#include <x/net/tcp.h>
static void on_conn_event(xSocket sock, xEventMask mask, void *arg) {
xTcpConn conn = (xTcpConn)arg;
(void)sock;
if (mask & xEvent_Read) {
char buf[4096];
ssize_t n = xTcpConnRecv(conn, buf, sizeof(buf));
if (n > 0) {
xTcpConnSend(conn, buf, (size_t)n);
} else {
/* EOF or error: close */
xTcpConnClose(xSocketLoop(sock), conn);
}
}
}
static void on_accept(xTcpListener listener, xTcpConn conn,
const struct sockaddr *addr, socklen_t addrlen,
void *arg) {
(void)listener; (void)addr; (void)addrlen; (void)arg;
/* Register our own event callback on the connection's socket */
xSocket sock = xTcpConnSocket(conn);
xSocketSetCallback(sock, on_conn_event, conn);
/* Socket is already registered for xEvent_Read by default */
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xTcpListener listener =
xTcpListenerCreate(loop, "0.0.0.0", 8080, NULL, on_accept, NULL);
if (!listener) return 1;
xEventLoopRun(loop);
xTcpListenerDestroy(listener);
xEventLoopDestroy(loop);
return 0;
}
Async Client
#include <stdio.h>
#include <string.h>
#include <x/base/event.h>
#include <x/base/socket.h>
#include <x/net/tcp.h>
static void on_response(xSocket sock, xEventMask mask, void *arg) {
xTcpConn conn = (xTcpConn)arg;
xEventLoop loop = (xEventLoop)xSocketLoop(sock);
(void)mask;
char buf[4096];
ssize_t n = xTcpConnRecv(conn, buf, sizeof(buf));
if (n > 0) {
printf("Received: %.*s\n", (int)n, buf);
}
xTcpConnClose(loop, conn);
xEventLoopStop(loop);
}
static void on_connected(xTcpConn conn, xErrno err, void *arg) {
xEventLoop loop = (xEventLoop)arg;
if (err != xErrno_Ok) {
fprintf(stderr, "Connect failed: %d\n", err);
xEventLoopStop(loop);
return;
}
/* Send a request */
const char *msg = "Hello, server!";
xTcpConnSend(conn, msg, strlen(msg));
/* Wait for response */
xSocket sock = xTcpConnSocket(conn);
xSocketSetCallback(sock, on_response, conn);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xTcpConnectConf conf = {0};
conf.nodelay = 1;
xTcpConnect(loop, "127.0.0.1", 8080, &conf, on_connected, loop);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
TLS Client (auto-create context)
#include <x/net/tcp.h>
#include <x/net/tls.h>
static void on_tls_connected(xTcpConn conn, xErrno err, void *arg) {
if (err != xErrno_Ok) { /* handle error */ return; }
/* TLS is already established — Recv/Send are transparently encrypted */
const char *msg = "GET / HTTP/1.1\r\nHost: example.com\r\n\r\n";
xTcpConnSend(conn, msg, strlen(msg));
/* ... register read callback ... */
}
void connect_tls(xEventLoop loop) {
xTlsConf tls = {0};
tls.ca = "/etc/ssl/certs/ca-certificates.crt";
xTcpConnectConf conf = {0};
conf.tls = &tls;
xTcpConnect(loop, "example.com", 443, &conf, on_tls_connected, loop);
}
TLS Client (shared context)
When making many connections to the same server, share a xTlsCtx to avoid reloading certificates each time:
#include <x/net/tcp.h>
#include <x/net/tls.h>
static void on_connected(xTcpConn conn, xErrno err, void *arg) {
if (err != xErrno_Ok) { /* handle error */ return; }
/* ... use conn ... */
}
void connect_with_shared_ctx(xEventLoop loop) {
// Create once, reuse for all connections
xTlsConf tls = {0};
tls.ca = "ca.pem";
xTlsCtx ctx = xTlsCtxCreate(&tls);
xTcpConnectConf conf = {0};
conf.tls_ctx = ctx; // shared, not owned by connector
xTcpConnect(loop, "example.com", 443, &conf, on_connected, loop);
xTcpConnect(loop, "example.com", 443, &conf, on_connected, loop);
// ... later, after all connections are closed ...
xTlsCtxDestroy(ctx);
}
TLS Server
#include <x/net/tcp.h>
#include <x/net/transport.h>
void start_tls_server(xEventLoop loop) {
xTlsConf tls_conf = {
.cert = "server.pem",
.key = "server-key.pem",
};
xTlsCtx tls_ctx = xTlsCtxCreate(&tls_conf);
xTcpListenerConf conf = {0};
conf.tls_ctx = tls_ctx;
xTcpListener listener =
xTcpListenerCreate(loop, "0.0.0.0", 8443, &conf, on_accept, NULL);
/* ... run event loop ... */
xTcpListenerDestroy(listener);
xTlsCtxDestroy(tls_ctx);
}
Ownership Transfer (Protocol Upgrade)
/* After receiving an HTTP upgrade response on a TCP connection,
* extract the socket and transport for the new protocol layer. */
xSocket sock = xTcpConnTakeSocket(conn);
xTransport tp = xTcpConnTakeTransport(conn);
/* Close the empty conn shell (no-op on resources) */
xTcpConnClose(loop, conn);
/* sock and tp are now owned by the new protocol handler */
Thread Safety
| Operation | Thread Safety |
|---|---|
xTcpConnect() | Call from event loop thread only |
xTcpListenerCreate() | Call from event loop thread only |
xTcpListenerDestroy() | Call from event loop thread only |
xTcpConnRecv/Send/SendIov() | Call from event loop thread only |
xTcpConnClose() | Call from event loop thread only |
xTcpConnectFunc callback | Always invoked on event loop thread |
xTcpListenerFunc callback | Always invoked on event loop thread |
Error Handling
| Scenario | Behavior |
|---|---|
NULL loop, host, or callback in xTcpConnect | Returns xErrno_InvalidArg |
| DNS resolution failure | Callback receives xErrno_DnsError or xErrno_DnsNotFound |
connect() failure | Callback receives xErrno_SysError |
| TLS handshake failure | Callback receives xErrno_SysError |
| Connect timeout | Callback receives xErrno_Timeout |
xTcpListenerCreate bind/listen failure | Returns NULL |
xTcpConnRecv/Send on NULL conn | Returns -1 |
xTcpConnClose(loop, NULL) | No-op (safe) |
xTcpListenerDestroy(NULL) | No-op (safe) |
Best Practices
- Always close connections with
xTcpConnClose()— it destroys the transport (TLS cleanup), removes the socket from the event loop, closes the fd, and frees the conn. - Register your own
xSocketFuncon the connection's socket viaxSocketSetCallback()to receive read/write events, then usexTcpConnRecv/xTcpConnSendinside the callback. - Use
xTcpConnSendIovfor multi-buffer writes (e.g. header + body) to avoid copying into a single buffer. - Set
nodelay = 1inxTcpConnectConffor latency-sensitive protocols (HTTP, WebSocket). - Use
xTcpConnTakeSocket/xTcpConnTakeTransportwhen upgrading protocols (e.g. HTTP → WebSocket) to avoid double-free. - Cancel or close before freeing context — if you destroy the object that owns the connect callback context, ensure the connection attempt has completed or timed out first.
tls.h — TLS Configuration Types
Introduction
tls.h defines xTlsConf, the unified TLS configuration structure shared across moo modules, and xTlsCtx, the opaque handle to a server-level TLS context. It controls certificate loading, peer verification, and optional ALPN negotiation for both client-side and server-side TLS. These are the central TLS abstractions — the actual TLS handshake is handled by the TLS backend (OpenSSL or mbedTLS) in the transport layer.
Design Philosophy
-
Backend-Agnostic — The config struct contains only file paths and flags. It works identically whether the TLS backend is OpenSSL or mbedTLS.
-
Zero-Initialize for Defaults — A zero-initialized
xTlsConfuses the system CA bundle with full peer and host verification enabled. This is the secure default for both client and server. -
Unified Client/Server — A single
xTlsConfstruct serves both roles. Client-only fields (key_password) and server-only fields (alpn) are simply left asNULL/ zero when unused. -
Separation of Concerns — TLS configuration is defined in xnet (the networking primitives layer) and consumed by xhttp (the HTTP layer). This avoids circular dependencies and allows future modules to reuse the same types.
API Reference
xTlsConf
Unified TLS configuration for both client and server.
| Field | Type | Default | Description |
|---|---|---|---|
cert | const char * | NULL (none) | Path to PEM certificate file |
key | const char * | NULL (none) | Path to PEM private key file |
ca | const char * | NULL (system CA) | Path to CA certificate file |
key_password | const char * | NULL (none) | Private key password (client-side) |
alpn | const char ** | NULL (none) | NULL-terminated ALPN protocol list (server-side) |
skip_verify | int | 0 (verify) | Non-zero to skip peer & host verification |
Backward-compatible aliases: xTlsClientConf and xTlsServerConf are typedef'd to xTlsConf.
xTlsCtx
Opaque handle to a shared TLS context. Created by xTlsCtxCreate(), used by both server-side listeners (xTcpListenerConf.tls_ctx) and client-side connectors (xTcpConnectConf.tls_ctx, xWsConnectConf.tls_ctx). Shared across all connections that use the same context. Destroyed by xTlsCtxDestroy(). Supports certificate hot-reload via xTlsCtxReload().
xTlsCtxCreate
xTlsCtx xTlsCtxCreate(const xTlsConf *conf);
Create a shared TLS context. Loads the certificate (if provided), private key (if provided), optional CA, and optional ALPN list. The returned context can be shared across all connections that use the same TLS configuration.
conf— TLS configuration (must not be NULL). For server-side use,certandkeyare required. For client-side use, onlyca(or defaults) is needed.- Returns a TLS context handle, or
NULLon failure.
xTlsCtxDestroy
void xTlsCtxDestroy(xTlsCtx ctx);
Destroy a shared TLS context and release all resources. Safe to call with NULL (no-op). Must only be called after all connections using this context have been closed.
xTlsCtxReload
int xTlsCtxReload(xTlsCtx ctx, const xTlsConf *conf);
Hot-reload certificates for an existing TLS context. Atomically replaces the certificate, private key, and optional CA. Existing connections are not affected; only new connections will use the updated certificates.
ctx— TLS context to reload (must not be NULL).conf— New TLS configuration (must not be NULL,certandkeymust not be NULL).- Returns
0on success,-1on failure (context unchanged).
Example: Certificate hot-reload
// Initial setup
xTlsConf tls = {
.cert = "server.pem",
.key = "server-key.pem",
.alpn = (const char *[]){"h2", "http/1.1", NULL},
};
xTlsCtx ctx = xTlsCtxCreate(&tls);
// ... later, when certificates are renewed ...
xTlsConf new_tls = {
.cert = "server-new.pem",
.key = "server-key-new.pem",
.alpn = (const char *[]){"h2", "http/1.1", NULL},
};
if (xTlsCtxReload(ctx, &new_tls) == 0) {
// New connections will use the updated certificates
}
One-Way TLS (Client Verifies Server)
#include <x/net/tls.h>
#include <x/http/client.h>
// Use system CA bundle (zero-init)
xTlsConf tls = {0};
xHttpClientConf conf = {.tls = &tls};
xHttpClient client = xHttpClientCreate(loop, &conf);
// Or specify a CA file
xTlsConf tls_ca = {0};
tls_ca.ca = "ca.pem";
xHttpClientConf conf_ca = {.tls = &tls_ca};
xHttpClient client2 = xHttpClientCreate(loop, &conf_ca);
Skip Verification (Development Only)
xTlsConf tls = {0};
tls.skip_verify = 1; // DANGER: disables all checks
xHttpClientConf conf = {.tls = &tls};
xHttpClient client = xHttpClientCreate(loop, &conf);
Mutual TLS (mTLS)
// Server: require client certificate (default: verify enabled)
xTlsConf server_tls = {
.cert = "server.pem",
.key = "server-key.pem",
.ca = "ca.pem",
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &server_tls);
// Client: present certificate
xTlsConf client_tls = {0};
client_tls.ca = "ca.pem";
client_tls.cert = "client.pem";
client_tls.key = "client-key.pem";
xHttpClientConf client_conf = {
.tls = &client_tls,
};
xHttpClient client = xHttpClientCreate(loop, &client_conf);
Password-Protected Private Key
xTlsConf tls = {0};
tls.ca = "ca.pem";
tls.cert = "client.pem";
tls.key = "client-key-enc.pem";
tls.key_password = "my-secret";
xHttpClientConf conf = {.tls = &tls};
xHttpClient client = xHttpClientCreate(loop, &conf);
Relationship with Other Modules
- xnet —
xTlsCtxCreate()/xTlsCtxDestroy()/xTlsCtxReload()are declared intls.hand implemented in the TLS backend files (transport_openssl.c,transport_mbedtls.c). The TCP listener usesxTlsCtxviaxTcpListenerConf.tls_ctx, and the TCP connector uses it viaxTcpConnectConf.tls_ctx. - xhttp — The HTTP server calls
xTlsCtxCreate()internally whenxHttpServerListenTls()is invoked, automatically setting ALPN to{"h2", "http/1.1"}. The HTTP client uses libcurl for TLS management and consumesxTlsConfdirectly. The WebSocket client supports bothxTlsConf(auto-creates a context) and a pre-createdxTlsCtx(shared across connections) viaxWsConnectConf.tls_ctx. See the TLS Deployment Guide for end-to-end examples.
Security Notes
- Never use
skip_verify = 1in production. It disables all certificate validation. - Keep private keys secure. Use restrictive file permissions (
chmod 600). - For mTLS, set
cato the signing CA on the server side. Zero-initializedskip_verifymeans verification is enabled by default. - The config struct does not copy strings. The caller must ensure that file path strings remain valid until
xHttpClientCreate()orxHttpServerListenTls()returns (the library deep-copies them internally).
xhttp — Asynchronous HTTP
Introduction
xhttp is moo's HTTP module, providing both a fully asynchronous HTTP client and server, all powered by xbase's event loop.
- The client uses libcurl's multi-socket API for non-blocking HTTP requests and SSE streaming — ideal for integrating with REST APIs and LLM streaming endpoints. Supports TLS configuration including custom CA certificates, mutual TLS (mTLS), and certificate verification control via
xTlsConf. - The server uses an
xHttpProtovtable interface for protocol-abstracted parsing, supporting both HTTP/1.1 (llhttp) and HTTP/2 (nghttp2, h2c Prior Knowledge) on the same port. TLS listeners are supported viaxHttpServerListenTlswithxTlsConf. Single-threaded, event-driven connection handling — ideal for building lightweight HTTP services and APIs. - WebSocket support includes both server and client. On the server side, call
xWsUpgrade()inside a regular HTTP handler to perform the RFC 6455 upgrade handshake. On the client side, usexWsConnect()to establish an async WebSocket connection to a remote endpoint. The library handles frame codec, ping/pong, fragment reassembly, and close negotiation automatically for both sides.
Design Philosophy
-
Event Loop Integration — Instead of blocking threads, xhttp registers libcurl's sockets with
xEventLoopand uses event-driven I/O. All callbacks are dispatched on the event loop thread, eliminating the need for synchronization. -
Vtable-Based Request Polymorphism — Internally, different request types (oneshot HTTP, SSE streaming) share the same curl multi handle but use different vtables for completion and cleanup. This avoids code duplication while supporting diverse response handling patterns.
-
Zero-Copy Response Delivery — Response headers and body are accumulated in
xBufferinstances and delivered to the callback as pointers. No extra copies are made. -
Automatic Resource Management — Request contexts, curl easy handles, and buffers are automatically cleaned up after the completion callback returns. In-flight requests are cancelled with error callbacks when the client is destroyed.
Architecture
graph TD
subgraph "Application"
APP["User Code"]
end
subgraph "xhttp"
CLIENT["xHttpClient"]
TLS_CLI["TLS Config<br/>(xTlsConf)"]
ONESHOT["Oneshot Request<br/>(GET/POST/Do)"]
SSE["SSE Request<br/>(GetSse/DoSse)"]
PARSER["SSE Parser<br/>(W3C spec)"]
end
subgraph "libcurl"
MULTI["curl_multi"]
EASY1["curl_easy (req 1)"]
EASY2["curl_easy (req 2)"]
end
subgraph "xbase"
LOOP["xEventLoop"]
TIMER["Timer<br/>(curl timeout)"]
FD["FD Events<br/>(socket I/O)"]
end
APP -->|"xHttpClientGet/Post/Do"| ONESHOT
APP -->|"xHttpClientGetSse/DoSse"| SSE
APP -->|"xHttpClientConf.tls"| TLS_CLI
SSE --> PARSER
ONESHOT --> CLIENT
SSE --> CLIENT
TLS_CLI --> CLIENT
CLIENT --> MULTI
MULTI --> EASY1
MULTI --> EASY2
MULTI -->|"CURLMOPT_SOCKETFUNCTION"| FD
MULTI -->|"CURLMOPT_TIMERFUNCTION"| TIMER
FD --> LOOP
TIMER --> LOOP
style CLIENT fill:#4a90d9,color:#fff
style LOOP fill:#50b86c,color:#fff
style MULTI fill:#f5a623,color:#fff
Sub-Module Overview
| File | Description | Doc |
|---|---|---|
server.h | Async HTTP/1.1 & HTTP/2 server (routing, request/response, protocol-abstracted parsing) | server.md |
client.h | Async HTTP client API (GET, POST, Do, SSE, TLS configuration) | client.md |
sse.c | SSE stream parser and request handler | sse.md |
ws.h (server) | WebSocket server API (upgrade, send, close, callbacks) | ws_server.md |
ws.h (client) | WebSocket client API (connect, send, close, callbacks) | ws_client.md |
| (guide) | TLS deployment guide (certificate generation, one-way TLS, mTLS, troubleshooting) | tls.md |
Quick Start
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/client.h>
static void on_response(const xHttpResponse *resp, void *arg) {
(void)arg;
if (resp->curl_code == 0) {
printf("Status: %ld\n", resp->status_code);
printf("Body: %.*s\n", (int)resp->body_len, resp->body);
} else {
printf("Error: %s\n", resp->curl_error);
}
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpClient client = xHttpClientCreate(loop, NULL);
xHttpClientGet(client, "https://httpbin.org/get", on_response, NULL);
xEventLoopRun(loop);
xHttpClientDestroy(client);
xEventLoopDestroy(loop);
return 0;
}
Relationship with Other Modules
- xbase — Uses
xEventLoopfor I/O multiplexing andxEventLoopTimerAfterfor curl timeout management. - xbuf — Uses
xBufferfor response header and body accumulation. - libcurl — External dependency (client). Uses the multi-socket API (
curl_multi_socket_action) for non-blocking HTTP. - llhttp — External dependency (server). Provides incremental HTTP/1.1 request parsing, isolated behind the
xHttpProtovtable inproto_h1.c. - nghttp2 — External dependency (server). Provides HTTP/2 frame processing and HPACK header compression, isolated behind the
xHttpProtovtable inproto_h2.c.
client.h — Asynchronous HTTP Client
Introduction
client.h provides xHttpClient, an asynchronous HTTP client that integrates libcurl's multi-socket API with xbase's event loop. All network I/O is non-blocking and driven by the event loop; completion callbacks are dispatched on the event loop thread. The client supports GET, POST, PUT, DELETE, PATCH, HEAD methods and Server-Sent Events (SSE) streaming.
Design Philosophy
-
libcurl Multi-Socket Integration — Rather than using libcurl's easy (blocking) API or multi-perform (polling) API, xhttp uses the multi-socket API (
CURLMOPT_SOCKETFUNCTION+CURLMOPT_TIMERFUNCTION). This allows libcurl to delegate socket monitoring to xEventLoop, achieving true event-driven I/O without dedicated threads. -
Single-Threaded Callback Model — All callbacks (response, SSE events, done) are invoked on the event loop thread. No locks are needed in callback code.
-
Vtable-Based Polymorphism — Internally, each request carries a vtable (
xHttpReqVtable) withon_doneandon_cleanupfunction pointers. Oneshot requests and SSE requests use different vtables, sharing the same curl multi handle and completion infrastructure. -
Automatic Body Copy — POST/PUT request bodies are copied internally (
malloc+memcpy), so the caller doesn't need to keep the body alive after submitting the request.
Architecture
graph TD
subgraph xHttpClientInternal[xHttpClient Internal]
MULTI[curl multi handle]
TIMER_CB[timer callback - CURLMOPT TIMERFUNCTION]
SOCKET_CB[socket callback - CURLMOPT SOCKETFUNCTION]
CHECK[check multi info]
end
subgraph PerRequest[Per Request]
REQ[xHttpReq]
EASY[curl easy handle]
BODY[xBuffer body]
HDR[xBuffer headers]
VT[vtable - oneshot or SSE]
end
subgraph xbaseEventLoop[xbase Event Loop]
LOOP[xEventLoop]
FD_EVT[FD events]
TIMER_EVT[Timer events]
end
SOCKET_CB --> FD_EVT
TIMER_CB --> TIMER_EVT
FD_EVT --> LOOP
TIMER_EVT --> LOOP
LOOP -->|fd ready| CHECK
LOOP -->|timeout| CHECK
CHECK --> VT
VT -->|on done| APP[User Callback]
REQ --> EASY
REQ --> BODY
REQ --> HDR
REQ --> VT
style MULTI fill:#f5a623,color:#fff
style LOOP fill:#50b86c,color:#fff
Implementation Details
libcurl + xEventLoop Integration
sequenceDiagram
participant App as Application
participant Client as xHttpClient
participant Curl as CurlMulti
participant L as xEventLoop
App->>Client: xHttpClientGet url cb
Client->>Curl: curl multi add handle
Curl->>Client: socket callback fd POLL IN
Client->>L: xEventAdd fd Read
Note over L: Event loop polls
L->>Client: fd ready callback
Client->>Curl: curl multi socket action
Curl->>Client: write callback data
Client->>Client: xBufferAppend body buf data
Note over Curl: Transfer complete
Client->>Client: check multi info
Client->>App: on response resp
Socket Callback Flow
When libcurl needs to monitor a socket, it calls socket_callback:
- CURL_POLL_REMOVE — Unregister the fd from the event loop (
xEventDel). - CURL_POLL_IN/OUT/INOUT — Register or update the fd with the event loop (
xEventAdd/xEventMod).
Each socket gets an xHttpSocketCtx_ that maps the fd to the client and event source.
Timer Callback Flow
When libcurl needs a timeout:
- timeout_ms == -1 — Cancel any existing timer.
- timeout_ms == 0 — Schedule a 1ms timer (deferred to avoid reentrant
curl_multi_socket_action). - timeout_ms > 0 — Schedule a timer via
xEventLoopTimerAfter.
When the timer fires, curl_multi_socket_action(CURL_SOCKET_TIMEOUT) is called.
Request Lifecycle
stateDiagram-v2
[*] --> Created: xHttpClientGet/Post/Do
Created --> Submitted: curl_multi_add_handle
Submitted --> InFlight: Event loop drives I/O
InFlight --> Completed: curl reports CURLMSG_DONE
Completed --> CallbackInvoked: on_response(resp)
CallbackInvoked --> CleanedUp: free buffers + easy handle
CleanedUp --> [*]
InFlight --> Aborted: xHttpClientDestroy
Aborted --> CallbackInvoked: on_response(error)
Response Structure
XDEF_STRUCT(xHttpResponse) {
long status_code; // HTTP status (200, 404, etc.), 0 on failure
const char *headers; // Raw headers (NUL-terminated)
size_t headers_len;
const char *body; // Response body (NUL-terminated)
size_t body_len;
int curl_code; // CURLcode (0 = success)
const char *curl_error; // Human-readable error, or NULL
};
All pointers are valid only during the callback. The library manages their lifetime.
API Reference
Types
| Type | Description |
|---|---|
xHttpClient | Opaque handle to an HTTP client bound to an event loop |
xHttpClientConf | Configuration struct for creating a client (TLS, HTTP version) |
xHttpResponse | Response data delivered to the completion callback |
xHttpResponseFunc | void (*)(const xHttpResponse *resp, void *arg) |
xHttpMethod | Enum: GET, POST, PUT, DELETE, PATCH, HEAD |
xHttpVersion | Enum: Default, H1, H2, H2TLS, H2C |
xHttpRequestConf | Configuration struct for generic requests |
xSseEvent | SSE event data delivered to the event callback |
xSseEventFunc | int (*)(const xSseEvent *ev, void *arg) — return 0 to continue, non-zero to close |
xSseDoneFunc | void (*)(int curl_code, void *arg) |
xTlsConf | TLS configuration for the client (CA path, client cert/key, skip verify) |
Lifecycle
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xHttpClientCreate | xHttpClient xHttpClientCreate(xEventLoop loop, const xHttpClientConf *conf) | Create a client bound to an event loop. Pass NULL for defaults. | Not thread-safe |
xHttpClientDestroy | void xHttpClientDestroy(xHttpClient client) | Destroy client. In-flight requests get error callbacks. | Not thread-safe |
TLS Configuration
TLS is configured at client creation time via
xHttpClientConf. The xTlsConf fields are
deep-copied internally; the caller does not need to
keep them alive after creation.
xTlsConf Fields (Client)
| Field | Type | Description |
|---|---|---|
ca | const char * | Path to a CA certificate file for server verification. When set, the system CA bundle is bypassed. |
cert | const char * | Path to a client certificate file (PEM) for mutual TLS (mTLS). |
key | const char * | Path to the client private key file (PEM) for mTLS. |
key_password | const char * | Passphrase for an encrypted client private key. |
skip_verify | int | If non-zero, skip server certificate verification (useful for self-signed certs in development). |
All string fields are deep-copied internally; the caller does not need to keep them alive after the call.
HTTP Version Configuration
The xHttpClientConf.http_version field controls the default HTTP
protocol version for all requests made through the client. It can be
overridden per-request via xHttpRequestConf.http_version.
| Value | Description |
|---|---|
xHttpVersion_Default | Use client default (initially HTTP/1.1) |
xHttpVersion_H1 | Force HTTP/1.1 |
xHttpVersion_H2 | HTTP/2 with TLS (ALPN), fallback to H1 |
xHttpVersion_H2TLS | HTTP/2 over TLS only, no fallback |
xHttpVersion_H2C | HTTP/2 cleartext (Prior Knowledge) |
Request Configuration
xHttpRequestConf provides full control over individual requests:
| Field | Type | Description |
|---|---|---|
url | const char * | Request URL (must not be NULL) |
method | xHttpMethod | HTTP method (default: GET) |
body | const char * | Request body, or NULL |
body_len | size_t | Length of body in bytes |
headers | const char ** | NULL-terminated array of "Key: Value" |
timeout_ms | long | Per-request timeout in ms (0 = no limit). For regular HTTP: total transfer timeout. For SSE: connection-phase timeout only; stalled streams are detected via low-speed-time instead. |
http_version | xHttpVersion | HTTP version override (0 = use client default) |
Convenience Requests
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xHttpClientGet | xErrno xHttpClientGet(xHttpClient client, const char *url, xHttpResponseFunc on_response, void *arg) | Async GET request. | Not thread-safe |
xHttpClientPost | xErrno xHttpClientPost(xHttpClient client, const char *url, const char *body, size_t body_len, xHttpResponseFunc on_response, void *arg) | Async POST request. Body is copied internally. | Not thread-safe |
Generic Request
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xHttpClientDo | xErrno xHttpClientDo(xHttpClient client, const xHttpRequestConf *config, xHttpResponseFunc on_response, void *arg) | Fully-configured async request. | Not thread-safe |
SSE Requests
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xHttpClientGetSse | xErrno xHttpClientGetSse(xHttpClient client, const char *url, xSseEventFunc on_event, xSseDoneFunc on_done, void *arg) | Subscribe to SSE endpoint (GET). | Not thread-safe |
xHttpClientDoSse | xErrno xHttpClientDoSse(xHttpClient client, const xHttpRequestConf *config, xSseEventFunc on_event, xSseDoneFunc on_done, void *arg) | Fully-configured SSE request (e.g., POST for LLM APIs). | Not thread-safe |
Usage Examples
Simple GET Request
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/client.h>
static void on_response(const xHttpResponse *resp, void *arg) {
(void)arg;
if (resp->curl_code == 0) {
printf("HTTP %ld\n", resp->status_code);
printf("%.*s\n", (int)resp->body_len, resp->body);
} else {
printf("Error: %s\n", resp->curl_error);
}
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpClient client = xHttpClientCreate(loop, NULL);
xHttpClientGet(client, "https://httpbin.org/get", on_response, NULL);
xEventLoopRun(loop);
xHttpClientDestroy(client);
xEventLoopDestroy(loop);
return 0;
}
HTTPS with TLS Configuration
#include <x/base/event.h>
#include <x/http/client.h>
static void on_response(const xHttpResponse *resp,
void *arg) {
(void)arg;
printf("Status: %ld\n", resp->status_code);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
// Skip certificate verification (dev only)
xTlsConf tls = {0};
tls.skip_verify = 1;
xHttpClientConf conf = {.tls = &tls};
xHttpClient client =
xHttpClientCreate(loop, &conf);
xHttpClientGet(
client,
"https://secure.example.com/api",
on_response, NULL);
xEventLoopRun(loop);
xHttpClientDestroy(client);
xEventLoopDestroy(loop);
return 0;
}
POST with Custom Headers
#include <x/base/event.h>
#include <x/http/client.h>
static void on_response(const xHttpResponse *resp, void *arg) {
(void)arg;
printf("Status: %ld, Body: %.*s\n",
resp->status_code, (int)resp->body_len, resp->body);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpClient client = xHttpClientCreate(loop, NULL);
const char *headers[] = {
"Content-Type: application/json",
"Authorization: Bearer token123",
NULL
};
xHttpRequestConf config = {
.url = "https://api.example.com/data",
.method = xHttpMethod_POST,
.body = "{\"key\": \"value\"}",
.body_len = 16,
.headers = headers,
.timeout_ms = 5000,
};
xHttpClientDo(client, &config, on_response, NULL);
xEventLoopRun(loop);
xHttpClientDestroy(client);
xEventLoopDestroy(loop);
return 0;
}
Use Cases
-
REST API Integration — Make async HTTP calls to microservices, cloud APIs, or webhooks from an event-driven C application.
-
Secure Communication — Pass TLS config via
xHttpClientConfat creation time to configure custom CA certificates, client certificates for mTLS, or skip verification for development environments with self-signed certs. -
LLM API Calls — Use
xHttpClientDoSse()with POST method and JSON body to stream responses from OpenAI, Anthropic, or other LLM APIs. See sse.md for a complete example. -
Health Checks / Monitoring — Periodically poll HTTP endpoints using timer-driven GET requests within the event loop.
Best Practices
- Don't block in callbacks. Callbacks run on the event loop thread. Blocking delays all other I/O.
- Copy data you need to keep. Response pointers (
body,headers) are only valid during the callback. - Use
xHttpClientDo()for complex requests. The convenience helpers (Get/Post) are for simple cases;Dogives full control over method, headers, body, and timeout. - Destroy the client before the event loop.
xHttpClientDestroy()cancels in-flight requests and invokes their callbacks with error status. - Check
curl_codefirst. Acurl_codeof 0 means the HTTP transfer succeeded; then checkstatus_codefor the HTTP-level result. - Never use
skip_verifyin production. It disables all certificate validation. Use a proper CA path or system CA bundle instead. - TLS config is set at creation time. Pass
xHttpClientConfwith TLS settings when creating the client; it affects both oneshot and SSE requests. To change TLS config, destroy and recreate the client. - For SSE,
timeout_msonly covers the connection phase. Once the stream is established, stalled streams are detected via libcurl's low-speed-time mechanism instead of a hard timeout. This prevents premature disconnection during slow LLM token generation.
Comparison with Other Libraries
| Feature | xhttp client.h | libcurl easy API | cpp-httplib | Python requests |
|---|---|---|---|---|
| I/O Model | Async (event loop) | Blocking | Blocking | Blocking |
| Event Loop | xEventLoop integration | None (or manual multi) | None | None (asyncio separate) |
| SSE Support | Built-in (GetSse/DoSse) | Manual parsing | No | No (needs sseclient) |
| TLS Config | xHttpClientConf.tls at creation | curl_easy_setopt (manual) | Built-in | verify/cert params |
| Thread Model | Single-threaded callbacks | One thread per request | One thread per request | One thread per request |
| Memory | Automatic (xBuffer) | Manual (WRITEFUNCTION) | Automatic (std::string) | Automatic (Python GC) |
| Language | C99 | C | C++ | Python |
Key Differentiator: xhttp provides true event-loop-integrated async HTTP with built-in SSE support. Unlike libcurl's easy API (which blocks) or multi-perform API (which requires polling), xhttp uses the multi-socket API for zero-overhead integration with xEventLoop. The built-in SSE parser makes it uniquely suited for LLM API integration from C.
server.h — Asynchronous HTTP/1.1 & HTTP/2 Server
Introduction
server.h provides xHttpServer, an asynchronous, non-blocking HTTP server powered by xbase's event loop. The server supports both HTTP/1.1 and HTTP/2 (h2c, cleartext) on the same port, with automatic protocol detection via Prior Knowledge. The protocol parsing layer is abstracted behind an xHttpProto vtable interface — HTTP/1.1 uses llhttp, HTTP/2 uses nghttp2. All connection handling, request parsing, and response sending are driven by the event loop on a single thread — no locks or thread pools required. The server supports routing, keep-alive, configurable limits, automatic error responses, and TLS/HTTPS via xHttpServerListenTls() with pluggable TLS backends (OpenSSL or Mbed TLS).
Design Philosophy
-
Single-Threaded Event-Driven I/O — The server registers listening and client sockets with
xEventLoop. Accept, read, parse, dispatch, and write all happen on the event loop thread, eliminating synchronization overhead. -
Protocol-Abstracted Parsing — Request parsing is delegated to a protocol handler behind the
xHttpProtovtable interface. HTTP/1.1 (proto_h1.c) uses llhttp; HTTP/2 (proto_h2.c) uses nghttp2. Incremental callbacks accumulate URL, headers, and body intoxBufferinstances. This abstraction allows both protocols to share the same connection management, routing, and response serialization layers. -
Automatic Protocol Detection — On each new connection, the server inspects the first bytes of incoming data. If the 24-byte HTTP/2 connection preface (
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n) is detected, the connection is upgraded to HTTP/2; otherwise, HTTP/1.1 is used. This enables h2c (cleartext HTTP/2) via Prior Knowledge — ideal for internal service-to-service communication. -
First-Match Routing — Routes are registered as pattern strings (e.g.
"GET /users/:id"or"/any") and matched in registration order. If the pattern starts with/, it matches any HTTP method; otherwise the first token is the method. Path patterns support both exact segments and:paramsegments. -
Writer-Based Response API — Handlers receive an
xHttpResponseWriterhandle to set status, headers, and body. The response is serialized into anxIOBufferand flushed asynchronously, with backpressure handled automatically. -
Defensive Limits — Configurable limits on header size (default 8 KiB), body size (default 1 MiB), and idle timeout (default 60 s) protect against slow clients and oversized payloads. Violations produce appropriate 4xx error responses.
-
Pluggable TLS — TLS support is provided via
xHttpServerListenTls()withxTlsConf. The TLS backend (OpenSSL or Mbed TLS) is selected at compile time viaX_TLS_BACKEND. ALPN negotiation automatically selects HTTP/1.1 or HTTP/2 over TLS. Mutual TLS (mTLS) is supported whencais set (verification is enabled by default).
Architecture
graph TD
subgraph "Application"
APP["User Code"]
HANDLER["Handler Callback"]
end
subgraph "xhttp Server"
SERVER["xHttpServer"]
TLS["TLS Layer<br/>(OpenSSL / Mbed TLS)"]
ROUTER["Route Table<br/>(linked list)"]
CONN["xHttpConn_<br/>(per connection)"]
DETECT["Protocol Detection<br/>(Prior Knowledge / ALPN)"]
PROTO["xHttpProto (vtable)"]
PARSER_H1["proto_h1 (llhttp)"]
PARSER_H2["proto_h2 (nghttp2)"]
STREAM["xHttpStream_<br/>(per request)"]
WRITER["xHttpResponseWriter"]
end
subgraph "xbase"
LOOP["xEventLoop"]
SOCK["xSocket"]
TIMER["Idle Timeout"]
end
APP -->|"xHttpServerRoute"| ROUTER
APP -->|"xHttpServerListen<br/>xHttpServerListenTls"| SERVER
SERVER -->|"accept()"| CONN
SERVER -.->|"TLS handshake"| TLS
TLS -.-> CONN
CONN --> DETECT
DETECT -->|"H1"| PARSER_H1
DETECT -->|"H2 preface"| PARSER_H2
PARSER_H1 --> PROTO
PARSER_H2 --> PROTO
PROTO -->|"request complete"| STREAM
STREAM --> ROUTER
ROUTER -->|"first match"| HANDLER
HANDLER -->|"xHttpResponseSend"| WRITER
WRITER --> STREAM
STREAM -->|"H1: xIOBuffer / H2: nghttp2 frames"| CONN
CONN --> SOCK
SOCK --> LOOP
TIMER --> LOOP
style SERVER fill:#4a90d9,color:#fff
style LOOP fill:#50b86c,color:#fff
style PROTO fill:#9b59b6,color:#fff
style PARSER_H1 fill:#f5a623,color:#fff
style PARSER_H2 fill:#e74c3c,color:#fff
style DETECT fill:#1abc9c,color:#fff
style TLS fill:#2ecc71,color:#fff
Implementation Details
Connection Lifecycle
stateDiagram-v2
[*] --> Accepted: accept() on listen fd
Accepted --> Reading: xSocket registered (Read)
Reading --> Parsing: Data received
Parsing --> Dispatching: on_message_complete
Dispatching --> HandlerRunning: Route matched
Dispatching --> ErrorSent: No match (404/405)
HandlerRunning --> ResponseQueued: xHttpResponseSend()
ResponseQueued --> Flushing: conn_try_flush()
Flushing --> KeepAlive: All written + keep-alive
Flushing --> Backpressure: EAGAIN (register Write)
Backpressure --> Flushing: Write event fires
KeepAlive --> Reading: Reset parser state
Flushing --> Closed: All written + !keep-alive
ErrorSent --> Closed: Error responses close connection
Reading --> Closed: Idle timeout
Reading --> Closed: Client disconnect
Reading --> Closed: Parse error (400)
Parsing --> ErrorSent: Header too large (431)
Parsing --> ErrorSent: Body too large (413)
Request Parsing Flow
sequenceDiagram
participant Client
participant Conn as xHttpConn_
participant Proto as xHttpProto (vtable)
participant Parser as proto_h1 (llhttp)
participant Bufs as xBuffer (url/headers/body)
participant Router as Route Table
participant Handler as User Handler
Client->>Conn: TCP data
Conn->>Conn: xIOBufferReadFd()
Conn->>Proto: proto.on_data(data)
Proto->>Parser: llhttp_execute(data)
Parser->>Bufs: on_url → xBufferAppend(url)
Parser->>Bufs: on_header_field → xBufferAppend(headers_raw)
Parser->>Bufs: on_header_value → xBufferAppend(headers_raw)
Parser->>Bufs: on_body → xBufferAppend(body)
Parser->>Proto: on_message_complete → return 1
Proto->>Conn: return 1 (request complete)
Conn->>Router: conn_dispatch_request()
Router->>Handler: handler(writer, req, arg)
Handler->>Conn: xHttpResponseSend(body)
Conn->>Client: HTTP response (async flush)
Routing
Routes are stored in a singly-linked list and matched in registration order (first match wins):
- Path match — Segment-by-segment comparison. Static segments require exact match;
:paramsegments match any non-empty string and capture the value. - Method match — Case-insensitive comparison (
strcasecmp). A pattern without a method prefix (e.g."/any") matches any HTTP method. - Fallback — If the path matches but no method matches → 405 Method Not Allowed. If no path matches → 404 Not Found.
- Parameter access — Inside a handler, call
xHttpRequestParam(req, "id", &len)to retrieve the captured value.
Response Serialization
When xHttpResponseSend() is called:
- Status line (
HTTP/1.1 <code> <reason>\r\n) is written to thexIOBuffer. Content-Lengthheader is added automatically.Connection: keep-aliveorConnection: closeis added based on the parser's determination.- User-set headers are appended.
- Header section is terminated with
\r\n. - Body is appended.
conn_try_flush()attempts an immediatewritev(). IfEAGAIN, the socket is registered for write events and flushing continues asynchronously.
Keep-Alive & Pipelining
- HTTP/1.1 connections default to keep-alive. After a response is fully flushed,
proto.reset()is called and the connection waits for the next request. - The parser is paused in
on_message_completeto prevent parsing the next pipelined request before the current response is sent. - Error responses always set
Connection: close.
HTTP/2 Support (h2c Prior Knowledge)
The server supports cleartext HTTP/2 (h2c) via the Prior Knowledge mechanism. HTTP/1.1 and HTTP/2 coexist on the same port — no TLS or Upgrade header required.
Protocol Detection
When a new connection is accepted, protocol detection is deferred until the first bytes arrive:
- If the first 24 bytes match the HTTP/2 connection preface (
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n),xHttpProtoH2Init()is called. - If the prefix doesn't match,
xHttpProtoH1Init()is called. - If fewer than 24 bytes have arrived but the prefix still matches so far, the server waits for more data before deciding.
Stream Multiplexing
Under HTTP/2, a single TCP connection carries multiple concurrent streams, each representing an independent request/response exchange:
xHttpStream_— Per-request state (URL, headers, body, response writer). HTTP/1.1 uses a single implicit stream (stream_id = 0); HTTP/2 creates a new stream for each request.- Deferred dispatch — Completed streams are queued during
nghttp2_session_mem_recv()and dispatched after it returns, avoiding re-entrancy issues. - Response framing — Responses are submitted via
nghttp2_submit_response()with HPACK-compressed headers and DATA frames, then flushed through the connection's write buffer.
H2 Connection Lifecycle
sequenceDiagram
participant Client
participant Conn as xHttpConn_
participant Detect as Protocol Detection
participant H2 as proto_h2 (nghttp2)
participant Stream as xHttpStream_
participant Router as Route Table
participant Handler as User Handler
Client->>Conn: TCP connect
Client->>Conn: H2 connection preface + SETTINGS
Conn->>Detect: First bytes inspection
Detect->>H2: xHttpProtoH2Init()
H2->>Client: SETTINGS frame (server preface)
Client->>Conn: HEADERS frame (stream 1, :method=GET, :path=/hello)
Conn->>H2: h2_on_data()
H2->>Stream: Create stream (id=1)
H2->>Stream: Accumulate headers
H2->>Router: Dispatch (END_STREAM received)
Router->>Handler: handler(writer, req, arg)
Handler->>Stream: xHttpResponseSend(body)
Stream->>H2: nghttp2_submit_response()
H2->>Client: HEADERS + DATA frames
Key Differences: H1 vs H2
| Feature | HTTP/1.1 (proto_h1) | HTTP/2 (proto_h2) |
|---|---|---|
| Parser | llhttp (byte stream → request) | nghttp2 (byte stream → frame → stream) |
| Multiplexing | None (pipelining at best) | Native, multiple concurrent streams |
| Headers | Plain text Key: Value | HPACK compressed pseudo-headers + regular headers |
| Keep-alive | Connection: keep-alive header | Always persistent (multiplexed) |
| Reset | Per-request proto.reset() | No-op (streams are independent) |
| Response framing | Raw HTTP/1.1 status line + headers + body | nghttp2_submit_response() → HEADERS + DATA frames |
| Flow control | None | Built-in per-stream flow control |
Limitations
- h2 over TLS — TLS-based HTTP/2 (h2 with ALPN) is supported via
xHttpServerListenTls(). Cleartext h2c uses Prior Knowledge. - No server push — HTTP/2 server push is not implemented.
- Streaming responses —
xHttpResponseWrite()/xHttpResponseEnd()for HTTP/2 streaming DATA frames is not yet fully implemented.
Idle Timeout
Each connection has an idle timeout (default 60 s). If no data is received within this period, the connection is closed automatically via xEvent_Timeout. The timeout is reset after each response is sent on a keep-alive connection.
API Reference
Types
| Type | Description |
|---|---|
xHttpServer | Opaque handle to an HTTP server bound to an event loop |
xHttpResponseWriter | Opaque handle to a response writer (valid only during handler) |
xHttpRequest | Request data delivered to the handler callback |
xHttpHandlerFunc | void (*)(xHttpResponseWriter writer, const xHttpRequest *req, void *arg) |
xTlsConf | TLS configuration for HTTPS listeners (cert, key, CA, skip_verify) |
xHttpRequest Fields
| Field | Type | Description |
|---|---|---|
method | const char * | HTTP method string (e.g. "GET", "POST") |
url | const char * | Request URL / path (NUL-terminated) |
headers | const char * | Raw request headers (NUL-terminated) |
headers_len | size_t | Length of headers in bytes |
body | const char * | Request body, or NULL if no body |
body_len | size_t | Length of body in bytes |
All pointers are valid only for the duration of the handler callback.
Lifecycle
| Function | Signature | Description |
|---|---|---|
xHttpServerCreate | xHttpServer xHttpServerCreate(xEventLoop loop) | Create a server bound to an event loop. |
xHttpServerListen | xErrno xHttpServerListen(xHttpServer server, const char *host, uint16_t port) | Start listening on the given address and port. |
xHttpServerListenTls | xErrno xHttpServerListenTls(xHttpServer server, const char *host, uint16_t port, const xTlsConf *config) | Start listening for HTTPS connections with TLS. ALPN selects H1/H2. Can coexist with Listen on a different port. Returns xErrno_NotSupported if no TLS backend was compiled. |
xHttpServerDestroy | void xHttpServerDestroy(xHttpServer server) | Destroy server, close all connections, free all routes. |
Route Registration
| Function | Signature | Description |
|---|---|---|
xHttpServerRoute | xErrno xHttpServerRoute(xHttpServer server, const char *pattern, xHttpHandlerFunc handler, void *arg) | Register a route. pattern combines method and path: "GET /users/:id" matches only GET; "/users/:id" matches all methods. Path supports :param segments. First match wins. |
Request Parameters
| Function | Signature | Description |
|---|---|---|
xHttpRequestParam | const char *xHttpRequestParam(const xHttpRequest *req, const char *name, size_t *len) | Look up a path parameter by name. Returns a pointer to the value (NOT NUL-terminated) and sets *len, or returns NULL if not found. |
Response
| Function | Signature | Description |
|---|---|---|
xHttpResponseSetStatus | void xHttpResponseSetStatus(xHttpResponseWriter writer, int code) | Set HTTP status code (default 200). |
xHttpResponseSetHeader | xErrno xHttpResponseSetHeader(xHttpResponseWriter writer, const char *key, const char *value) | Add a response header. Call before Send or the first Write. |
xHttpResponseSend | xErrno xHttpResponseSend(xHttpResponseWriter writer, const char *body, size_t body_len) | Send a complete response. May only be called once. Mutually exclusive with Write. |
xHttpResponseWrite | xErrno xHttpResponseWrite(xHttpResponseWriter writer, const char *data, size_t len) | Write data to a streaming response. First call flushes headers (no Content-Length). Mutually exclusive with Send. |
xHttpResponseEnd | void xHttpResponseEnd(xHttpResponseWriter writer) | End a streaming response. Optional — auto-called when the handler returns. |
Configuration
| Function | Signature | Description | Default |
|---|---|---|---|
xHttpServerSetIdleTimeout | xErrno xHttpServerSetIdleTimeout(xHttpServer server, int timeout_ms) | Set idle timeout for connections. | 60000 ms |
xHttpServerSetMaxHeaderSize | xErrno xHttpServerSetMaxHeaderSize(xHttpServer server, size_t max_size) | Set max header size. Exceeding → 431. | 8192 bytes |
xHttpServerSetMaxBodySize | xErrno xHttpServerSetMaxBodySize(xHttpServer server, size_t max_size) | Set max body size. Exceeding → 413. | 1048576 bytes |
All configuration functions must be called before xHttpServerListen() / xHttpServerListenTls().
TLS Configuration
xTlsConf Fields (Server)
| Field | Type | Description |
|---|---|---|
cert | const char * | Path to PEM certificate file (required). |
key | const char * | Path to PEM private key file (required). |
ca | const char * | Path to CA certificate file for client verification (optional). |
skip_verify | int | If non-zero, skip peer verification. Default 0 (verify enabled). |
When ca is set and skip_verify is 0 (default), the server performs mutual TLS (mTLS) — clients must present a valid certificate signed by the specified CA.
Usage Examples
Minimal Server
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_hello(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
xHttpResponseSetHeader(w, "Content-Type", "text/plain");
xHttpResponseSend(w, "Hello, World!\n", 14);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerRoute(server, "GET /hello", on_hello, NULL);
xHttpServerListen(server, "0.0.0.0", 8080);
printf("Listening on :8080\n");
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
JSON API with POST
#include <stdio.h>
#include <string.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_echo(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)arg;
xHttpResponseSetHeader(w, "Content-Type", "application/json");
xHttpResponseSend(w, req->body, req->body_len);
}
static void on_not_found(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
const char *body = "{\"error\": \"not found\"}";
xHttpResponseSetStatus(w, 404);
xHttpResponseSetHeader(w, "Content-Type", "application/json");
xHttpResponseSend(w, body, strlen(body));
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerSetMaxBodySize(server, 4 * 1024 * 1024); /* 4 MiB */
xHttpServerRoute(server, "POST /echo", on_echo, NULL);
xHttpServerListen(server, NULL, 9090);
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
Server-Sent Events (SSE)
#include <stdio.h>
#include <string.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_events(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
xHttpResponseSetHeader(w, "Content-Type", "text/event-stream");
xHttpResponseSetHeader(w, "Cache-Control", "no-cache");
xHttpResponseWrite(w, "data: hello\n\n", 13);
xHttpResponseWrite(w, "data: world\n\n", 13);
/* xHttpResponseEnd(w) is optional; auto-called on return */
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerRoute(server, "GET /events", on_events, NULL);
xHttpServerListen(server, NULL, 8080);
printf("SSE server on :8080/events\n");
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
RESTful API with Path Parameters
#include <stdio.h>
#include <string.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_get_user(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)arg;
size_t id_len = 0;
const char *id = xHttpRequestParam(req, "id", &id_len);
char body[128];
int len = snprintf(body, sizeof(body),
"{\"user_id\": \"%.*s\"}\n", (int)id_len, id);
xHttpResponseSetHeader(w, "Content-Type", "application/json");
xHttpResponseSend(w, body, (size_t)len);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerRoute(server, "GET /users/:id", on_get_user, NULL);
xHttpServerListen(server, NULL, 8080);
printf("REST API on :8080\n");
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
HTTPS Server
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_hello(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
xHttpResponseSetHeader(w, "Content-Type", "text/plain");
xHttpResponseSend(w, "Hello, HTTPS!\n", 14);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerRoute(server, "GET /hello", on_hello, NULL);
// TLS configuration
xTlsConf tls = {
.cert = "/path/to/server.pem",
.key = "/path/to/server-key.pem",
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &tls);
printf("HTTPS server on :8443\n");
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
HTTPS Server with Mutual TLS (mTLS)
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_secure(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
xHttpResponseSetHeader(w, "Content-Type", "text/plain");
xHttpResponseSend(w, "mTLS verified!\n", 15);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerRoute(server, "GET /secure", on_secure, NULL);
// Require client certificates
xTlsConf tls = {
.cert = "/path/to/server.pem",
.key = "/path/to/server-key.pem",
.ca = "/path/to/ca.pem",
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &tls);
printf("mTLS server on :8443\n");
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
HTTP + HTTPS on Different Ports
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_hello(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
xHttpResponseSend(w, "Hello!\n", 7);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerRoute(server, "GET /hello", on_hello, NULL);
// Serve HTTP on port 8080
xHttpServerListen(server, "0.0.0.0", 8080);
// Serve HTTPS on port 8443
xTlsConf tls = {
.cert = "/path/to/server.pem",
.key = "/path/to/server-key.pem",
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &tls);
printf("HTTP on :8080, HTTPS on :8443\n");
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
Multiple Routes with Shared State
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/server.h>
typedef struct {
int counter;
} AppState;
static void on_count(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req;
AppState *state = (AppState *)arg;
state->counter++;
char body[64];
int len = snprintf(body, sizeof(body), "{\"count\": %d}\n", state->counter);
xHttpResponseSetHeader(w, "Content-Type", "application/json");
xHttpResponseSend(w, body, (size_t)len);
}
static void on_health(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
xHttpResponseSend(w, "ok\n", 3);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
AppState state = { .counter = 0 };
xHttpServerRoute(server, "POST /count", on_count, &state);
xHttpServerRoute(server, "GET /health", on_health, NULL);
xHttpServerListen(server, NULL, 8080);
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
Best Practices
- Don't block in handlers. Handlers run on the event loop thread. Blocking delays all other connections.
- Always call
xHttpResponseSend()orxHttpResponseWrite(). If the handler returns without sending, a default 200 OK with empty body is sent automatically — but it's better to be explicit. - Don't mix
SendandWrite.xHttpResponseSend()is for one-shot responses;xHttpResponseWrite()is for streaming. They are mutually exclusive — calling one after the other returnsxErrno_InvalidState. - Configure limits before listening.
SetIdleTimeout,SetMaxHeaderSize, andSetMaxBodySizemust be called beforexHttpServerListen()/xHttpServerListenTls(). - Register routes before listening. Routes should be set up before the server starts accepting connections.
- Use
xHttpServerListenTls()for HTTPS. Provide valid PEM certificate and key files. For mTLS, setca(verification is enabled by default). - Serve HTTP and HTTPS on different ports. Call both
xHttpServerListen()andxHttpServerListenTls()on the same server instance to support both protocols simultaneously. - Destroy server before event loop.
xHttpServerDestroy()closes all connections and frees all resources. - Copy data you need to keep.
xHttpRequestpointers (url,headers,body) are only valid during the handler callback.
Comparison with Other Libraries
| Feature | xhttp server.h | libuv + http-parser | libmicrohttpd | Go net/http | Node.js http |
|---|---|---|---|---|---|
| I/O Model | Async (event loop) | Async (event loop) | Threaded / select | Goroutines | Async (event loop) |
| Event Loop | xEventLoop integration | libuv | Internal | Go runtime | libuv (V8) |
| HTTP Parser | llhttp (H1) + nghttp2 (H2) | http-parser / llhttp | Internal | Internal | llhttp |
| Streaming Response | Built-in (Write/End) | Manual | Manual | Built-in (Flusher) | Built-in (write/end) |
| Routing | Built-in (first match) | None (manual) | None (manual) | Built-in (ServeMux) | None (manual) |
| Keep-Alive | Automatic | Manual | Automatic | Automatic | Automatic |
| Thread Model | Single-threaded | Single-threaded | Multi-threaded | Multi-goroutine | Single-threaded |
| TLS/HTTPS | Built-in (ListenTLS, mTLS) | Manual (libuv + OpenSSL) | Built-in | Built-in (ListenAndServeTLS) | Built-in (https.createServer) |
| Language | C99 | C | C | Go | JavaScript |
Key Differentiator: xhttp server provides a complete, single-threaded HTTP/1.1 & HTTP/2 server with built-in routing, streaming responses, TLS/HTTPS, and automatic keep-alive — all integrated with xEventLoop. HTTP/1.1 and HTTP/2 coexist on the same port via automatic protocol detection (Prior Knowledge for cleartext, ALPN for TLS). Unlike libuv + http-parser (which requires manual response assembly and TLS integration) or libmicrohttpd (which uses threads), xhttp keeps everything on one thread with zero synchronization overhead. The TLS layer supports mutual TLS (mTLS) with client certificate verification, and the streaming API (xHttpResponseWrite/xHttpResponseEnd) makes it straightforward to implement SSE or chunked streaming without external dependencies.
Relationship with Other Modules
- xbase — Uses
xEventLoopfor I/O multiplexing,xSocketfor non-blocking socket management, and socket timeouts for idle connection detection. - xbuf — Uses
xBufferfor request parsing accumulation (URL, headers, body) andxIOBufferfor read/write buffering with scatter-gather I/O. - llhttp — External dependency. Provides incremental HTTP/1.1 request parsing via callbacks, isolated behind the
xHttpProtovtable inproto_h1.c. - nghttp2 — External dependency. Provides HTTP/2 frame processing, HPACK header compression, and stream management, isolated behind the
xHttpProtovtable inproto_h2.c. - OpenSSL / Mbed TLS — External dependency (TLS backend, compile-time selection via
X_TLS_BACKEND). Provides TLS handshake, encryption, certificate verification, and ALPN negotiation forxHttpServerListenTls().
ws.h — WebSocket Server
Introduction
ws.h provides a callback-driven WebSocket interface integrated with the xhttp server. For pure WebSocket services, call xWsServe() to create a server in one line. For mixed HTTP + WebSocket endpoints, call xWsUpgrade() inside a regular HTTP handler to perform the RFC 6455 upgrade handshake. The library handles frame codec, ping/pong, fragment reassembly, and close negotiation automatically.
All callbacks are dispatched on the event loop thread — no locks or thread pools required.
Design Philosophy
-
Handler-Initiated Upgrade — WebSocket connections start as regular HTTP requests. The user calls
xWsUpgrade()inside anxHttpHandlerFuncto perform the upgrade. This keeps routing unified: WebSocket endpoints are just HTTP routes. -
Callback-Driven I/O — Three optional callbacks (
on_open,on_message,on_close) cover the full connection lifecycle. The library handles all framing, masking, and control frames internally. -
Automatic Protocol Handling — Ping/pong is answered automatically. Fragmented messages are reassembled before delivery. Close handshake follows RFC 6455 §5.5.1 with a 5-second timeout for the peer's response.
-
Connection Hijacking — On successful upgrade, the HTTP connection's socket and transport layer are transferred to a new
xWsConnobject. The HTTP connection is destroyed; the WebSocket connection takes full ownership of the file descriptor. -
Pluggable Crypto Backend — The handshake requires SHA-1 and Base64 for
Sec-WebSocket-Acceptcomputation. The crypto backend is selected at compile time: OpenSSL, Mbed TLS, or a built-in implementation.
Architecture
graph TD
subgraph "Application"
APP["User Code"]
HANDLER["HTTP Handler"]
WS_CBS["xWsCallbacks"]
end
subgraph "xhttp WebSocket"
UPGRADE["xWsUpgrade()"]
HANDSHAKE["Handshake<br/>(RFC 6455 §4)"]
CRYPTO["SHA-1 + Base64<br/>(pluggable backend)"]
WSCONN["xWsConn"]
PARSER["Frame Parser<br/>(incremental)"]
ENCODER["Frame Encoder"]
FRAG["Fragment<br/>Reassembly"]
CTRL["Control Frames<br/>(Ping/Pong/Close)"]
end
subgraph "xbase"
LOOP["xEventLoop"]
SOCK["xSocket"]
TIMER["Idle Timer"]
end
APP -->|"xHttpServerRoute"| HANDLER
HANDLER -->|"xWsUpgrade(w, req, cbs)"| UPGRADE
UPGRADE --> HANDSHAKE
HANDSHAKE --> CRYPTO
HANDSHAKE -->|"101 Switching Protocols"| WSCONN
WSCONN --> PARSER
WSCONN --> ENCODER
PARSER --> FRAG
PARSER --> CTRL
FRAG -->|"on_message"| WS_CBS
CTRL -->|"auto pong"| ENCODER
WSCONN --> SOCK
SOCK --> LOOP
TIMER --> LOOP
style WSCONN fill:#4a90d9,color:#fff
style LOOP fill:#50b86c,color:#fff
style PARSER fill:#9b59b6,color:#fff
style HANDSHAKE fill:#f5a623,color:#fff
Implementation Details
Upgrade Handshake Flow
sequenceDiagram
participant Client as Browser
participant Handler as HTTP Handler
participant Upgrade as xWsUpgrade()
participant Conn as xHttpConn_
participant WS as xWsConn
Client->>Handler: GET /ws (Upgrade: websocket)
Handler->>Upgrade: xWsUpgrade(w, req, &cbs, arg)
Upgrade->>Upgrade: Validate headers
Note over Upgrade: Method=GET<br/>Upgrade: websocket<br/>Connection: Upgrade<br/>Sec-WebSocket-Version: 13<br/>Sec-WebSocket-Key: ...
Upgrade->>Upgrade: SHA1(Key + GUID) → Base64
Upgrade->>Client: 101 Switching Protocols
Upgrade->>Conn: Hijack socket + transport
Upgrade->>WS: xWsConnCreate()
WS->>Client: on_open callback fires
Connection Lifecycle
stateDiagram-v2
[*] --> Open: xWsUpgrade() succeeds
Open --> Open: Data frames (text/binary)
Open --> Open: Ping → auto Pong
Open --> CloseSent: xWsClose() called
Open --> CloseReceived: Peer sends Close
CloseSent --> Closed: Peer Close received
CloseSent --> Closed: 5s timeout
CloseReceived --> Closed: Echo Close flushed
Open --> Closed: I/O error
Open --> CloseSent: Idle timeout (1001)
Closed --> [*]: on_close + destroy
Frame Processing
When data arrives on the socket, the incremental frame parser (xWsFrameParser) extracts complete frames from the xIOBuffer. Each frame is processed based on its opcode:
| Opcode | Handling |
|---|---|
| Text (0x1) | Deliver via on_message |
| Binary (0x2) | Deliver via on_message |
| Continuation (0x0) | Append to fragment buffer |
| Ping (0x9) | Auto-reply with Pong |
| Pong (0xA) | Ignored |
| Close (0x8) | Close handshake |
Fragment Reassembly
Fragmented messages are reassembled transparently:
- First fragment (FIN=0, opcode=Text/Binary) starts accumulation in
frag_buf. - Continuation frames (opcode=0x0) append to
frag_buf. - Final fragment (FIN=1, opcode=0x0) triggers reassembly and delivers the complete message via
on_message.
Protocol violations (e.g., new message mid-fragment) result in a Close frame with status 1002.
Close State Machine
XDEF_ENUM(xWsCloseState){
xWsCloseState_Open, // Normal operating state
xWsCloseState_CloseSent, // We sent Close, waiting for peer
xWsCloseState_CloseReceived, // Peer sent Close, we replied
xWsCloseState_Closed, // Connection fully closed
};
- Server-initiated close:
xWsClose()sends a Close frame and transitions toCLOSE_SENT. A 5-second timer waits for the peer's Close response. - Peer-initiated close: The peer's Close frame is echoed back, transitioning to
CLOSE_RECEIVED. After the echo is flushed,on_closefires and the connection is destroyed. - Idle timeout: After the configured idle period with no data, a Close frame with code 1001 (Going Away) is sent.
Internal File Structure
| File | Role |
|---|---|
ws.h | Public API (types, callbacks, functions) |
ws.c | Connection lifecycle, I/O, frame dispatch |
ws_handshake_server.c | Server upgrade handshake (RFC 6455 §4.2) |
ws_frame.h/c | Frame codec (parse + encode) |
ws_crypto.h | SHA-1 + Base64 interface |
ws_crypto_openssl.c | OpenSSL backend |
ws_crypto_mbedtls.c | Mbed TLS backend |
ws_crypto_builtin.c | Built-in (no TLS dep) |
ws_serve.c | xWsServe() convenience wrapper |
ws_private.h | Internal data structures |
API Reference
Types
| Type | Description |
|---|---|
xWsConn | Opaque WebSocket connection handle |
xWsOpcode | Message type: Text (0x1), Binary (0x2) |
xWsCallbacks | Struct of 3 optional callback pointers |
Callback Signatures
xWsOnOpenFunc
typedef void (*xWsOnOpenFunc)(xWsConn conn, void *arg);
Called when the WebSocket connection is established. conn is valid until on_close returns.
xWsOnMessageFunc
typedef void (*xWsOnMessageFunc)(
xWsConn conn, xWsOpcode opcode,
const void *payload, size_t len,
void *arg);
Called when a complete message is received. Fragmented messages are reassembled before delivery. payload is valid only during the callback.
xWsOnCloseFunc
typedef void (*xWsOnCloseFunc)(
xWsConn conn, uint16_t code,
const char *reason, size_t len,
void *arg);
Called when the connection is closed (clean or abnormal). After this callback returns, conn is invalid.
xWsCallbacks
typedef struct {
xWsOnOpenFunc on_open; // optional
xWsOnMessageFunc on_message; // optional
xWsOnCloseFunc on_close; // optional
} xWsCallbacks;
Functions
| Function | Description |
|---|---|
xWsServe | One-call WebSocket-only server |
xWsUpgrade | Upgrade HTTP → WebSocket |
xWsSend | Send a text or binary message |
xWsClose | Initiate graceful close |
xWsServe
xHttpServer xWsServe(
xEventLoop loop,
const char *host,
uint16_t port,
const xWsCallbacks *callbacks,
void *arg);
Convenience function that creates an HTTP server, registers a catch-all route that upgrades every incoming request to WebSocket, and starts listening. Returns the server handle for later cleanup via xHttpServerDestroy(), or NULL on failure.
Parameters:
loop— Event loop (must not be NULL).host— Bind address (e.g."0.0.0.0"), or NULL.port— Port number to listen on.callbacks— WebSocket event callbacks (not NULL).arg— User argument forwarded to all callbacks.
Returns: Server handle, or NULL on failure.
xWsUpgrade
xErrno xWsUpgrade(
xHttpResponseWriter writer,
const xHttpRequest *req,
const xWsCallbacks *callbacks,
void *arg);
Call inside an xHttpHandlerFunc to upgrade the HTTP connection to WebSocket. On success, the handler must return immediately — the HTTP connection has been hijacked.
On failure (bad headers, wrong method), an HTTP error response (400/405) is sent automatically and a non-Ok error code is returned.
Parameters:
writer— Response writer from the handler.req— HTTP request from the handler.callbacks— WebSocket event callbacks (not NULL).arg— User argument forwarded to all callbacks.
Returns: xErrno_Ok on success.
xWsSend
xErrno xWsSend(
xWsConn conn, xWsOpcode opcode,
const void *payload, size_t len);
Send a message over the WebSocket connection. The payload is framed and queued for asynchronous transmission.
Parameters:
conn— WebSocket connection handle.opcode—xWsOpcode_TextorxWsOpcode_Binary.payload— Message data.len— Payload length in bytes.
Returns: xErrno_Ok on success, xErrno_InvalidState if the connection is closing.
xWsClose
xErrno xWsClose(xWsConn conn, uint16_t code);
Initiate a graceful close. Sends a Close frame with the given status code. The connection remains open until the peer responds or a 5-second timeout expires.
Parameters:
conn— WebSocket connection handle.code— Close status code (e.g., 1000 for normal).
Returns: xErrno_Ok on success.
Close Status Codes
| Code | Constant | Meaning |
|---|---|---|
| 1000 | XWS_CLOSE_NORMAL | Normal closure |
| 1001 | XWS_CLOSE_GOING_AWAY | Server shutting down |
| 1002 | XWS_CLOSE_PROTOCOL_ERR | Protocol error |
| 1003 | XWS_CLOSE_UNSUPPORTED | Unsupported data |
| 1005 | XWS_CLOSE_NO_STATUS | No status received |
| 1006 | XWS_CLOSE_ABNORMAL | Abnormal closure |
Usage Examples
Echo Server (with xWsServe)
#include <x/base/event.h>
#include <x/http/ws.h>
#include <stdio.h>
#include <string.h>
static void on_open(xWsConn conn, void *arg) {
(void)arg;
const char *hi = "Welcome!";
xWsSend(conn, xWsOpcode_Text, hi, strlen(hi));
}
static void on_message(xWsConn conn, xWsOpcode op, const void *data, size_t len, void *arg) {
(void)arg;
xWsSend(conn, op, data, len);
}
static void on_close(xWsConn conn, uint16_t code, const char *reason, size_t len, void *arg) {
(void)conn; (void)reason; (void)len; (void)arg;
printf("closed: %u\n", code);
}
static const xWsCallbacks ws_cbs = {
.on_open = on_open,
.on_message = on_message,
.on_close = on_close,
};
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer srv = xWsServe(loop, "0.0.0.0", 8080, &ws_cbs, NULL);
if (!srv) return 1;
printf("ws://localhost:8080/\n");
xEventLoopRun(loop);
xHttpServerDestroy(srv);
xEventLoopDestroy(loop);
return 0;
}
Echo Server (with xWsUpgrade)
#include <x/base/event.h>
#include <x/http/server.h>
#include <x/http/ws.h>
#include <stdio.h>
#include <string.h>
static const xWsCallbacks ws_cbs = { ... };
static void ws_handler(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)arg;
xWsUpgrade(w, req, &ws_cbs, NULL);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer srv = xHttpServerCreate(loop);
xHttpServerRoute(srv, "GET /ws", ws_handler, NULL);
xHttpServerListen(srv, "0.0.0.0", 8080);
printf("ws://localhost:8080/ws\n");
xEventLoopRun(loop);
xHttpServerDestroy(srv);
xEventLoopDestroy(loop);
return 0;
}
Per-Connection User Data
typedef struct {
char username[64];
int msg_count;
} Session;
static void on_open(xWsConn conn, void *arg) {
Session *s = (Session *)arg;
snprintf(s->username, sizeof(s->username), "user_%p", (void *)conn);
s->msg_count = 0;
}
static void on_message(xWsConn conn, xWsOpcode op, const void *data, size_t len, void *arg) {
Session *s = (Session *)arg;
s->msg_count++;
printf("[%s] msg #%d: %.*s\n", s->username, s->msg_count, (int)len, (const char *)data);
xWsSend(conn, op, data, len);
}
static void ws_handler(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)arg;
Session *s = calloc(1, sizeof(Session));
xWsCallbacks cbs = {
.on_open = on_open,
.on_message = on_message,
.on_close = on_close_free_session,
};
xWsUpgrade(w, req, &cbs, s);
}
Graceful Server-Initiated Close
static void on_message(xWsConn conn, xWsOpcode op, const void *data, size_t len, void *arg) {
(void)op; (void)arg;
if (len == 4 && memcmp(data, "quit", 4) == 0) {
xWsClose(conn, 1000); // normal close
return;
}
xWsSend(conn, op, data, len);
}
JavaScript Client
<script>
const ws = new WebSocket('ws://localhost:8080/ws');
ws.onopen = () => console.log('connected');
ws.onmessage = (e) => console.log('< ' + e.data);
ws.onclose = (e) =>
console.log('closed: ' + e.code);
// Send a message
ws.send('Hello, server!');
</script>
Best Practices
- Return immediately after
xWsUpgrade(). On success, the HTTP connection is hijacked. Do not call anyxHttpResponse*functions afterward. - Don't block in callbacks. All callbacks run on the event loop thread. Blocking delays all other I/O.
- Copy payload if needed. The
payloadpointer inon_messageis valid only during the callback. Copy the data if you need it later. - Use
xWsClose()for graceful shutdown. Avoid dropping connections without a Close handshake. - Handle
on_closefor cleanup. Free per-connection resources inon_close, as thexWsConnhandle becomes invalid after the callback returns. - Idle timeout is inherited. The WebSocket connection inherits the HTTP server's
idle_timeout_mssetting. Adjust it viaxHttpServerSetIdleTimeout()if needed.
Comparison with Other Libraries
| Feature | xhttp WS | libwebsockets | uWebSockets |
|---|---|---|---|
| Integration | xEventLoop | Own loop | Own loop |
| Upgrade | In HTTP handler | Separate | Separate |
| Fragment reassembly | Automatic | Automatic | Automatic |
| Ping/Pong | Automatic | Automatic | Automatic |
| Close handshake | RFC 6455 | RFC 6455 | RFC 6455 |
| TLS | Via xhttp | Built-in | Built-in |
| Language | C99 | C | C++ |
| Dependencies | xbase only | OpenSSL | None |
Key Differentiator: xhttp's WebSocket server is unique in its handler-initiated upgrade pattern. Instead of a separate WebSocket server, you register a normal HTTP route and call xWsUpgrade() inside the handler. This keeps routing, middleware, and mixed HTTP+WS endpoints unified under a single server instance.
ws.h — WebSocket Client
Introduction
ws.h provides xWsConnect(), an asynchronous WebSocket client that integrates with xbase's event loop. The entire connection process — DNS resolution, TCP connect, optional TLS handshake, and HTTP Upgrade — runs fully asynchronously. Once connected, the same callback-driven model (on_open, on_message, on_close) and the same xWsConn handle are used for both client and server connections.
Design Philosophy
-
Fully Asynchronous Connection —
xWsConnect()returns immediately. The multi-phase connection process (DNS → TCP → TLS → HTTP Upgrade) is driven entirely by the event loop. No threads or blocking calls. -
Shared Connection Model — Once the handshake completes, a client
xWsConnis identical to a serverxWsConn. The samexWsSend(),xWsClose(), and callback interfaces apply. Code that operates onxWsConndoesn't need to know which side initiated the connection. -
Failure via
on_close— If the connection fails at any stage (DNS, TCP, TLS, or HTTP Upgrade),on_closeis invoked with an error code.on_openis never called for failed connections. This simplifies error handling: cleanup always happens in one place. -
Client-Side Masking — Per RFC 6455, client-to-server frames must be masked. The library handles this automatically when the connection is created in client mode.
Architecture
graph TD
subgraph "Application"
APP["User Code"]
CBS["xWsCallbacks"]
CONF["xWsConnectConf"]
end
subgraph "xWsConnect State Machine"
CONNECT["xWsConnect()"]
DNS["DNS Resolution"]
TCP["TCP Connect"]
TLS["TLS Handshake<br/>(wss:// only)"]
UPGRADE["HTTP Upgrade<br/>Request/Response"]
VALIDATE["Validate 101<br/>+ Sec-WebSocket-Accept"]
end
subgraph "Established Connection"
WSCONN["xWsConn<br/>(client mode)"]
SEND["xWsSend()"]
CLOSE["xWsClose()"]
end
subgraph "xbase"
LOOP["xEventLoop"]
SOCK["xSocket"]
TIMER["Timeout Timer"]
end
APP --> CONF
APP --> CBS
CONF --> CONNECT
CBS --> CONNECT
CONNECT --> DNS
DNS --> TCP
TCP --> TLS
TLS --> UPGRADE
UPGRADE --> VALIDATE
VALIDATE -->|"Success"| WSCONN
VALIDATE -->|"Failure"| CBS
WSCONN --> SEND
WSCONN --> CLOSE
WSCONN --> SOCK
SOCK --> LOOP
TIMER --> LOOP
style WSCONN fill:#4a90d9,color:#fff
style LOOP fill:#50b86c,color:#fff
style CONNECT fill:#f5a623,color:#fff
style VALIDATE fill:#9b59b6,color:#fff
Implementation Details
Connection State Machine
The xWsConnector drives the connection through five phases, all on the event loop thread:
stateDiagram-v2
[*] --> DNS: xWsConnect() called
DNS --> TCP_CONNECT: Address resolved
TCP_CONNECT --> TLS_HANDSHAKE: Connected [wss]
TCP_CONNECT --> HTTP_UPGRADE_WRITE: Connected [ws]
TLS_HANDSHAKE --> HTTP_UPGRADE_WRITE: Handshake complete
HTTP_UPGRADE_WRITE --> HTTP_UPGRADE_READ: Request sent
HTTP_UPGRADE_READ --> DONE: 101 validated
DONE --> [*]: on_open fires
DNS --> [*]: Failure → on_close
TCP_CONNECT --> [*]: Failure → on_close
TLS_HANDSHAKE --> [*]: Failure → on_close
HTTP_UPGRADE_READ --> [*]: Bad response → on_close
DNS --> [*]: Timeout → on_close
TCP_CONNECT --> [*]: Timeout → on_close
Phase Details
| Phase | What Happens |
|---|---|
| DNS | xDnsResolve() resolves the hostname asynchronously. On success, proceeds to TCP. |
| TCP Connect | Creates an xSocket, calls connect(). Waits for the writable event (EINPROGRESS). |
| TLS Handshake | For wss:// URLs only. Initializes the TLS transport and drives the handshake via read/write events. |
| HTTP Upgrade Write | Builds the Upgrade request (with random Sec-WebSocket-Key) and flushes it to the server. |
| HTTP Upgrade Read | Reads the server's response, validates HTTP/1.1 101, Upgrade: websocket, Connection: Upgrade, and Sec-WebSocket-Accept. |
Handshake Flow
sequenceDiagram
participant App as Application
participant Conn as xWsConnector
participant DNS as xDnsResolve
participant Server as Remote Server
App->>Conn: xWsConnect(loop, conf, cbs, arg)
Conn->>DNS: Resolve hostname
DNS-->>Conn: Address resolved
Conn->>Server: TCP connect()
Server-->>Conn: Connected
Note over Conn,Server: (wss:// only) TLS handshake
Conn->>Server: GET /path HTTP/1.1<br/>Upgrade: websocket<br/>Sec-WebSocket-Key: ...
Server-->>Conn: HTTP/1.1 101 Switching Protocols<br/>Sec-WebSocket-Accept: ...
Conn->>Conn: Validate response
Conn->>App: on_open(conn, arg)
Timeout Handling
A configurable timeout (default 10 seconds) covers the entire connection process. If any phase takes too long, the timer fires, the connector is destroyed, and on_close is invoked with code 1006 (Abnormal Closure).
Internal File Structure
| File | Role |
|---|---|
ws.h | Public API (xWsConnect, xWsConnectConf) |
ws_connect.c | Async connection state machine |
ws_handshake_client.h/c | Build Upgrade request, validate 101 response |
ws_crypto.h | SHA-1 + Base64 for Sec-WebSocket-Accept |
transport_tls_client.h | TLS client transport init (shared xTlsCtx → per-connection SSL) |
transport_tls_client_openssl.c | OpenSSL TLS client transport implementation |
transport_tls_client_mbedtls.c | mbedTLS TLS client transport implementation |
API Reference
Types
| Type | Description |
|---|---|
xWsConn | Opaque WebSocket connection handle (shared with server) |
xWsOpcode | Message type: Text (0x1), Binary (0x2) |
xWsCallbacks | Struct of 3 optional callback pointers (shared with server) |
xWsConnectConf | Configuration for xWsConnect() |
xWsConnectConf
struct xWsConnectConf {
const char *url; // ws:// or wss:// URL (required)
const xTlsConf *tls; // TLS config for wss:// (NULL = defaults)
xTlsCtx tls_ctx; // Pre-created shared TLS context (priority over tls)
const char *headers; // Extra HTTP headers (NULL = none)
int timeout_ms; // Connect timeout (0 = 10000 ms)
};
| Field | Description |
|---|---|
url | WebSocket URL. Must start with ws:// or wss://. Required. |
tls | TLS configuration for wss:// connections. NULL uses system CA with verification enabled. Ignored for ws://. Ignored when tls_ctx is set. |
tls_ctx | Pre-created shared TLS context from xTlsCtxCreate(). Takes priority over tls. The caller retains ownership and must keep it alive for the lifetime of the connection. NULL = create from tls (or use defaults). |
headers | Extra HTTP headers appended to the Upgrade request. Format: "Key: Value\r\nKey2: Value2\r\n". NULL for none. |
timeout_ms | Timeout for the entire connection process in milliseconds. 0 uses the default (10000 ms). |
Callbacks
The same xWsCallbacks struct is used for both client and server connections. See WebSocket Server for callback signature details.
Client-specific behavior:
on_open— Called when the connection is fully established (101 validated). Not called on failure.on_close— Called on connection failure (DNS, TCP, TLS, or Upgrade error) or after a normal close. For failed connections,connisNULL.
Functions
xWsConnect
xErrno xWsConnect(
xEventLoop loop,
const xWsConnectConf *conf,
const xWsCallbacks *callbacks,
void *arg);
Initiate an asynchronous WebSocket client connection. Returns immediately; the connection process runs on the event loop.
Parameters:
loop— Event loop (must not be NULL).conf— Connection configuration (must not be NULL,conf->urlrequired).callbacks— WebSocket event callbacks (must not be NULL).arg— User argument forwarded to all callbacks.
Returns: xErrno_Ok if the async connection started, xErrno_InvalidArg for bad parameters (NULL pointers, invalid URL scheme).
xWsSend
xErrno xWsSend(
xWsConn conn, xWsOpcode opcode,
const void *payload, size_t len);
Send a message. Identical to the server-side API. Client frames are automatically masked per RFC 6455.
xWsClose
xErrno xWsClose(xWsConn conn, uint16_t code);
Initiate a graceful close. Identical to the server-side API.
Usage Examples
Connect and Echo
#include <x/base/event.h>
#include <x/http/ws.h>
#include <stdio.h>
#include <string.h>
static void on_open(xWsConn conn, void *arg) {
(void)arg;
const char *msg = "Hello, server!";
xWsSend(conn, xWsOpcode_Text, msg, strlen(msg));
}
static void on_message(xWsConn conn, xWsOpcode op, const void *data, size_t len, void *arg) {
(void)conn; (void)op; (void)arg;
printf("Received: %.*s\n", (int)len, (const char *)data);
xWsClose(conn, 1000);
}
static void on_close(xWsConn conn, uint16_t code, const char *reason, size_t len, void *arg) {
(void)conn; (void)reason; (void)len; (void)arg;
printf("Closed: %u\n", code);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xWsConnectConf conf = {0};
conf.url = "ws://localhost:8080/ws";
xWsCallbacks cbs = {
.on_open = on_open,
.on_message = on_message,
.on_close = on_close,
};
xWsConnect(loop, &conf, &cbs, NULL);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
Secure Connection (wss://)
#include <x/base/event.h>
#include <x/http/ws.h>
#include <x/net/tls.h>
static void on_open(xWsConn conn, void *arg) { /* ... */ }
static void on_message(xWsConn conn, xWsOpcode op, const void *data, size_t len, void *arg) { /* ... */ }
static void on_close(xWsConn conn, uint16_t code, const char *reason, size_t len, void *arg) { /* ... */ }
int main(void) {
xEventLoop loop = xEventLoopCreate();
// Skip certificate verification (dev only)
xTlsConf tls = {0};
tls.skip_verify = 1;
xWsConnectConf conf = {0};
conf.url = "wss://echo.example.com/ws";
conf.tls = &tls;
conf.timeout_ms = 5000;
xWsCallbacks cbs = {
.on_open = on_open,
.on_message = on_message,
.on_close = on_close,
};
xWsConnect(loop, &conf, &cbs, NULL);
xEventLoopRun(loop);
xEventLoopDestroy(loop);
return 0;
}
Shared TLS Context (Multiple Connections)
When creating many wss:// connections (e.g. reconnect loops or connection pools), use a shared xTlsCtx to avoid reloading certificates on every connection:
#include <x/base/event.h>
#include <x/http/ws.h>
#include <x/net/tls.h>
static void on_open(xWsConn conn, void *arg) { /* ... */ }
static void on_message(xWsConn conn, xWsOpcode op, const void *data, size_t len, void *arg) { /* ... */ }
static void on_close(xWsConn conn, uint16_t code, const char *reason, size_t len, void *arg) { /* ... */ }
int main(void) {
xEventLoop loop = xEventLoopCreate();
// Create a shared TLS context once
xTlsConf tls = {0};
tls.ca = "ca.pem";
xTlsCtx ctx = xTlsCtxCreate(&tls);
// All connections share the same ctx
xWsConnectConf conf = {0};
conf.url = "wss://echo.example.com/ws";
conf.tls_ctx = ctx; // shared, not copied
xWsCallbacks cbs = {
.on_open = on_open,
.on_message = on_message,
.on_close = on_close,
};
xWsConnect(loop, &conf, &cbs, NULL);
xEventLoopRun(loop);
// Destroy ctx after all connections are closed
xTlsCtxDestroy(ctx);
xEventLoopDestroy(loop);
return 0;
}
Custom Headers (Authentication)
xWsConnectConf conf = {0};
conf.url = "ws://api.example.com/stream";
conf.headers = "Authorization: Bearer token123\r\n"
"X-Client-Version: 1.0\r\n";
xWsConnect(loop, &conf, &cbs, NULL);
Connection Failure Handling
static void on_close(xWsConn conn, uint16_t code, const char *reason, size_t len, void *arg) {
if (conn == NULL) {
// Connection failed before establishing WebSocket
printf("Connection failed (code %u)\n", code);
// Optionally retry after a delay
return;
}
// Normal close after successful connection
printf("Disconnected: %u\n", code);
}
Binary Data
static void on_open(xWsConn conn, void *arg) {
uint8_t data[] = {0x00, 0x01, 0x02, 0xFF, 0xFE};
xWsSend(conn, xWsOpcode_Binary, data, sizeof(data));
}
Best Practices
- Check the return value of
xWsConnect(). It returnsxErrno_InvalidArgfor obviously bad parameters (NULL pointers, unsupported URL scheme). Network errors are reported asynchronously viaon_close. - Handle
conn == NULLinon_close. This indicates a connection failure before the WebSocket was established. Use this to implement retry logic. - Don't block in callbacks. All callbacks run on the event loop thread.
- Copy payload if needed. The
payloadpointer inon_messageis valid only during the callback. - Use
xWsClose()for graceful shutdown. The client sends a Close frame and waits for the server's response. - Set a reasonable timeout. The default 10-second timeout covers DNS + TCP + TLS + Upgrade. Adjust via
conf.timeout_msfor high-latency networks. - Never use
skip_verifyin production. It disables all certificate validation. Use a proper CA path or system CA bundle instead.
Comparison with Other Libraries
| Feature | xhttp WS Client | libwebsockets | wslay | civetweb |
|---|---|---|---|---|
| I/O Model | Async (event loop) | Async (own loop) | Sync (user drives) | Threaded |
| Event Loop | xEventLoop | Own loop | None | pthreads |
| DNS | Async (xDnsResolve) | Async (built-in) | Manual | Blocking |
| TLS | Via xnet | Built-in | Manual | Built-in |
| Client Masking | Automatic | Automatic | Automatic | Automatic |
| Connection Timeout | Configurable | Configurable | Manual | Configurable |
| Language | C99 | C | C | C |
| Dependencies | xbase + xnet | OpenSSL | None | None |
Key Differentiator: xhttp's WebSocket client runs entirely on the xbase event loop with zero blocking calls. The multi-phase connection (DNS → TCP → TLS → Upgrade) is a single async state machine. Combined with the shared xWsConn model, client and server code use identical APIs for sending, receiving, and closing — making bidirectional WebSocket applications straightforward.
TLS Context Sharing: For wss:// connections, the client supports a shared xTlsCtx (via conf.tls_ctx) that avoids reloading certificates and re-creating the SSL context on every connection. This is the same pattern used by xTcpConnect and xTcpListener, providing consistent TLS context management across all moo networking APIs.
sse.c — SSE Stream Client
Introduction
sse.c implements Server-Sent Events (SSE) support for xHttpClient. It provides xHttpClientGetSse() and xHttpClientDoSse() which subscribe to SSE endpoints and parse the event stream according to the W3C SSE specification. Each parsed event is delivered to a callback as it arrives, enabling real-time streaming — ideal for LLM API integration.
Design Philosophy
-
W3C Spec Compliance — The parser follows the W3C Server-Sent Events specification: field parsing (event, data, id, retry), comment handling, multi-line data joining with
\n, and default event type "message". -
Streaming Parse — Data is parsed incrementally as it arrives from libcurl's write callback. Complete lines are processed immediately; incomplete lines are buffered until more data arrives.
-
Shared Infrastructure — SSE requests reuse the same
curl_multihandle and event loop integration as regular HTTP requests. ThexHttpReqVtablemechanism allows SSE to plug in its own write callback and completion handler. -
User-Controlled Cancellation — The
xSseEventFunccallback returns anint: 0 to continue, non-zero to close the connection. This gives the user fine-grained control over when to stop streaming.
Architecture
graph TD
subgraph "SSE Request Flow"
SUBMIT["xHttpClientDoSse()"]
EASY["curl_easy + SSE headers"]
WRITE["sse_write_callback"]
PARSER["xSseParser_"]
EVENT["on_event(ev)"]
DONE["on_done(curl_code)"]
end
subgraph "Shared with Oneshot"
MULTI["curl_multi"]
LOOP["xEventLoop"]
CHECK["check_multi_info()"]
end
SUBMIT --> EASY
EASY --> MULTI
MULTI --> LOOP
LOOP -->|"fd ready"| WRITE
WRITE --> PARSER
PARSER -->|"event boundary"| EVENT
CHECK -->|"transfer done"| DONE
style PARSER fill:#4a90d9,color:#fff
style EVENT fill:#50b86c,color:#fff
Implementation Details
SSE Parser State Machine
stateDiagram-v2
[*] --> Buffering: Data arrives from curl
Buffering --> ParseLine: Complete line found (\\n or \\r\\n)
ParseLine --> FieldParse: Non-empty line
ParseLine --> DispatchEvent: Empty line (event boundary)
FieldParse --> Buffering: Continue parsing
DispatchEvent --> CallUser: data field exists
DispatchEvent --> Buffering: No data (skip)
CallUser --> Buffering: User returns 0 (continue)
CallUser --> [*]: User returns non-zero (close)
SSE Field Parsing
Each non-empty line is parsed as a field:
| Line Format | Field | Value |
|---|---|---|
:comment | (ignored) | — |
event:type | event_type | "type" |
data:payload | data | "payload" (accumulated with \n) |
id:123 | id | "123" (persists across events) |
retry:5000 | retry | 5000 (ms, must be all digits) |
unknown:foo | (ignored) | — |
Multi-line data: Multiple data: lines are joined with \n:
data:line1
data:line2
data:line3
→ ev.data = "line1\nline2\nline3"
Parser Internal Structure
struct xSseParser_ {
xBuffer buf; // Raw incoming data buffer
size_t pos; // Parse position within buf
int error; // Allocation failure flag
char *event_type; // Current event type (NULL = "message")
char *data; // Accumulated data lines
char *id; // Last event ID (persists across events)
int retry; // Retry delay in ms (-1 = not set)
};
Data Flow
sequenceDiagram
participant Server as SSE Server
participant Curl as libcurl
participant Writer as sse_write_callback
participant Parser as xSseParser_
participant User as User Callback
Server->>Curl: HTTP 200 text/event-stream
loop For each chunk
Curl->>Writer: sse_write_callback(chunk)
Writer->>Parser: sse_parser_feed(chunk)
Parser->>Parser: Buffer + parse lines
alt Empty line (event boundary)
Parser->>User: on_event(ev)
alt User returns 0
User->>Parser: Continue
else User returns non-zero
User->>Writer: Close connection
Writer->>Curl: Return 0 (abort)
end
end
end
Curl->>User: on_done(curl_code)
SSE Request Structure
struct xSseReq_ {
struct xHttpReq_ base; // Base request (shared with oneshot)
xSseEventFunc on_event; // Per-event callback
xSseDoneFunc on_done; // Stream-end callback
struct xSseParser_ parser; // SSE parser state
struct curl_slist *sse_headers; // Accept: text/event-stream + user headers
};
The SSE request uses a dedicated vtable:
sse_on_done— Invokes the user'son_donecallback.sse_on_cleanup— Frees SSE-specific resources (parser, headers).
Automatic Headers
xHttpClientDoSse() automatically adds:
Accept: text/event-streamCache-Control: no-cache
User-provided headers are merged after these defaults.
API Reference
Types
| Type | Description |
|---|---|
xSseEvent | SSE event: event (type), data, id, retry |
xSseEventFunc | int (*)(const xSseEvent *ev, void *arg) — return 0 to continue, non-zero to close |
xSseDoneFunc | void (*)(int curl_code, void *arg) — called when stream ends |
xSseEvent Fields
| Field | Type | Description |
|---|---|---|
event | const char * | Event type. "message" if omitted by server. |
data | const char * | Event data. Multi-line data joined by \n. |
id | const char * | Last event ID, or NULL. |
retry | int | Retry delay in ms, or -1 if not set. |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xHttpClientGetSse | xErrno xHttpClientGetSse(xHttpClient client, const char *url, xSseEventFunc on_event, xSseDoneFunc on_done, void *arg) | Subscribe to SSE endpoint (GET). | Not thread-safe |
xHttpClientDoSse | xErrno xHttpClientDoSse(xHttpClient client, const xHttpRequestConf *config, xSseEventFunc on_event, xSseDoneFunc on_done, void *arg) | Fully-configured SSE request. | Not thread-safe |
Usage Examples
Simple SSE Subscription
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/client.h>
static int on_event(const xSseEvent *ev, void *arg) {
(void)arg;
printf("[%s] %s\n", ev->event, ev->data);
return 0; // Continue receiving
}
static void on_done(int curl_code, void *arg) {
(void)arg;
printf("Stream ended (code=%d)\n", curl_code);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpClient client = xHttpClientCreate(loop, NULL);
xHttpClientGetSse(client, "https://example.com/events",
on_event, on_done, NULL);
xEventLoopRun(loop);
xHttpClientDestroy(client);
xEventLoopDestroy(loop);
return 0;
}
LLM API Streaming (OpenAI-Compatible)
#include <stdio.h>
#include <string.h>
#include <x/base/event.h>
#include <x/http/client.h>
static int on_event(const xSseEvent *ev, void *arg) {
(void)arg;
// OpenAI sends "[DONE]" as the final data
if (strcmp(ev->data, "[DONE]") == 0) {
printf("\n--- Stream complete ---\n");
return 1; // Close connection
}
// Parse JSON and extract content delta...
printf("%s", ev->data);
fflush(stdout);
return 0;
}
static void on_done(int curl_code, void *arg) {
(void)arg;
if (curl_code != 0)
printf("\nStream error (code=%d)\n", curl_code);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpClient client = xHttpClientCreate(loop, NULL);
const char *body =
"{"
" \"model\": \"gpt-4\","
" \"messages\": [{\"role\": \"user\", \"content\": \"Hello!\"}],"
" \"stream\": true"
"}";
const char *headers[] = {
"Content-Type: application/json",
"Authorization: Bearer sk-your-api-key",
NULL
};
xHttpRequestConf config = {
.url = "https://api.openai.com/v1/chat/completions",
.method = xHttpMethod_POST,
.body = body,
.body_len = strlen(body),
.headers = headers,
.timeout_ms = 60000, // 60s timeout for streaming
};
xHttpClientDoSse(client, &config, on_event, on_done, NULL);
xEventLoopRun(loop);
xHttpClientDestroy(client);
xEventLoopDestroy(loop);
return 0;
}
Early Cancellation
static int on_event(const xSseEvent *ev, void *arg) {
int *count = (int *)arg;
(*count)++;
printf("Event #%d: %s\n", *count, ev->data);
// Stop after 10 events
if (*count >= 10) {
printf("Received enough events, closing.\n");
return 1; // Non-zero = close connection
}
return 0;
}
Use Cases
-
LLM API Integration — Stream responses from OpenAI, Anthropic, Google Gemini, or any OpenAI-compatible API. Use
xHttpClientDoSse()with POST method and JSON body. -
Real-Time Notifications — Subscribe to server push notifications (chat messages, stock prices, IoT sensor data) via SSE endpoints.
-
Log Streaming — Tail remote log streams delivered as SSE events.
Best Practices
- Use
xHttpClientDoSse()for LLM APIs. Most LLM APIs require POST with a JSON body and custom headers.GetSseis only for simple GET endpoints. - Handle
[DONE]signals. Many LLM APIs send a special[DONE]data payload to signal the end of the stream. Return non-zero fromon_eventto close cleanly. - Set appropriate timeouts. Streaming responses can take a long time. Set
timeout_mshigh enough (e.g., 60000ms) to avoid premature timeouts. - Don't block in
on_event. The callback runs on the event loop thread. Blocking delays all other I/O. - Copy event data if needed.
xSseEventpointers are valid only during the callback.
Comparison with Other Libraries
| Feature | xhttp SSE | eventsource (JS) | sseclient-py | libcurl (manual) |
|---|---|---|---|---|
| Spec Compliance | W3C SSE | W3C SSE | W3C SSE | Manual parsing |
| Integration | xEventLoop (async) | Browser event loop | Blocking iterator | Manual |
| POST Support | Yes (DoSse) | No (GET only) | No (GET only) | Manual |
| Cancellation | Callback return value | close() | Break loop | curl_easy_pause |
| Multi-line Data | Auto-joined with \n | Auto-joined | Auto-joined | Manual |
| Language | C99 | JavaScript | Python | C |
Key Differentiator: xhttp's SSE implementation is unique in supporting POST-based SSE (via xHttpClientDoSse), which is essential for LLM API integration. Most SSE libraries only support GET. The incremental parser integrates seamlessly with the event loop, delivering events as they arrive without buffering the entire stream.
TLS Deployment Guide
This guide covers end-to-end TLS deployment for xhttp, including certificate generation, server and client configuration, and mutual TLS (mTLS). For API reference, see server.md and client.md.
Prerequisites
- OpenSSL CLI — Used for certificate generation (
opensslcommand). - TLS backend compiled — moo must be built with
X_TLS_BACKEND=openssl(ormbedtls). Without a TLS backend,xHttpServerListenTls()returnsxErrno_NotSupported.
Check your build:
# If X_HAS_OPENSSL is defined, TLS is available
grep -r "X_HAS_OPENSSL" xhttp/
Certificate Generation
Self-Signed Certificate (Development)
For quick local development and testing:
openssl req -x509 -newkey rsa:2048 \
-keyout server-key.pem \
-out server.pem \
-days 365 -nodes \
-subj '/CN=localhost'
This produces:
server.pem— Self-signed certificateserver-key.pem— Unencrypted private key
Note: Self-signed certificates are not trusted by default. Clients must either set
skip_verify = 1or provide the certificate as a CA viaca.
CA-Signed Certificates (Production / mTLS)
For mutual TLS or production-like setups, create a private CA and sign both server and client certificates.
Step 1: Create a CA
# Generate CA private key and self-signed certificate
openssl req -x509 -newkey rsa:2048 \
-keyout ca-key.pem \
-out ca.pem \
-days 365 -nodes \
-subj '/CN=MyCA'
Step 2: Generate Server Certificate
# Generate server key + CSR
openssl req -newkey rsa:2048 \
-keyout server-key.pem \
-out server.csr \
-nodes \
-subj '/CN=localhost'
# Sign with CA
openssl x509 -req \
-in server.csr \
-CA ca.pem -CAkey ca-key.pem -CAcreateserial \
-out server.pem \
-days 365
# Clean up CSR
rm server.csr
Step 3: Generate Client Certificate (for mTLS)
# Generate client key + CSR
openssl req -newkey rsa:2048 \
-keyout client-key.pem \
-out client.csr \
-nodes \
-subj '/CN=MyClient'
# Sign with the same CA
openssl x509 -req \
-in client.csr \
-CA ca.pem -CAkey ca-key.pem -CAcreateserial \
-out client.pem \
-days 365
# Clean up CSR
rm client.csr
After these steps you have:
| File | Description |
|---|---|
ca.pem | CA certificate (trusted by both sides) |
ca-key.pem | CA private key (keep secure, not deployed) |
server.pem | Server certificate (signed by CA) |
server-key.pem | Server private key |
client.pem | Client certificate (signed by CA) |
client-key.pem | Client private key |
Deployment Scenarios
1. One-Way TLS (Server Authentication Only)
The most common setup: the client verifies the server's identity, but the server does not verify the client.
sequenceDiagram
participant Client
participant Server
Client->>Server: TLS ClientHello
Server->>Client: Certificate (server.pem)
Client->>Client: Verify server cert against CA
Client->>Server: Finished
Server->>Client: Finished
Note over Client,Server: Encrypted HTTP traffic
Server:
xTlsConf tls = {
.cert = "server.pem",
.key = "server-key.pem",
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &tls);
Client (with CA verification):
xTlsConf tls = {0};
tls.ca = "ca.pem";
xHttpClientConf conf = {.tls = &tls};
xHttpClient client =
xHttpClientCreate(loop, &conf);
xHttpClientGet(
client,
"https://localhost:8443/hello",
on_response, NULL);
Client (skip verification — development only):
xTlsConf tls = {0};
tls.skip_verify = 1;
xHttpClientConf conf = {.tls = &tls};
xHttpClient client =
xHttpClientCreate(loop, &conf);
2. Mutual TLS (mTLS)
Both sides authenticate each other. The server requires a valid client certificate signed by a trusted CA.
sequenceDiagram
participant Client
participant Server
Client->>Server: TLS ClientHello
Server->>Client: Certificate (server.pem) + CertificateRequest
Client->>Client: Verify server cert against CA
Client->>Server: Certificate (client.pem)
Server->>Server: Verify client cert against CA
Client->>Server: Finished
Server->>Client: Finished
Note over Client,Server: Mutually authenticated encrypted traffic
Server:
xTlsConf tls = {
.cert = "server.pem",
.key = "server-key.pem",
.ca = "ca.pem", // CA to verify client certs
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &tls);
Client:
xTlsConf tls = {0};
tls.ca = "ca.pem";
tls.cert = "client.pem";
tls.key = "client-key.pem";
xHttpClientConf conf = {.tls = &tls};
xHttpClient client =
xHttpClientCreate(loop, &conf);
xHttpClientGet(
client,
"https://localhost:8443/secure",
on_response, NULL);
3. HTTP + HTTPS on Different Ports
A single xHttpServer can serve both cleartext HTTP and HTTPS simultaneously:
// HTTP on port 8080
xHttpServerListen(server, "0.0.0.0", 8080);
// HTTPS on port 8443
xTlsConf tls = {
.cert = "server.pem",
.key = "server-key.pem",
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &tls);
Routes are shared — the same handlers serve both HTTP and HTTPS traffic.
Complete End-to-End Example
A full working example: CA-signed mTLS with server and client.
Generate Certificates
#!/bin/bash
set -e
# CA
openssl req -x509 -newkey rsa:2048 \
-keyout ca-key.pem -out ca.pem \
-days 365 -nodes -subj '/CN=TestCA'
# Server
openssl req -newkey rsa:2048 \
-keyout server-key.pem -out server.csr \
-nodes -subj '/CN=localhost'
openssl x509 -req -in server.csr \
-CA ca.pem -CAkey ca-key.pem -CAcreateserial \
-out server.pem -days 365
rm server.csr
# Client
openssl req -newkey rsa:2048 \
-keyout client-key.pem -out client.csr \
-nodes -subj '/CN=MyClient'
openssl x509 -req -in client.csr \
-CA ca.pem -CAkey ca-key.pem -CAcreateserial \
-out client.pem -days 365
rm client.csr
echo "Generated: ca.pem, server.pem, server-key.pem, client.pem, client-key.pem"
Server Code
#include <stdio.h>
#include <string.h>
#include <x/base/event.h>
#include <x/http/server.h>
static void on_secure(xHttpResponseWriter w, const xHttpRequest *req, void *arg) {
(void)req; (void)arg;
xHttpResponseSetHeader(w, "Content-Type", "text/plain");
xHttpResponseSend(w, "mTLS OK!\n", 9);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xHttpServer server = xHttpServerCreate(loop);
xHttpServerRoute(server, "GET /secure", on_secure, NULL);
xTlsConf tls = {
.cert = "server.pem",
.key = "server-key.pem",
.ca = "ca.pem",
};
xHttpServerListenTls(server, "0.0.0.0", 8443, &tls);
printf("mTLS server listening on :8443\n");
xEventLoopRun(loop);
xHttpServerDestroy(server);
xEventLoopDestroy(loop);
return 0;
}
Client Code
#include <stdio.h>
#include <x/base/event.h>
#include <x/http/client.h>
static void on_response(const xHttpResponse *resp, void *arg) {
(void)arg;
if (resp->curl_code == 0) {
printf("HTTP %ld: %.*s\n", resp->status_code,
(int)resp->body_len, resp->body);
} else {
printf("TLS error: %s\n", resp->curl_error);
}
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xTlsConf tls = {0};
tls.ca = "ca.pem";
tls.cert = "client.pem";
tls.key = "client-key.pem";
xHttpClientConf conf = {.tls = &tls};
xHttpClient client =
xHttpClientCreate(loop, &conf);
xHttpClientGet(client, "https://localhost:8443/secure",
on_response, NULL);
xEventLoopRun(loop);
xHttpClientDestroy(client);
xEventLoopDestroy(loop);
return 0;
}
Verify with curl
# One-way TLS (skip verify)
curl -k https://localhost:8443/secure
# One-way TLS (with CA)
curl --cacert ca.pem https://localhost:8443/secure
# mTLS
curl --cacert ca.pem \
--cert client.pem \
--key client-key.pem \
https://localhost:8443/secure
skip_verify Behavior
| Value | Behavior |
|---|---|
0 (default) | Peer verification enabled. Server verifies client cert (if ca is set); client verifies server cert. |
| non-zero | All peer verification disabled. Development only. |
ALPN and HTTP/2 over TLS
When TLS is enabled, ALPN (Application-Layer Protocol Negotiation) automatically selects the HTTP protocol:
- If the client supports HTTP/2, ALPN negotiates
h2and the connection uses HTTP/2 framing. - Otherwise, ALPN falls back to
http/1.1.
This is transparent to application code — the same routes and handlers work regardless of the negotiated protocol.
Troubleshooting
| Symptom | Cause | Fix |
|---|---|---|
xErrno_NotSupported from ListenTls | No TLS backend compiled | Rebuild with X_TLS_BACKEND=openssl |
Client gets curl_code != 0, status_code == 0 | TLS handshake failed | Check cert paths, CA trust, and skip_verify settings |
| Self-signed cert rejected | Client verifies against system CA bundle | Set ca to the self-signed cert, or use skip_verify = 1 for dev |
| mTLS handshake fails | Client didn't provide cert, or cert not signed by server's ca | Ensure client cert is signed by the same CA specified in server's ca |
| "wrong CA path" error | ca points to non-existent file | Verify the file path exists and is readable |
Connection works with skip_verify but not without | Server cert CN doesn't match hostname, or CA not trusted | Use ca pointing to the signing CA, ensure CN matches the hostname |
Security Best Practices
- Never use
skip_verifyin production. It disables all certificate validation, making the connection vulnerable to MITM attacks. - Keep private keys secure.
ca-key.pem,server-key.pem, andclient-key.pemshould have restricted file permissions (chmod 600). - Use short-lived certificates. Set reasonable expiry (
-days) and rotate certificates before they expire. - For mTLS, set
caon the server side. Verification is enabled by default (skip_verify = 0), so the server will require a valid client certificate whencais set. - Don't deploy the CA private key. Only
ca.pem(the public certificate) needs to be distributed. Keepca-key.pemoffline or in a secure vault. - Match CN/SAN to hostname. The server certificate's Common Name (or Subject Alternative Name) should match the hostname clients use to connect.
API Quick Reference
Server Side
| Item | Description |
|---|---|
xTlsConf | Struct: cert, key, ca, key_password, alpn, skip_verify |
xHttpServerListenTls() | Start HTTPS listener with TLS config |
Client Side
| Item | Description |
|---|---|
xTlsConf | Struct: cert, key, ca, key_password, alpn, skip_verify |
xHttpClientConf | Struct: tls (pointer to xTlsConf), http_version |
xHttpClientCreate() | Create client with TLS config via xHttpClientConf. |
WebSocket Client Side
| Item | Description |
|---|---|
xTlsConf | Struct: cert, key, ca, key_password, alpn, skip_verify |
xTlsCtx | Opaque shared TLS context from xTlsCtxCreate() |
xWsConnectConf | Struct: tls (pointer to xTlsConf), tls_ctx (shared context, priority over tls) |
xWsConnect() | Initiate async WebSocket connection with optional TLS. |
For full API details, see server.md and client.md.
xlog — Async Logging
Introduction
xlog is moo's high-performance asynchronous logging module. It formats log entries on the calling thread and flushes them to a file (or stderr) on the event loop thread, decoupling I/O latency from application logic. Three operating modes — Timer, Notify, and Mixed — offer different trade-offs between flush latency and overhead.
Design Philosophy
-
Async by Default — Log messages are formatted on the calling thread and enqueued via a lock-free MPSC queue. The event loop thread drains the queue and writes to disk, ensuring that logging never blocks the caller (except for Fatal level).
-
Three Modes for Different Needs — Timer mode batches writes for throughput; Notify mode uses a pipe for low-latency delivery; Mixed mode combines both, using the timer for normal messages and the pipe for high-severity entries.
-
Event Loop Integration — The logger is bound to an
xEventLoopand uses its timer and I/O facilities. This means no dedicated logging thread — the event loop thread handles both I/O and log flushing. -
Thread-Local Context —
xLoggerEnter()sets the current thread's logger, enabling theXLOG_*()macros and bridging xbase's internalxLog()calls to the async pipeline.
Architecture
graph TD
subgraph "Application Threads"
T1["Thread 1<br/>xLoggerLog()"]
T2["Thread 2<br/>XLOG_INFO()"]
T3["Thread 3<br/>xLog() (xbase internal)"]
end
subgraph "Lock-Free Queue"
MPSC["MPSC Queue<br/>(xbase/mpsc.h)"]
end
subgraph "Event Loop Thread"
TIMER["Timer Callback<br/>(periodic flush)"]
PIPE["Pipe Callback<br/>(immediate flush)"]
FLUSH["logger_flush_entries()"]
WRITE["fwrite() + fflush()"]
ROTATE["File Rotation"]
end
subgraph "Output"
FILE["Log File"]
STDERR["stderr"]
end
T1 -->|"format + enqueue"| MPSC
T2 -->|"format + enqueue"| MPSC
T3 -->|"bridge_callback"| MPSC
MPSC --> FLUSH
TIMER --> FLUSH
PIPE --> FLUSH
FLUSH --> WRITE
WRITE --> FILE
WRITE --> STDERR
WRITE -->|"max_size exceeded"| ROTATE
style MPSC fill:#f5a623,color:#fff
style FLUSH fill:#50b86c,color:#fff
Sub-Module Overview
| File | Description | Doc |
|---|---|---|
logger.h | Async logger API, macros, and configuration | logger.md |
Quick Start
#include <x/base/event.h>
#include <x/log/logger.h>
int main(void) {
xEventLoop loop = xEventLoopCreate();
xLoggerConf conf = {
.loop = loop,
.path = "app.log",
.mode = xLogMode_Mixed,
.level = xLogLevel_Info,
.max_size = 10 * 1024 * 1024, // 10MB
.max_files = 5,
.flush_interval_ms = 100,
};
xLogger logger = xLoggerCreate(conf);
xLoggerEnter(logger); // Set as thread-local logger
XLOG_INFO("Application started, version %d.%d", 1, 0);
XLOG_WARN("Low memory: %zu bytes remaining", (size_t)1024);
// Run event loop (processes log flushes)
xEventLoopRun(loop);
xLoggerLeave();
xLoggerDestroy(logger);
xEventLoopDestroy(loop);
return 0;
}
Relationship with Other Modules
- xbase/event.h — The logger is bound to an
xEventLoopfor timer-driven and pipe-driven flush. - xbase/mpsc.h — Uses the lock-free
MPSC queueto pass log entries from producer threads to the event loop thread. - xbase/log.h —
xLoggerEnter()bridges xbase's internalxLog()calls to the async logger via the thread-local callback mechanism. - xbase/atomic.h — Uses
atomic operationsfor the lock-free entry freelist.
logger.h — High-Performance Async Logger
Introduction
logger.h provides xLogger, a high-performance asynchronous logger that formats log entries on the calling thread and flushes them to a file (or stderr) on the event loop thread. It supports three operating modes (Timer, Notify, Mixed), five severity levels, file rotation, synchronous flush, and seamless bridging with xbase's internal xLog() mechanism.
Design Philosophy
-
Format on Caller, Write on Loop — Log messages are formatted (
snprintf) on the calling thread into a pre-allocated entry buffer, then enqueued via the lock-free MPSC queue. The event loop thread dequeues and writes to disk. This decouples I/O latency from application logic. -
Three Operating Modes — Different applications have different latency/throughput requirements:
- Timer — Periodic flush (default 100ms). Best throughput, highest latency.
- Notify — Pipe-based immediate notification. Lowest latency, highest overhead.
- Mixed — Timer for normal messages, pipe for Error/Fatal. Best balance.
-
Lock-Free Entry Pool — A global Treiber stack freelist recycles log entry structs across all threads, avoiding
malloc/freeon the hot path. -
Fatal = Synchronous + Abort — Fatal-level messages bypass the async queue entirely: they are written directly to the file and followed by
abort(). This ensures the fatal message is never lost. -
xbase Bridge —
xLoggerEnter()registers a callback with xbase'sxLogSetCallback(), routing all internal moo error messages through the async logger.
Architecture
graph TD
subgraph "xLogger Internal"
MPSC["MPSC Queue<br/>(head, tail)"]
TIMER["xEventLoopTimer<br/>(periodic flush)"]
PIPE["Pipe<br/>(notify flush)"]
FLUSH_PIPE["Flush Request Pipe<br/>(sync flush)"]
FREELIST["Entry Freelist<br/>(Treiber stack)"]
FP["FILE *fp<br/>(log file or stderr)"]
end
subgraph "xbase Dependencies"
EVENT["xEventLoop"]
MPSC_LIB["xbase/mpsc.h"]
ATOMIC_LIB["xbase/atomic.h"]
LOG_LIB["xbase/log.h"]
end
TIMER --> EVENT
PIPE --> EVENT
FLUSH_PIPE --> EVENT
MPSC --> MPSC_LIB
FREELIST --> ATOMIC_LIB
style MPSC fill:#f5a623,color:#fff
style FREELIST fill:#4a90d9,color:#fff
Implementation Details
Three Operating Modes
graph LR
subgraph "Timer Mode"
T_ENQUEUE["Enqueue"] --> T_TIMER["Timer fires<br/>(every 100ms)"]
T_TIMER --> T_FLUSH["Flush all entries"]
end
subgraph "Notify Mode"
N_ENQUEUE["Enqueue"] --> N_PIPE["Write 1 byte to pipe"]
N_PIPE --> N_LOOP["Pipe readable event"]
N_LOOP --> N_FLUSH["Flush all entries"]
end
subgraph "Mixed Mode"
M_ENQUEUE["Enqueue"]
M_ENQUEUE -->|"Debug/Info/Warn"| M_TIMER["Timer fires"]
M_ENQUEUE -->|"Error/Fatal"| M_PIPE["Write to pipe"]
M_TIMER --> M_FLUSH["Flush all entries"]
M_PIPE --> M_FLUSH
end
style T_FLUSH fill:#50b86c,color:#fff
style N_FLUSH fill:#50b86c,color:#fff
style M_FLUSH fill:#50b86c,color:#fff
| Mode | Flush Trigger | Latency | Overhead | Best For |
|---|---|---|---|---|
| Timer | Periodic timer (default 100ms) | Up to flush_interval_ms | Lowest (no per-message syscall) | High-throughput logging |
| Notify | Pipe write per message | ~Immediate | Highest (1 write() per message) | Low-latency debugging |
| Mixed | Timer + pipe for Error/Fatal | Low for errors, batched for info | Moderate | Production applications |
Log Entry Lifecycle
sequenceDiagram
participant App as Application Thread
participant Pool as Entry Freelist
participant Queue as MPSC Queue
participant L as Event Loop Thread
participant File as Log File
App->>Pool: entry_alloc()
Pool-->>App: "xLogEntry_ (recycled or malloc'd)"
App->>App: "snprintf(entry->buf, timestamp + level + message)"
App->>Queue: xMpscPush(entry)
Note over App: "Optional: write(pipe_wfd, 1) for Notify/Mixed"
L->>Queue: "xMpscPop() (timer or pipe callback)"
Queue-->>L: xLogEntry_
L->>File: "fwrite(entry->buf)"
L->>Pool: entry_free(entry)
L->>File: fflush()
Log Entry Structure
struct xLogEntry_ {
xMpsc node; // MPSC queue node
xLogLevel level; // Severity level
int len; // Formatted message length
char buf[XLOG_ENTRY_BUF_SIZE]; // Formatted message (512 bytes)
struct xLogEntry_ *free_next; // Freelist link
};
Lock-Free Entry Freelist
The freelist uses a Treiber stack with atomic CAS:
- Alloc: Pop from freelist head (CAS loop). Fallback to
malloc()if empty. - Free: Push to freelist head (CAS loop). If count exceeds
XLOG_FREELIST_SIZE, callfree()instead.
The count check is intentionally racy (soft cap) to keep the fast path lean.
File Rotation
When written >= max_size and max_files > 1:
- Delete
path.{max_files-1}(oldest) - Cascade rename:
path.{i-1}→path.{i}for i = max_files-1 down to 2 - Rename
path→path.1 - Reopen
pathin append mode
app.log → app.log.1
app.log.1 → app.log.2
app.log.2 → app.log.3
app.log.3 → (deleted if max_files=4)
Synchronous Flush
xLoggerFlush() writes a byte to a dedicated flush-request pipe, triggering logger_flush_req_cb on the event loop thread. The caller then busy-waits (polling xMpscEmpty() every 1ms, up to 1 second) until the queue is drained.
Log Format
2025-04-04 16:30:00.123 INFO Application started
2025-04-04 16:30:00.456 WARN Low memory: 1024 bytes remaining
2025-04-04 16:30:01.789 ERROR Connection refused
Format: YYYY-MM-DD HH:MM:SS.mmm LEVEL message\n
API Reference
Types
| Type | Description |
|---|---|
xLogger | Opaque handle to an async logger |
xLogLevel | Enum: Debug, Info, Warn, Error, Fatal |
xLogMode | Enum: Timer, Notify, Mixed |
xLoggerConf | Configuration struct for creating a logger |
xLoggerConf Fields
| Field | Type | Default | Description |
|---|---|---|---|
loop | xEventLoop | (required) | Event loop for timer/pipe callbacks |
path | const char * | NULL (stderr) | Log file path |
mode | xLogMode | Timer | Operating mode |
level | xLogLevel | Info | Minimum log level |
max_size | size_t | 0 (no rotation) | Max file size before rotation |
max_files | int | 0 (no rotation) | Total files to keep (including current) |
flush_interval_ms | uint64_t | 100 | Timer/Mixed flush interval |
Functions
| Function | Signature | Description | Thread Safety |
|---|---|---|---|
xLoggerCreate | xLogger xLoggerCreate(xLoggerConf conf) | Create a logger. | Not thread-safe |
xLoggerDestroy | void xLoggerDestroy(xLogger logger) | Flush remaining entries and destroy. | Not thread-safe |
xLoggerLog | void xLoggerLog(xLogger logger, xLogLevel level, const char *fmt, ...) | Write a log entry. Fatal is synchronous + abort. | Thread-safe |
xLoggerFlush | void xLoggerFlush(xLogger logger) | Synchronously flush all pending entries. | Thread-safe |
xLoggerEnter | void xLoggerEnter(xLogger logger) | Set as thread-local logger + bridge xbase log. | Thread-local |
xLoggerLeave | void xLoggerLeave(void) | Clear thread-local logger. | Thread-local |
xLoggerCurrent | xLogger xLoggerCurrent(void) | Get current thread's logger. | Thread-local |
Convenience Macros
Using thread-local logger (set via xLoggerEnter):
| Macro | Expands To |
|---|---|
XLOG_DEBUG(fmt, ...) | xLoggerLog(xLoggerCurrent(), xLogLevel_Debug, fmt, ...) |
XLOG_INFO(fmt, ...) | xLoggerLog(xLoggerCurrent(), xLogLevel_Info, fmt, ...) |
XLOG_WARN(fmt, ...) | xLoggerLog(xLoggerCurrent(), xLogLevel_Warn, fmt, ...) |
XLOG_ERROR(fmt, ...) | xLoggerLog(xLoggerCurrent(), xLogLevel_Error, fmt, ...) |
XLOG_FATAL(fmt, ...) | xLoggerLog(xLoggerCurrent(), xLogLevel_Fatal, fmt, ...) |
Explicit logger variants: XLOG_DEBUG_L(logger, fmt, ...), etc.
Usage Examples
Basic File Logging
#include <x/base/event.h>
#include <x/log/logger.h>
int main(void) {
xEventLoop loop = xEventLoopCreate();
xLoggerConf conf = {
.loop = loop,
.path = "app.log",
.mode = xLogMode_Timer,
.level = xLogLevel_Info,
};
xLogger logger = xLoggerCreate(conf);
xLoggerEnter(logger);
XLOG_INFO("Server started on port %d", 8080);
XLOG_DEBUG("This is filtered out (level < Info)");
XLOG_WARN("Connection pool at %d%% capacity", 85);
xEventLoopRun(loop);
xLoggerLeave();
xLoggerDestroy(logger);
xEventLoopDestroy(loop);
return 0;
}
File Rotation Example
xLoggerConf conf = {
.loop = loop,
.path = "/var/log/myapp.log",
.mode = xLogMode_Mixed,
.level = xLogLevel_Info,
.max_size = 50 * 1024 * 1024, // 50MB per file
.max_files = 10, // Keep 10 files (500MB total)
};
Multi-Threaded Logging
#include <pthread.h>
#include <x/log/logger.h>
static xLogger g_logger;
static void *worker(void *arg) {
int id = *(int *)arg;
xLoggerEnter(g_logger); // Each thread must enter
for (int i = 0; i < 1000; i++) {
XLOG_INFO("Worker %d: iteration %d", id, i);
}
xLoggerLeave();
return NULL;
}
// In main():
// g_logger = xLoggerCreate(conf);
// pthread_create(&threads[i], NULL, worker, &ids[i]);
Synchronous Flush Before Exit
void graceful_shutdown(xLogger logger) {
XLOG_INFO("Shutting down...");
xLoggerFlush(logger); // Block until all entries are written
xLoggerDestroy(logger);
}
Use Cases
-
Application Logging — Primary use case: structured, async logging for server applications with file rotation and level filtering.
-
moo Internal Error Capture — Via
xLoggerEnter(), all moo internal errors (fromxLog()) are automatically routed through the async logger. -
Debug Logging — Use
xLogMode_Notifyduring development for immediate log output without timer delay.
Best Practices
- Call
xLoggerEnter()on every thread that usesXLOG_*()macros. Each thread needs its own thread-local context. - Use Mixed mode for production. It provides the best balance: batched writes for normal messages, immediate notification for errors.
- Set appropriate rotation limits. Without rotation (
max_size = 0), log files grow unbounded. - Call
xLoggerFlush()before shutdown to ensure all pending messages are written. - Don't log in tight loops at Debug level without checking the level first. While the level filter is cheap, formatting still costs CPU.
- Fatal messages are synchronous.
XLOG_FATAL()writes directly and callsabort(). Don't rely on async delivery for fatal messages.
Comparison with Other Libraries
| Feature | xlog logger.h | spdlog | zlog | log4c |
|---|---|---|---|---|
| Language | C99 | C++11 | C | C |
| Async Model | MPSC queue + event loop | Dedicated thread + queue | Dedicated thread | Synchronous |
| Modes | Timer / Notify / Mixed | Async (thread pool) | Async (thread) | Sync only |
| Lock-Free | Yes (MPSC + Treiber stack) | Yes (MPMC queue) | No (mutex) | No (mutex) |
| Event Loop | Integrated (xEventLoop) | None (own thread) | None (own thread) | None |
| File Rotation | Size-based (cascade rename) | Size-based | Size/time-based | Size-based |
| Format | printf-style | fmt-style / printf | printf-style | printf-style |
| Thread-Local Context | Yes (xLoggerEnter) | No | Yes (MDC) | Yes (NDC) |
| Fatal Handling | Sync write + abort | Flush + abort | Configurable | Configurable |
Key Differentiator: xlog is unique in integrating with an event loop rather than spawning a dedicated logging thread. This means the same thread that handles network I/O also handles log flushing, reducing context switches and thread count. The three-mode design (Timer/Notify/Mixed) gives fine-grained control over the latency/throughput trade-off that most logging libraries don't offer.
xjs — JavaScript Scripting Engine
Introduction
xjs is moo's embeddable JavaScript engine. It runs modern ECMAScript (ES2020+) in-process, is implemented on top of QuickJS-ng, and exposes a C API that mirrors Apple's JavaScriptCore C API one-to-one (every JS/kJS/OpaqueJS prefix becomes xJS/kXJS/OpaqueXJS).
The mirror is deliberate — it keeps the public surface stable even if the engine backend is swapped — and it makes the API immediately familiar to anyone who has embedded JSC on macOS/iOS.
Design Philosophy
-
JSC-Shaped Public API — Every opaque handle, constant and function in
js.hhas a direct JSC counterpart. Callers who know JSC already know xjs; code originally written against JSC usually ports with a mechanicalJS→xJSrename. -
Backend Replaceable — QuickJS types (
JSValue,JSRuntime,JSContext, …) never leak throughjs.h. All QuickJS-specific plumbing lives in.cfiles andjs_private.h. Swapping to another engine only requires reimplementing those translation units. -
Host-Driven Async — xjs intentionally does not drive an event loop. The host is responsible for pumping pending microtasks (Promise reactions,
async/awaitcontinuations,queueMicrotaskjobs) viaxJSContextDrainPendingJobs()at appropriate yield points. Synchronous Promise waiting is provided byxJSAwaitPromise(). -
Explicit Value Lifetimes — Every
xJSValueRef/xJSObjectRefreturned by the API is reference-counted. The host balances its references withxJSValueUnprotect(); there is no "stack scope" to release values for you. This is a deliberate deviation from JSC's Protect/Unprotect-only model and is documented in detail in value.md. -
No Native Module Registration (yet) — ES modules can be loaded from host-supplied source strings via a loader callback, but xjs does not expose an API for registering a
JSModuleDefbacked by C callbacks. The recommended pattern is the "global hook + JS facade" idiom; seeexamples/xjs_native_module.cand module.md.
Architecture
graph TD
subgraph "Public API (js.h)"
CTX["Context Group / Global Context"]
VAL["Values & Objects"]
STR["Strings (UTF-16)"]
CLS["Classes (native wrappers)"]
EVAL["Eval / Drain / GC"]
MOD["ES Modules + Loader"]
end
subgraph "Internal (js_private.h)"
SLOT["Slot Arena<br/>(xJSValueRef pool)"]
TRAMP["Class/Function<br/>Trampolines"]
XCODE["UTF-8 ⇌ UTF-16<br/>Transcoder"]
end
subgraph "Backend"
QJS["QuickJS-ng<br/>JSRuntime / JSContext / JSValue"]
end
CTX --> SLOT
VAL --> SLOT
CLS --> TRAMP
MOD --> TRAMP
EVAL --> SLOT
STR --> XCODE
SLOT --> QJS
TRAMP --> QJS
XCODE --> QJS
style SLOT fill:#f5a623,color:#fff
style QJS fill:#50b86c,color:#fff
Sub-Module Overview
| File | Description | Doc |
|---|---|---|
js.h (Context group section) | Runtime / global context lifecycle, module loader install | context.md |
js.h (Value section) | Type queries, builders, conversions, JSON bridge, Protect/Unprotect | value.md |
js.h (Object section) | Object/Array/Date/Error/RegExp/Promise/Function construction, property access, call-as-function/constructor | object.md |
js.h (Class registration section) | xJSClassDefinition, xJSClassCreate, native finalizer contract | class.md |
js.h (String section) | UTF-16 storage, UTF-8 transcoding helpers, ref counting | string.md |
js.h (Script evaluation section) | xJSEvaluateScript, xJSCheckScriptSyntax, job draining, GC | eval.md |
js.h (ES modules section) | xJSEvaluateModule, xJSAwaitPromise, module loader callback | module.md |
Quick Start
The smallest useful program — evaluate a script and print the result.
#include <stdio.h>
#include <stdlib.h>
#include <x/js/js.h>
int main(void) {
xJSGlobalContextRef ctx = xJSGlobalContextCreate(NULL);
xJSStringRef src = xJSStringCreateWithUTF8CString("1 + 2 * 3");
xJSValueRef exc = NULL;
xJSValueRef r = xJSEvaluateScript(ctx, src, NULL, NULL, 0, &exc);
xJSStringRelease(src);
if (!r) {
xJSStringRef m = xJSValueToStringCopy(ctx, exc, NULL);
char buf[256];
xJSStringGetUTF8CString(m, buf, sizeof(buf));
fprintf(stderr, "error: %s\n", buf);
xJSStringRelease(m);
xJSValueUnprotect(ctx, exc);
xJSGlobalContextRelease(ctx);
return 1;
}
printf("= %g\n", xJSValueToNumber(ctx, r, NULL)); // = 7
xJSValueUnprotect(ctx, r);
xJSGlobalContextRelease(ctx);
return 0;
}
A fuller walk-through — ES modules, native hooks, and synchronous Promise await — lives in examples/xjs_native_module.c.
Relationship with Other Modules
- xbase — xjs depends on
xbase/base.hforXCAPI,XDEF_STRUCT, and error-code conventions. No event loop or IO integration is mandated: xjs stays runtime-agnostic. - xagent (planned) — xjs is the intended substrate for letting agent/tool logic be authored in JavaScript instead of C; see the xagent roadmap.
Backend Notes
- The runtime backend is QuickJS-ng. It is a
PRIVATECMake dependency ofxjs— nothing injs.hreferences a QuickJS type, so downstream targets never transitively seequickjs.h. - ES2020 features supported by QuickJS-ng (classes, async/await, optional chaining, BigInt, top-level
awaitin modules, …) are available to user scripts. - Thread-safety follows QuickJS-ng: a
xJSContextGroupRef(runtime) is single-threaded. Multiple runtimes can exist in the same process, but values and contexts from different groups must never be mixed.
xjs — Context & Runtime Lifecycle
Introduction
Every JavaScript operation in xjs happens inside a global context, which in turn lives inside a context group. The group owns the JS runtime (GC heap, class table, module loader); the context owns the global object and the "value slot" pool used to hand xJSValueRef handles back to host code.
Both handles are reference-counted and mirror JavaScriptCore's JSContextGroupRef / JSGlobalContextRef semantics.
Object Model
xJSContextGroupRef (≈ JSRuntime)
│ - GC heap
│ - shared class registry
│ - module loader trampoline
│
└── xJSGlobalContextRef (≈ JSContext, 1..N per group)
│ - global object
│ - slot pool for xJSValueRef
│ - user module-load callback
│
└── xJSValueRef / xJSObjectRef / …
Most applications only need one group and one context; that is what xJSGlobalContextCreate(NULL) builds for you.
Creating and Destroying a Context
One-liner (single context)
xJSGlobalContextRef ctx = xJSGlobalContextCreate(NULL);
// …
xJSGlobalContextRelease(ctx);
xJSGlobalContextCreate allocates a fresh group internally, creates one context in it, and transfers group ownership to the context — so xJSGlobalContextRelease is the only teardown you need.
Multiple contexts sharing a heap
xJSContextGroupRef group = xJSContextGroupCreate();
xJSGlobalContextRef a = xJSGlobalContextCreateInGroup(group, NULL);
xJSGlobalContextRef b = xJSGlobalContextCreateInGroup(group, NULL);
// …
xJSGlobalContextRelease(a);
xJSGlobalContextRelease(b);
xJSContextGroupRelease(group);
Contexts in the same group share one GC heap — values can be moved between them cheaply — but must be driven from the same OS thread. Different groups are fully independent and may run on different threads.
Naming a context (for stack traces)
xJSStringRef name = xJSStringCreateWithUTF8CString("worker-42");
xJSGlobalContextSetName(ctx, name);
xJSStringRelease(name);
The name shows up in QuickJS error messages and makes multi-context deployments easier to debug.
Accessing the Global Object
xJSObjectRef g = xJSContextGetGlobalObject(ctx);
// install globals on `g` via xJSObjectSetProperty
xJSValueUnprotect(ctx, (xJSValueRef)g); // release our reference
xJSContextGetGlobalObject returns a new reference (as do all Get* helpers in xjs; see value.md for the lifetime rules).
Pumping Microtasks
QuickJS does not execute Promise reactions automatically between host invocations. Whenever host code does something that might settle a Promise (resolve a deferred, return from a native callback, complete an IO operation), call:
xJSValueRef exc = NULL;
int ran = xJSContextDrainPendingJobs(ctx, &exc);
if (ran < 0 && exc) {
// first job to throw; subsequent jobs still queued
}
The helper keeps executing pending jobs until the queue is empty or a job throws. xJSContextHasPendingJobs() is a cheap peek when you want to batch-drain only when needed.
For the common "evaluate a module, block until done" flow, use xJSAwaitPromise() instead — it drains on your behalf until a specific Promise settles.
Installing a Module Loader
xJSContextSetModuleLoader(ctx, my_loader, my_opaque);
See module.md for the loader contract (it is always installed internally; passing NULL just reverts to the built-in ReferenceError behaviour for every import).
API Surface
Context group
xJSContextGroupRef xJSContextGroupCreate(void);
xJSContextGroupRef xJSContextGroupRetain(xJSContextGroupRef group);
void xJSContextGroupRelease(xJSContextGroupRef group);
Global context
xJSGlobalContextRef xJSGlobalContextCreate(xJSClassRef globalObjectClass);
xJSGlobalContextRef xJSGlobalContextCreateInGroup(xJSContextGroupRef group,
xJSClassRef globalObjectClass);
xJSGlobalContextRef xJSGlobalContextRetain(xJSGlobalContextRef ctx);
void xJSGlobalContextRelease(xJSGlobalContextRef ctx);
xJSStringRef xJSGlobalContextCopyName(xJSGlobalContextRef ctx);
void xJSGlobalContextSetName(xJSGlobalContextRef ctx, xJSStringRef name);
xJSObjectRef xJSContextGetGlobalObject(xJSContextRef ctx);
xJSContextGroupRef xJSContextGetGroup(xJSContextRef ctx);
xJSGlobalContextRef xJSContextGetGlobalContext(xJSContextRef ctx);
Microtask pump
int xJSContextDrainPendingJobs(xJSContextRef ctx, xJSValueRef *exception);
bool xJSContextHasPendingJobs(xJSContextRef ctx);
Module loader
typedef xJSStringRef (*xJSModuleLoadCallback)(xJSContextRef ctx,
const char *normalizedName,
void *opaque);
void xJSContextSetModuleLoader(xJSGlobalContextRef ctx,
xJSModuleLoadCallback load, void *opaque);
Caveats
xJSGlobalContextCreate(xJSClassRef globalObjectClass)currently ignoresglobalObjectClass: customising the global object type is on the roadmap but not yet wired through. PassNULL.- Contexts are not thread-safe — every entry into
ctx(includingxJSValueUnprotect) must come from the thread that owns the group.
xjs — Values
Introduction
An xJSValueRef is an opaque handle to a JavaScript value (primitive or object). Every value reachable from host code lives in a per-context slot pool that holds the underlying QuickJS reference; the slot itself is reference-counted.
This page covers the type system, value construction, conversion, and — most importantly — the lifetime rules that are the single biggest deviation from JavaScriptCore's C API.
Lifetime Rules
Important — read this first.
In JSC, JSValueRef is a thin wrapper around a conservatively-scanned JS heap pointer: values live at least as long as the VM stack frame that created them, and JSValueProtect/JSValueUnprotect pairs only matter if you need to stash a value across a return into JS.
In xjs, every xJSValueRef handed back from the API carries one reference in a slot pool, and the caller is responsible for releasing it via xJSValueUnprotect(). Forgetting to unprotect leaks both the slot and the underlying JS value.
The rules:
| Case | Who owns the ref | Who must release |
|---|---|---|
Return value of any xJSValueMake*, xJSObjectMake*, xJSValue*Copy, xJSObjectGetProperty*, xJSContextGetGlobalObject, xJSObjectCallAsFunction, xJSEvaluateScript, xJSEvaluateModule, xJSAwaitPromise, … | caller | caller — xJSValueUnprotect |
xJSValueRef handed in as a parameter (value, arguments[], thisObject, …) | caller | caller (callee borrows) |
*exception out-param, when populated | caller | caller — xJSValueUnprotect |
xJSValueRef received by a native callback as arguments[i] | VM | do not release (the VM balances) |
If the same handle is needed twice (e.g. stash it in a C struct and also return it), use xJSValueProtect to bump the refcount, and release once for each bump.
Relationship to GC
While a slot is alive it keeps a QuickJS reference on the underlying JSValue, which roots it against the garbage collector. xJSGarbageCollect(ctx) forces a full GC pass but only reclaims values that no slot (and no live JS reference) still holds.
Behavioural consequence: xJSValueUnprotect on an un-protected value
Because every public value is born with refcount == 1, plain xJSValueUnprotect(ctx, v) is the standard release call — it matches JSC's naming but is not optional in xjs. Calling it twice on the same handle without a matching xJSValueProtect is a double-free.
Type System
typedef enum {
kXJSTypeUndefined = 0,
kXJSTypeNull = 1,
kXJSTypeBoolean = 2,
kXJSTypeNumber = 3,
kXJSTypeString = 4,
kXJSTypeObject = 5,
kXJSTypeSymbol = 6,
} xJSType;
Primitive queries
xJSType xJSValueGetType(xJSContextRef ctx, xJSValueRef value);
bool xJSValueIsUndefined(xJSContextRef, xJSValueRef);
bool xJSValueIsNull (xJSContextRef, xJSValueRef);
bool xJSValueIsBoolean (xJSContextRef, xJSValueRef);
bool xJSValueIsNumber (xJSContextRef, xJSValueRef);
bool xJSValueIsString (xJSContextRef, xJSValueRef);
bool xJSValueIsSymbol (xJSContextRef, xJSValueRef);
bool xJSValueIsObject (xJSContextRef, xJSValueRef);
bool xJSValueIsArray (xJSContextRef, xJSValueRef);
bool xJSValueIsDate (xJSContextRef, xJSValueRef);
Class / constructor queries
bool xJSValueIsObjectOfClass(xJSContextRef ctx, xJSValueRef v, xJSClassRef c);
bool xJSValueIsInstanceOfConstructor(xJSContextRef ctx, xJSValueRef v,
xJSObjectRef constructor,
xJSValueRef *exception);
Equality
bool xJSValueIsEqual (xJSContextRef, xJSValueRef a, xJSValueRef b,
xJSValueRef *exception); // ==
bool xJSValueIsStrictEqual(xJSContextRef, xJSValueRef a, xJSValueRef b); // ===
xJSValueIsEqual can trigger user-defined coercion (valueOf/toString) and therefore takes an exception out-param. xJSValueIsStrictEqual is side-effect-free.
Value Construction
xJSValueRef xJSValueMakeUndefined(xJSContextRef ctx);
xJSValueRef xJSValueMakeNull (xJSContextRef ctx);
xJSValueRef xJSValueMakeBoolean (xJSContextRef, bool);
xJSValueRef xJSValueMakeNumber (xJSContextRef, double);
xJSValueRef xJSValueMakeString (xJSContextRef, xJSStringRef);
xJSValueRef xJSValueMakeSymbol (xJSContextRef, xJSStringRef description);
All builders return a fresh owning reference; release with xJSValueUnprotect.
JSON bridge
xJSValueRef xJSValueMakeFromJSONString(xJSContextRef ctx, xJSStringRef json);
xJSStringRef xJSValueCreateJSONString (xJSContextRef ctx, xJSValueRef v,
unsigned indent, xJSValueRef *exc);
xJSValueMakeFromJSONString returns NULL on parse error (no exception is raised — it is a host-side failure). xJSValueCreateJSONString returns NULL and sets *exception if the value contains cycles or throws from a toJSON.
Conversions
bool xJSValueToBoolean (xJSContextRef ctx, xJSValueRef);
double xJSValueToNumber (xJSContextRef ctx, xJSValueRef, xJSValueRef *exc);
xJSStringRef xJSValueToStringCopy(xJSContextRef ctx, xJSValueRef, xJSValueRef *exc);
xJSObjectRef xJSValueToObject (xJSContextRef ctx, xJSValueRef, xJSValueRef *exc);
The "Copy" in xJSValueToStringCopy means caller owns the returned xJSStringRef and must balance it with xJSStringRelease.
Conversions that invoke user code (toString, valueOf) can throw; non-throwing conversions (ToBoolean) do not take an exception parameter.
Reference-count Helpers
void xJSValueProtect (xJSContextRef ctx, xJSValueRef value); // +1
void xJSValueUnprotect(xJSContextRef ctx, xJSValueRef value); // -1 (free at 0)
See the Lifetime Rules section above. In xjs these are the direct control of the slot refcount, not the "additional root" semantics JSC uses.
Worked Examples
Round-trip through JSON
xJSStringRef s = xJSStringCreateWithUTF8CString("{\"x\":1,\"y\":[2,3]}");
xJSValueRef v = xJSValueMakeFromJSONString(ctx, s);
xJSStringRelease(s);
// … inspect `v` via xJSObjectGetProperty etc …
xJSValueRef exc = NULL;
xJSStringRef j = xJSValueCreateJSONString(ctx, v, 2, &exc);
xJSValueUnprotect(ctx, v);
if (j) { /* pretty-printed JSON in `j` */ xJSStringRelease(j); }
Safe number read
xJSValueRef exc = NULL;
double n = xJSValueToNumber(ctx, v, &exc);
if (exc) {
// `v`'s .valueOf threw; print exc and bail
xJSValueUnprotect(ctx, exc);
}
Caveats
xJSValueIsArrayreturns true for genuine JSArrayobjects (not for array-like objects with a numericlength). Use property inspection if you need the looser test.xJSValueIsDateonly matchesDateinstances created bynew Date(...); raw timestamps (numbers) return false.- Symbols produced via
xJSValueMakeSymbol(ctx, description)useSymbol(description)semantics (non-interned). UsexJSEvaluateScript(ctx, "Symbol.for('k')", …)if you need the global registry.
xjs — Objects, Functions & Promises
Introduction
xJSObjectRef is a specialisation of xJSValueRef restricted to the JavaScript Object type — arrays, dates, errors, regexps, functions, constructors, promises, and native class instances all show up as xJSObjectRef. Every xJSObjectRef is binary-compatible with xJSValueRef and follows the same value lifetime rules.
Creating Objects
Generic object
xJSObjectRef xJSObjectMake(xJSContextRef ctx, xJSClassRef cls, void *data);
cls == NULL produces a plain {}. Pass a class created by xJSClassCreate to wrap a C struct — data is stored in the object's private slot and retrieved via xJSObjectGetPrivate.
Host-callable function
xJSObjectRef xJSObjectMakeFunctionWithCallback(
xJSContextRef ctx, xJSStringRef name,
xJSObjectCallAsFunctionCallback cb);
The returned object is indistinguishable from a JS function (typeof fn === "function", callable from user code).
static xJSValueRef add(xJSContextRef ctx, xJSObjectRef fn, xJSObjectRef thiz,
size_t argc, const xJSValueRef argv[],
xJSValueRef *exc) {
(void)fn; (void)thiz;
double a = argc > 0 ? xJSValueToNumber(ctx, argv[0], exc) : 0;
double b = argc > 1 ? xJSValueToNumber(ctx, argv[1], exc) : 0;
return xJSValueMakeNumber(ctx, a + b);
}
xJSStringRef name = xJSStringCreateWithUTF8CString("add");
xJSObjectRef fn = xJSObjectMakeFunctionWithCallback(ctx, name, add);
xJSStringRelease(name);
Constructor for a native class
xJSObjectRef xJSObjectMakeConstructor(
xJSContextRef ctx, xJSClassRef cls,
xJSObjectCallAsConstructorCallback ctor);
Registers cls against the context's runtime on first use, then returns a function that — when invoked with new — calls ctor. See class.md for the full flow.
Compile-at-runtime function
xJSObjectRef xJSObjectMakeFunction(
xJSContextRef ctx, xJSStringRef name,
unsigned parameterCount, const xJSStringRef parameterNames[],
xJSStringRef body, xJSStringRef sourceURL, int startingLineNumber,
xJSValueRef *exception);
Equivalent to new Function(...parameterNames, body). Compile errors surface via *exception and a NULL return.
Built-in specialisations
xJSObjectRef xJSObjectMakeArray (xJSContextRef, size_t argc, const xJSValueRef argv[], xJSValueRef *exc);
xJSObjectRef xJSObjectMakeDate (xJSContextRef, size_t argc, const xJSValueRef argv[], xJSValueRef *exc);
xJSObjectRef xJSObjectMakeError (xJSContextRef, size_t argc, const xJSValueRef argv[], xJSValueRef *exc);
xJSObjectRef xJSObjectMakeRegExp(xJSContextRef, size_t argc, const xJSValueRef argv[], xJSValueRef *exc);
Each is a thin shortcut for new Array(...) / new Date(...) / etc.
Deferred promise (for async host work)
xJSObjectRef xJSObjectMakeDeferredPromise(
xJSContextRef ctx,
xJSObjectRef *resolve, xJSObjectRef *reject,
xJSValueRef *exception);
Returns a pending Promise plus its resolve/reject functions. The typical flow:
- Kick off async work in host land; capture
ctx,resolve,reject. - Return the promise to JavaScript.
- When the work completes, call
xJSObjectCallAsFunction(ctx, resolve, NULL, 1, &result, &exc);(orreject). - Call
xJSContextDrainPendingJobs(ctx, …)so the.thenreactions run. - Release the three
xJSObjectRefhandles once you no longer need them.
Accessing Object Properties
By string key
bool xJSObjectHasProperty (xJSContextRef, xJSObjectRef, xJSStringRef);
xJSValueRef xJSObjectGetProperty (xJSContextRef, xJSObjectRef, xJSStringRef, xJSValueRef *exc);
void xJSObjectSetProperty (xJSContextRef, xJSObjectRef, xJSStringRef,
xJSValueRef value,
xJSPropertyAttributes attrs,
xJSValueRef *exc);
bool xJSObjectDeleteProperty (xJSContextRef, xJSObjectRef, xJSStringRef, xJSValueRef *exc);
Attribute flags (bit-ORed into attrs):
kXJSPropertyAttributeNone = 0
kXJSPropertyAttributeReadOnly = 1 << 1
kXJSPropertyAttributeDontEnum = 1 << 2
kXJSPropertyAttributeDontDelete = 1 << 3
By integer index
xJSValueRef xJSObjectGetPropertyAtIndex(xJSContextRef, xJSObjectRef,
unsigned idx, xJSValueRef *exc);
void xJSObjectSetPropertyAtIndex(xJSContextRef, xJSObjectRef,
unsigned idx, xJSValueRef value,
xJSValueRef *exc);
Faster than the string variant for arrays and typed arrays.
Enumeration
xJSPropertyNameArrayRef names = xJSObjectCopyPropertyNames(ctx, obj);
size_t n = xJSPropertyNameArrayGetCount(names);
for (size_t i = 0; i < n; ++i) {
xJSStringRef k = xJSPropertyNameArrayGetNameAtIndex(names, i);
// … inspect k …
}
xJSPropertyNameArrayRelease(names);
Only own, enumerable, string-keyed properties are listed (matching Object.keys). Symbol keys require lowering into JS (Reflect.ownKeys(...)).
Prototype
xJSValueRef xJSObjectGetPrototype(xJSContextRef, xJSObjectRef);
void xJSObjectSetPrototype(xJSContextRef, xJSObjectRef, xJSValueRef proto);
Pass xJSValueMakeNull(ctx) to detach the prototype.
Calling Functions and Constructors
bool xJSObjectIsFunction (xJSContextRef, xJSObjectRef);
xJSValueRef xJSObjectCallAsFunction(xJSContextRef, xJSObjectRef fn,
xJSObjectRef thisObj,
size_t argc, const xJSValueRef argv[],
xJSValueRef *exception);
bool xJSObjectIsConstructor (xJSContextRef, xJSObjectRef);
xJSObjectRef xJSObjectCallAsConstructor(xJSContextRef, xJSObjectRef ctor,
size_t argc, const xJSValueRef argv[],
xJSValueRef *exception);
Passing thisObj == NULL in CallAsFunction uses globalThis as this, matching JSC.
Private Data
For instances of a class created via xJSClassCreate, an opaque void * slot is available:
void *xJSObjectGetPrivate(xJSObjectRef obj);
bool xJSObjectSetPrivate(xJSObjectRef obj, void *data);
Set returns false when called on a plain object (no class → no private slot). The private pointer is handed back from the finalize callback so you can free it; xjs does not take ownership of it.
Worked Example — Call a JS function from C
// const x = 5; add(x, 7) → 12
xJSStringRef nameK = xJSStringCreateWithUTF8CString("add");
xJSObjectRef g = xJSContextGetGlobalObject(ctx);
xJSValueRef fn = xJSObjectGetProperty(ctx, g, nameK, NULL);
xJSValueUnprotect(ctx, (xJSValueRef)g);
xJSStringRelease(nameK);
xJSValueRef args[2] = {
xJSValueMakeNumber(ctx, 5),
xJSValueMakeNumber(ctx, 7),
};
xJSValueRef exc = NULL;
xJSValueRef r = xJSObjectCallAsFunction(ctx, (xJSObjectRef)fn, NULL,
2, args, &exc);
for (int i = 0; i < 2; ++i) xJSValueUnprotect(ctx, args[i]);
xJSValueUnprotect(ctx, fn);
if (!r) { /* exc populated */ }
else {
printf("add(5,7) = %g\n", xJSValueToNumber(ctx, r, NULL));
xJSValueUnprotect(ctx, r);
}
Caveats
- Native callbacks are invoked synchronously from JS. Long-running work must be offloaded to a host thread and surfaced via
xJSObjectMakeDeferredPromiseso JS stays responsive. - Returning one of the incoming
argv[i](orthisObject/function) from a callback is supported — xjs detects the aliasing and does not double-release. Returning a freshly built value is also fine; the wrapper extracts the underlyingJSValueand releases the slot for you. xJSPropertyNameArrayRefowns a retained copy of each name; the strings returned byGetNameAtIndexare alive for as long as the array is. Do notxJSStringReleasethem directly.
xjs — Classes & Native Wrappers
Introduction
A class in xjs is a recipe for wrapping a C struct as a JavaScript object — the same role JSClassRef plays in JavaScriptCore. A class ties together:
- a class name (shows up in
Object.prototype.toString), - a finalizer that runs when the wrapped instance is garbage-collected,
- optional property callbacks (
hasProperty/getProperty/setProperty/deleteProperty/getPropertyNames) for exotic access patterns, - optional call / construct / hasInstance / convertToType hooks,
- static value and function tables installed on the prototype,
- an initializer invoked when new instances are created.
The Definition Struct
XDEF_STRUCT(xJSClassDefinition) {
int version; /* must be 0 */
xJSClassAttributes attributes; /* bitmask */
const char *className;
xJSClassRef parentClass;
const xJSStaticValue *staticValues; /* NULL-terminated */
const xJSStaticFunction *staticFunctions; /* NULL-terminated */
xJSObjectInitializeCallback initialize;
xJSObjectFinalizeCallback finalize;
xJSObjectHasPropertyCallback hasProperty;
xJSObjectGetPropertyCallback getProperty;
xJSObjectSetPropertyCallback setProperty;
xJSObjectDeletePropertyCallback deleteProperty;
xJSObjectGetPropertyNamesCallback getPropertyNames;
xJSObjectCallAsFunctionCallback callAsFunction;
xJSObjectCallAsConstructorCallback callAsConstructor;
xJSObjectHasInstanceCallback hasInstance;
xJSObjectConvertToTypeCallback convertToType;
};
Layout matches JSC's JSClassDefinition field-for-field. A zero-initialised helper is provided:
xJSClassDefinition def = kXJSClassDefinitionEmpty;
def.className = "Counter";
def.finalize = counter_finalize;
Lifecycle
xJSClassRef xJSClassCreate(const xJSClassDefinition *def);
xJSClassRef xJSClassRetain(xJSClassRef cls);
void xJSClassRelease(xJSClassRef cls);
xJSClassCreate is runtime-agnostic — it does not need an xJSContextRef. Callers typically build classes at module-init time and keep them in globals for the lifetime of the process. The first time an instance of the class is created or tested against (via xJSObjectMake, xJSObjectMakeConstructor, xJSValueIsObjectOfClass), xjs lazily registers the class against the context's runtime; subsequent uses on the same runtime are no-ops.
The same xJSClassRef can be shared across multiple runtimes in the same process — each runtime registers it once and allocates its own class-ID table.
Finalizer Contract
typedef void (*xJSObjectFinalizeCallback)(xJSObjectRef object);
Important constraints:
- Runs during GC, so the wrapped
xJSContextRefis not available — passingobjectto APIs that require a live context (anything that evaluates code, reads properties via scripted accessors, …) is undefined behaviour. - Safe operations:
xJSObjectGetPrivate(object)to retrieve thevoid *you stored atxJSObjectMaketime, so you can free it. - Finalizers may run in any order relative to other finalizers — do not rely on ordering between instances of different classes.
Full Example — a native Counter
typedef struct { long value; } Counter;
static void counter_finalize(xJSObjectRef obj) {
free(xJSObjectGetPrivate(obj));
}
static xJSValueRef counter_inc(xJSContextRef ctx, xJSObjectRef fn,
xJSObjectRef thiz, size_t argc,
const xJSValueRef argv[], xJSValueRef *exc) {
(void)fn; (void)argc; (void)argv; (void)exc;
Counter *c = (Counter *)xJSObjectGetPrivate(thiz);
c->value++;
return xJSValueMakeUndefined(ctx);
}
static xJSValueRef counter_get(xJSContextRef ctx, xJSObjectRef thiz,
xJSStringRef name, xJSValueRef *exc) {
(void)name; (void)exc;
Counter *c = (Counter *)xJSObjectGetPrivate(thiz);
return xJSValueMakeNumber(ctx, (double)c->value);
}
static xJSObjectRef counter_construct(xJSContextRef ctx, xJSObjectRef ctor,
size_t argc, const xJSValueRef argv[],
xJSValueRef *exc) {
(void)ctor; (void)argc; (void)argv; (void)exc;
Counter *c = calloc(1, sizeof(*c));
return xJSObjectMake(ctx, s_counter_class, c); // see below
}
static const xJSStaticFunction kFns[] = {
{ "inc", counter_inc, kXJSPropertyAttributeDontDelete },
{ NULL, NULL, 0 },
};
static const xJSStaticValue kVals[] = {
{ "value", counter_get, NULL, kXJSPropertyAttributeDontDelete | kXJSPropertyAttributeReadOnly },
{ NULL, NULL, NULL, 0 },
};
xJSClassRef s_counter_class;
void register_counter(xJSGlobalContextRef ctx) {
xJSClassDefinition def = kXJSClassDefinitionEmpty;
def.className = "Counter";
def.finalize = counter_finalize;
def.staticFunctions = kFns;
def.staticValues = kVals;
s_counter_class = xJSClassCreate(&def);
xJSObjectRef ctor = xJSObjectMakeConstructor(ctx, s_counter_class, counter_construct);
xJSStringRef name = xJSStringCreateWithUTF8CString("Counter");
xJSObjectRef g = xJSContextGetGlobalObject(ctx);
xJSObjectSetProperty(ctx, g, name, (xJSValueRef)ctor, 0, NULL);
xJSStringRelease(name);
xJSValueUnprotect(ctx, (xJSValueRef)g);
xJSValueUnprotect(ctx, (xJSValueRef)ctor);
}
Now JS code can do:
const c = new Counter();
c.inc(); c.inc(); c.inc();
console.log(c.value); // 3
Class Attributes
kXJSClassAttributeNone = 0
kXJSClassAttributeNoAutomaticPrototype = 1 << 1
NoAutomaticPrototype suppresses the auto-wired prototype chain — use it when parentClass is set and you need exact control over prototype linking.
Static Tables
xJSStaticValue
XDEF_STRUCT(xJSStaticValue) {
const char *name;
xJSObjectGetPropertyCallback getProperty;
xJSObjectSetPropertyCallback setProperty;
xJSPropertyAttributes attributes;
};
A NULL-terminated array installs one accessor per entry on the class prototype. Omit setProperty for a read-only property (pair it with kXJSPropertyAttributeReadOnly to keep the flag consistent).
xJSStaticFunction
XDEF_STRUCT(xJSStaticFunction) {
const char *name;
xJSObjectCallAsFunctionCallback callAsFunction;
xJSPropertyAttributes attributes;
};
Also NULL-terminated. Each entry becomes a prototype method.
Best Practices
- Build classes once, reuse forever.
xJSClassCreateis runtime-agnostic and the resultingxJSClassRefcan be shared across every context/group in the process. Stash it in astaticglobal at init time. - Keep static tables
static const. The class only shallow-copies the definition, so thestaticValues/staticFunctionsarrays and theclassNamestring must outlive the class.static constarrays satisfy this for free. - Free private data in
finalize, nowhere else. It is the only callback guaranteed to run exactly once per instance. Do not rely on explicit teardown from host code — the object may still be alive when the context is released. - Don't touch the context inside
finalize. The finalizer runs during GC with no live context; limit yourself toxJSObjectGetPrivate+free(or equivalent). - Prefer
xJSStaticFunction/xJSStaticValueover per-instance property installs. Static tables attach to the prototype once and cost nothing per instance; installing properties ininitializemultiplies memory and GC work by the instance count.
Caveats
xJSClassCreateonly makes a shallow copy of the definition —staticValues,staticFunctionsandclassNamepointers must stay alive for the class's lifetime (usestatic consttables as in the example).- The class holds no retain on
parentClass; you must keep it alive yourself. - Private data is a single
void *. For structured data, define a struct and store a pointer to it. xjs never touches the pointer other than to hand it back fromxJSObjectGetPrivate. hasInstanceandconvertToTypecallbacks are accepted in the definition for JSC parity but are not yet wired to QuickJS semantics. Avoid depending on them until the backend grows matching hooks.
xjs — Strings
Introduction
xJSStringRef is xjs's string type for API boundaries — it is not a JavaScript string value (use xJSValueMakeString for that), but rather the encoding-aware byte bag used by every helper that names a property, loads a module, reports an exception, etc.
Internally a string is a ref-counted UTF-16 buffer; UTF-8 transcoding happens on the way in and out.
Encoding & Layout
- Storage: UTF-16 code units (
uint16_t[]), allocated as a single block alongside the header for cache friendliness. The buffer is NUL-terminated so it can be passed to UTF-16-aware APIs directly. - UTF-8 input (
xJSStringCreateWithUTF8CString) is transcoded into UTF-16. - UTF-8 output (
xJSStringGetUTF8CString) transcodes back. The helper returns the number of bytes including the trailing NUL (matching JSC).
The UTF-16 storage is the canonical JS string shape (ES uses UTF-16 for .length and indexing), so keeping it native avoids re-transcoding on every property lookup.
Construction
xJSStringRef xJSStringCreateWithCharacters(const uint16_t *chars, size_t n);
xJSStringRef xJSStringCreateWithUTF8CString(const char *cstr);
Both allocate a fresh refcount-1 string. Passing NULL to xJSStringCreateWithUTF8CString yields a valid empty string (not NULL).
Ref Counting
xJSStringRef xJSStringRetain (xJSStringRef s);
void xJSStringRelease(xJSStringRef s);
Every constructor/copy returns a fresh reference that the caller must balance with exactly one xJSStringRelease. Strings handed to API sinks (xJSObjectSetProperty, xJSEvaluateModule, …) are borrowed — the callee does not take ownership.
Reading the Buffer
size_t xJSStringGetLength (xJSStringRef s);
const uint16_t *xJSStringGetCharactersPtr (xJSStringRef s);
size_t xJSStringGetMaximumUTF8CStringSize(xJSStringRef s);
size_t xJSStringGetUTF8CString (xJSStringRef s,
char *buffer, size_t bufferSize);
Typical "get as UTF-8 C string" pattern:
size_t cap = xJSStringGetMaximumUTF8CStringSize(s);
char *buf = malloc(cap);
size_t n = xJSStringGetUTF8CString(s, buf, cap);
// buf is NUL-terminated, n includes the NUL
The "Maximum" helper reports a safe upper bound (worst case: 3 bytes per code unit + NUL) — ideal as the malloc size. The actual number of bytes written is the n returned.
Equality
bool xJSStringIsEqual (xJSStringRef a, xJSStringRef b);
bool xJSStringIsEqualToUTF8CString (xJSStringRef a, const char *b);
Both are code-unit-exact comparisons (no normalisation). IsEqualToUTF8CString internally transcodes b for comparison.
Relationship with Values and Properties
xJSValueRef ↔ xJSStringRef: usexJSValueMakeString/xJSValueToStringCopy.- Property keys in
xJSObjectGetProperty/xJSObjectSetProperty/xJSObjectHasPropertyarexJSStringRef. Build them once, reuse freely. - Module identifiers and source URLs passed to
xJSEvaluateModule/xJSContextSetModuleLoaderarexJSStringRefon the way in; the loader callback receives a plain UTF-8const char *normalizedNamefor convenience.
Caveats
- xjs does not (yet) expose an API for inspecting UTF-8 byte length independently of the worst-case upper bound. If you need tight sizing, transcode once and measure.
xJSStringIsEqualToUTF8CStringallocates on every call (it builds a transient UTF-16 copy). For hot-path comparisons, cache the UTF-16 form withxJSStringCreateWithUTF8CStringup front.- There is no string slice, concat, or index-of API at the xjs layer — such operations belong in JS. If you need to manipulate strings in host code, transcode to UTF-8 once and use xbase's
xStringhelpers.
Worked Example — Calling with a UTF-8 property name
xJSStringRef k = xJSStringCreateWithUTF8CString("status");
xJSValueRef v = xJSObjectGetProperty(ctx, obj, k, NULL);
xJSStringRelease(k);
xJSStringRef vs = xJSValueToStringCopy(ctx, v, NULL);
xJSValueUnprotect(ctx, v);
size_t cap = xJSStringGetMaximumUTF8CStringSize(vs);
char *buf = malloc(cap);
xJSStringGetUTF8CString(vs, buf, cap);
printf("status = %s\n", buf);
free(buf);
xJSStringRelease(vs);
xjs — Script Evaluation
Introduction
xjs evaluates JavaScript in two flavours — classic scripts (global code, no import/export) and ES modules (covered in module.md). This page focuses on the script path plus the shared job/GC machinery.
Check Syntax Only
bool xJSCheckScriptSyntax(xJSContextRef ctx, xJSStringRef script,
xJSStringRef sourceURL,
int startingLineNumber,
xJSValueRef *exception);
Compiles script with JS_EVAL_FLAG_COMPILE_ONLY and throws the compiled byte-code away. Use this to validate user input (e.g. an in-app script editor) without running any code. On failure the compile error is reported through *exception and the function returns false.
Evaluate a Script
xJSValueRef xJSEvaluateScript(xJSContextRef ctx,
xJSStringRef script,
xJSObjectRef thisObject,
xJSStringRef sourceURL,
int startingLineNumber,
xJSValueRef *exception);
script— source code (UTF-16 internally, transcoded to UTF-8 for the compiler).thisObject— bindsthisat top level. PassNULLto useglobalThis(JSC-equivalent default).sourceURL— shows up in stack traces. PassNULLfor the default placeholder<xjs>.startingLineNumber— currently accepted but ignored by the QuickJS backend; keep it at0or1for future compatibility.- Returns a fresh
xJSValueRef(release withxJSValueUnprotect) orNULLon throw (*exceptionis populated).
Example
xJSStringRef src = xJSStringCreateWithUTF8CString(
"const a = 2, b = 3;\n"
"a * b;");
xJSStringRef url = xJSStringCreateWithUTF8CString("calc.js");
xJSValueRef exc = NULL;
xJSValueRef r = xJSEvaluateScript(ctx, src, NULL, url, 1, &exc);
xJSStringRelease(src);
xJSStringRelease(url);
if (!r) {
// exc holds the thrown value
xJSValueUnprotect(ctx, exc);
} else {
printf("result = %g\n", xJSValueToNumber(ctx, r, NULL)); // 6
xJSValueUnprotect(ctx, r);
}
Binding this at top level
Host code sometimes wants scripts to run against a sandbox object:
xJSObjectRef sandbox = xJSObjectMake(ctx, NULL, NULL);
xJSStringRef hello = xJSStringCreateWithUTF8CString("hello");
xJSValueRef v = xJSValueMakeNumber(ctx, 42);
xJSObjectSetProperty(ctx, sandbox, hello, v, 0, NULL);
xJSValueUnprotect(ctx, v);
xJSStringRelease(hello);
// inside the script, `this.hello` is 42
xJSStringRef src = xJSStringCreateWithUTF8CString("this.hello + 1");
xJSValueRef r = xJSEvaluateScript(ctx, src, sandbox, NULL, 0, NULL);
xJSStringRelease(src);
Pumping Async Jobs
QuickJS queues Promise reactions and queueMicrotask callbacks on a runtime-level job list, and only executes them when the host explicitly pumps:
int xJSContextDrainPendingJobs(xJSContextRef ctx, xJSValueRef *exception);
bool xJSContextHasPendingJobs (xJSContextRef ctx);
Drain keeps executing jobs until either:
- the queue is empty — returns the number of jobs executed, or
- a job throws — returns the number of successfully executed jobs before the throw; writes the first exception to
*exceptionand stops.
Typical usage:
xJSValueRef e = NULL;
int ran = xJSContextDrainPendingJobs(ctx, &e);
if (e) {
// At least one microtask threw and was not caught by a .catch
// Report it or discard; draining is already halted.
xJSValueUnprotect(ctx, e);
}
When to call it
Call xJSContextDrainPendingJobs whenever host code has performed an action that may have scheduled a reaction:
- after calling
resolve()/reject()on a deferred Promise from host land, - after returning from a host-side async callback that woke JS up,
- before releasing the context if you want
finallyblocks on live Promises to run.
xJSAwaitPromise shortcut
When you already have a specific Promise and want to block until it settles, use xJSAwaitPromise() — it drains internally and returns the fulfilment value (or NULL + exception on reject).
Garbage Collection
void xJSGarbageCollect(xJSContextRef ctx);
Forces a full GC on the context's runtime. QuickJS already triggers collection automatically based on allocation pressure; this entry point is useful for:
- tests that want deterministic finalizer ordering,
- idle hooks in long-running hosts that can afford a pause,
- leak checks just before releasing the context.
Only values with zero xjs slot references (i.e. all xJSValueUnprotect calls are balanced) and no live JS-side references are reclaimable.
Best Practices
- Drain after every host→JS settle. Whenever host code resolves/rejects a deferred, returns from a native callback that might have woken a Promise, or completes async IO, call
xJSContextDrainPendingJobs. xjs does not drive an event loop — if you forget,.thenreactions simply never run. - Use
xJSAwaitPromisefor "block until this one settles". It drains internally and surfaces the fulfilment value or exception; you almost never need a hand-rolledwhile (HasPendingJobs) Drainloop against a specific Promise. - Validate with
xJSCheckScriptSyntaxbeforexJSEvaluateScript. For user-authored scripts (editor, REPL), checking syntax first gives you a clean error channel that cannot also execute side effects. xJSCheckScriptSyntaxdoesn't see module syntax. Branch onxJSDetectModulefirst; fall through toxJSEvaluateModuleif the source is a module.- Don't leak the throw value. On a
NULLreturn, alwaysxJSValueUnprotect(ctx, exc)in the error branch — forgetting is the most common xjs leak. - Call
xJSGarbageCollectsparingly. QuickJS already collects under pressure; forcing a GC is a multi-ms pause. Reserve it for tests, idle hooks, or pre-shutdown leak checks.
Caveats
startingLineNumberis currently a no-op on the QuickJS backend; stack-trace line numbers come from source positions alone.xJSCheckScriptSyntaxcompiles as a global script — it will not catch syntax errors that are only legal in module context (e.g. top-levelimport). UsexJSDetectModulefirst and branch between the two paths if needed (see module.md).- A runaway script (infinite loop with no job queue interaction) cannot be interrupted from another thread. Host code that embeds untrusted scripts should run them in a dedicated OS thread it can kill.
xjs — ES Modules
Introduction
xjs understands ES modules — the import / export syntax plus top-level await. Module support is an moo extension relative to the JavaScriptCore C API (JSC only exposes modules through its private Objective-C surface), but the shape we chose stays close to JSC's JSModuleLoaderDelegate.
Key properties:
- Loading is asynchronous by construction:
xJSEvaluateModulereturns a Promise that fulfils once every transitive import has loaded and executed. - Specifier normalisation (resolving
./xrelative to the importer) is handled internally. The loader callback only ever sees normalised names. - No native-module registration. xjs does not expose an API for registering a
JSModuleDefbacked by C functions. The recommended pattern is "global hook + JS facade"; see the example below.
Detecting a Module
Before evaluating a random source blob, decide whether it is a script or a module:
bool xJSDetectModule(const char *source, size_t length);
This is a cheap syntactic pre-pass (scans for top-level import/export) — the same heuristic QuickJS's JS_DetectModule applies. Use it to branch between xJSEvaluateScript and xJSEvaluateModule.
Evaluating a Module
xJSValueRef xJSEvaluateModule(xJSContextRef ctx,
xJSStringRef script,
xJSStringRef sourceURL,
xJSValueRef *exception);
script— module source. Must not beNULL.sourceURL— module identifier. Used as the compile-time source URL (for stack traces andimport.meta.url) and as the base specifier against which relative imports are resolved. PassNULLfor the anonymous placeholder<xjs>.exception— populated only for compile/link-time failures. Runtime errors —throwin top-level code, rejected imports — surface through the returned Promise's rejection path.- Returns a Promise (as an
xJSValueRef) on success, orNULLon compile/setup error. Release withxJSValueUnprotect.
Awaiting the Result
Because module evaluation is asynchronous, the typical driver pattern is "evaluate, then block until the promise settles":
xJSAwaitPromise
xJSValueRef xJSAwaitPromise(xJSContextRef ctx,
xJSValueRef promise,
xJSValueRef *exception);
- Drains pending jobs on
ctx's runtime untilpromiseleaves the pending state. - Returns the fulfilment value on resolve; returns
NULLand sets*exceptionon reject. - If
promiseis not a Promise it is returned as-is with a bumped refcount — this makes the helper safe to wrap around any returned value, even if the backend happens to settle synchronously. - Detects the "promise never settles" case (queue drained but still pending) and fails loudly with an internal-error exception so host code doesn't spin silently.
xJSAwaitPromise is a general-purpose helper — not limited to modules. Use it to block on any host-side promise (e.g. one returned from xJSObjectCallAsFunction against an async function).
Module Loader Callback
typedef xJSStringRef (*xJSModuleLoadCallback)(xJSContextRef ctx,
const char *normalizedName,
void *opaque);
void xJSContextSetModuleLoader(xJSGlobalContextRef ctx,
xJSModuleLoadCallback load,
void *opaque);
- Invoked once per normalised specifier per context (xjs caches compiled modules internally — re-imports hit the cache).
- Must return a freshly-created
xJSStringRefwith the module source. xjs takes ownership and releases it after compile. - Returning
NULLsignals "module not found" — the importing evaluation rejects with aReferenceError. opaqueis the pointer you passed toxJSContextSetModuleLoader, handed back unchanged.- Installing
NULLas the callback reverts everyimportto the built-in "no loader installed" reject.
Specifier Normalisation
Relative specifiers (./x, ../y/z) are normalised against the importer's own sourceURL before reaching the callback; bare specifiers (counter, @scope/pkg) are passed through unchanged. If you want custom normalisation (e.g. an alias table), do the rewrite inside your loader when you recognise the bare name.
End-to-end Driver Pattern
xJSStringRef src = xJSStringCreateWithUTF8CString(user_source);
xJSStringRef url = xJSStringCreateWithUTF8CString("entry.js");
xJSValueRef exc = NULL;
xJSValueRef promise = xJSEvaluateModule(ctx, src, url, &exc);
xJSStringRelease(src);
xJSStringRelease(url);
if (!promise) {
// compile/link error
report_exception(ctx, exc);
if (exc) xJSValueUnprotect(ctx, exc);
return;
}
xJSValueRef result = xJSAwaitPromise(ctx, promise, &exc);
xJSValueUnprotect(ctx, promise);
if (!result) {
// runtime error
report_exception(ctx, exc);
if (exc) xJSValueUnprotect(ctx, exc);
return;
}
// `result` is the module namespace object; release when done
xJSValueUnprotect(ctx, result);
Example: Native Module Facade
The "global hook + JS facade" idiom lets you expose C functions under an ergonomic import form without adding any new API surface. Full source lives at examples/xjs_native_module.c; the essential pieces are:
-
Register C callbacks on the global object under a mangled key.
// globalThis.__native_counter = { inc, get, reset }; install_native(ctx, "__native_counter", "inc", native_counter_inc); install_native(ctx, "__native_counter", "get", native_counter_get); install_native(ctx, "__native_counter", "reset", native_counter_reset); -
Synthesize a tiny JS facade in the loader:
static xJSStringRef load_native_module(xJSContextRef ctx, const char *name, void *_) { if (strcmp(name, "counter") == 0) { static const char src[] = "const H = globalThis.__native_counter;\n" "export const increment = H.inc;\n" "export const get = H.get;\n" "export const reset = H.reset;\n"; return xJSStringCreateWithUTF8CString(src); } return NULL; } xJSContextSetModuleLoader(ctx, load_native_module, NULL); -
User code imports normally:
import { increment, get, reset } from "counter"; for (let i = 0; i < 3; i++) increment(); log("count =", get()); // count = 3
QuickJS handles binding resolution, cycle detection, and top-level await on the facade for free — no manual JSModuleDef plumbing.
Best Practices
- Always route module results through
xJSAwaitPromise. Module evaluation returns a Promise even when nothing is async — treating the return value as "just a value" will leave you holding a pending Promise and no result. - Give your entry module a real
sourceURL."entry.js"(or any path-like name) makes relative imports (./helper.js) resolvable and gives users readable stack traces. TheNULL/"<xjs>"placeholder breaks relative imports. - Make the loader fast and pure. It runs synchronously from the compiler; any IO you do inside the loader blocks module compilation. If module sources must come from disk or network, preload them into a host-side cache and have the loader hit that cache.
- Use the "global hook + JS facade" idiom for native modules. Until native
JSModuleDefregistration lands, synthesising a small JS facade in the loader is both the recommended and the only portable way. See the example above. - Bare specifiers are your alias table's job. xjs only normalises relative paths; if you want
import x from "foo"to meannode_libs/foo/index.js, do the rewrite in your loader when you see a bare name. - Don't share compiled modules across contexts. The module cache is per-context. If you need hot-path re-import, reuse the same context.
Caveats
- Module evaluation always returns a Promise — even if the module has no
awaitand no async imports. Always route throughxJSAwaitPromise(or your own job-pump loop) to retrieve the result. - The internal module cache is keyed on normalised names per context. Two contexts in the same group do not share compiled modules.
- xjs does not persist compiled byte-code to disk. Every
xJSEvaluateModulerecompiles on the calling context. - The
sourceURLyou pass toxJSEvaluateModuleis also the base specifier for relative imports — choose something like"entry.js"(not"<xjs>") if your entry module hasimport "./helper.js"statements.
xcrypto — Cryptographic Primitives
Introduction
xcrypto is moo's cryptographic module, providing common hash functions, checksums, and HMAC primitives for use by higher-level modules. It currently offers:
- Hash functions: SHA-1, SHA-256, MD5
- Checksum: CRC-32
- HMAC: Generic HMAC (RFC 2104) with streaming API, plus convenience wrappers for HMAC-SHA1, HMAC-SHA256, and HMAC-MD5
SHA-1 and SHA-256 support three backends selected at build time via X_TLS_BACKEND: OpenSSL, mbedTLS, and a pure-C builtin fallback. MD5 and CRC-32 are always pure-C with no external dependencies.
Design Philosophy
-
Backend Abstraction — Hash headers (
sha1.h,sha256.h) expose a unified API regardless of the underlying crypto library. The backend is selected at build time viaX_TLS_BACKEND, keeping runtime overhead at zero and the public interface stable. -
Zero Heap Allocation — All context structures (
xSha1Ctx,xSha256Ctx,xMd5Ctx,xHmacCtx) use fixed-size opaque buffers large enough to hold any backend's internal state. No dynamic allocation is needed. -
Dual API Surface — Every hash algorithm provides both a one-shot function (e.g.
xSha256()) for simple use cases and a streaming API (Init/Update/Final) for incremental hashing of large or chunked data. The generic HMAC also supports both modes. -
Compile-Time Static Assertions — Each backend implementation uses
_Static_assertto verify at compile time that the opaque buffer is large enough for its internal state, catching size mismatches before they become runtime bugs. -
Consistent Error Handling — All functions return
xErrnocodes and validate arguments defensively, following the same error convention used throughout moo. -
Generic HMAC via Vtable — The HMAC implementation is hash-agnostic, driven by an
xHashVtablethat describes any hash algorithm's init/update/final/sizes. Adding HMAC for a new hash requires only a one-line vtable definition.
Architecture
graph TD
subgraph "Public API"
SHA1_H["sha1.h<br/>xSha1() / Init / Update / Final"]
SHA256_H["sha256.h<br/>xSha256() / Init / Update / Final"]
MD5_H["md5.h<br/>xMd5() / Init / Update / Final"]
CRC32_H["crc32.h<br/>xCrc32()"]
HMAC_H["hmac.h<br/>xHmac() / Init / Update / Final"]
HMAC_SHA1_H["hmac_sha1.h — xHmacSha1()"]
HMAC_SHA256_H["hmac_sha256.h — xHmacSha256()"]
HMAC_MD5_H["hmac_md5.h — xHmacMd5()"]
end
subgraph "Backend Implementations"
SHA1_SSL["sha1_openssl.c"]
SHA1_MBED["sha1_mbedtls.c"]
SHA1_BUILT["sha1_builtin.c"]
SHA256_SSL["sha256_openssl.c"]
SHA256_MBED["sha256_mbedtls.c"]
SHA256_BUILT["sha256_builtin.c"]
MD5_C["md5.c (pure C)"]
CRC32_C["crc32.c (pure C)"]
end
subgraph "Generic HMAC Engine"
HMAC_C["hmac.c (RFC 2104)"]
VTABLE["xHashVtable"]
end
SHA1_H --> SHA1_SSL & SHA1_MBED & SHA1_BUILT
SHA256_H --> SHA256_SSL & SHA256_MBED & SHA256_BUILT
MD5_H --> MD5_C
CRC32_H --> CRC32_C
HMAC_SHA1_H --> HMAC_C
HMAC_SHA256_H --> HMAC_C
HMAC_MD5_H --> HMAC_C
HMAC_H --> HMAC_C
HMAC_C --> VTABLE
VTABLE -.->|"sha1"| SHA1_H
VTABLE -.->|"sha256"| SHA256_H
VTABLE -.->|"md5"| MD5_H
style SHA1_H fill:#4a90d9,color:#fff
style SHA256_H fill:#4a90d9,color:#fff
style MD5_H fill:#4a90d9,color:#fff
style CRC32_H fill:#4a90d9,color:#fff
style HMAC_H fill:#4a90d9,color:#fff
style HMAC_SHA1_H fill:#9b59b6,color:#fff
style HMAC_SHA256_H fill:#9b59b6,color:#fff
style HMAC_MD5_H fill:#9b59b6,color:#fff
style HMAC_C fill:#e67e22,color:#fff
style VTABLE fill:#e67e22,color:#fff
Backend Selection
SHA-1 and SHA-256 backends are chosen via the X_TLS_BACKEND CMake variable. MD5 and CRC-32 are always pure-C.
X_TLS_BACKEND | SHA-1 / SHA-256 Backend | External Dependency |
|---|---|---|
openssl | OpenSSL EVP API | libssl, libcrypto |
mbedtls | mbedTLS | libmbedtls |
auto | Auto-detect: OpenSSL → mbedTLS → builtin | Best available |
| (anything else) | Pure-C builtin | None |
When set to auto, CMake probes for OpenSSL first, then mbedTLS, and falls back to the builtin implementation if neither is found.
Sub-Module Overview
| Header | Description |
|---|---|
sha1.h | SHA-1 hash — one-shot and streaming API with pluggable backend |
sha256.h | SHA-256 hash — one-shot and streaming API with pluggable backend |
md5.h | MD5 hash — one-shot and streaming API (pure C, RFC 1321) |
crc32.h | CRC-32 checksum — one-shot API (pure C, ISO 3309) |
hmac.h | Generic HMAC — one-shot and streaming API (RFC 2104), works with any xHashVtable |
hmac_sha1.h | HMAC-SHA1 convenience wrapper |
hmac_sha256.h | HMAC-SHA256 convenience wrapper |
hmac_md5.h | HMAC-MD5 convenience wrapper |
API Reference
Hash Constants
| Constant | Value | Description |
|---|---|---|
XCRYPTO_SHA1_DIGEST_SIZE | 20 | SHA-1 digest length in bytes |
XCRYPTO_SHA1_BLOCK_SIZE | 64 | SHA-1 internal block size in bytes |
XCRYPTO_SHA256_DIGEST_SIZE | 32 | SHA-256 digest length in bytes |
XCRYPTO_SHA256_BLOCK_SIZE | 64 | SHA-256 internal block size in bytes |
XCRYPTO_MD5_DIGEST_SIZE | 16 | MD5 digest length in bytes |
XCRYPTO_MD5_BLOCK_SIZE | 64 | MD5 internal block size in bytes |
Hash Functions
| Function | Description |
|---|---|
xSha1(data, len, digest) | One-shot SHA-1 |
xSha1Init(ctx) / xSha1Update(ctx, data, len) / xSha1Final(ctx, digest) | Streaming SHA-1 |
xSha256(data, len, digest) | One-shot SHA-256 |
xSha256Init(ctx) / xSha256Update(ctx, data, len) / xSha256Final(ctx, digest) | Streaming SHA-256 |
xMd5(data, len, digest) | One-shot MD5 |
xMd5Init(ctx) / xMd5Update(ctx, data, len) / xMd5Final(ctx, digest) | Streaming MD5 |
xCrc32(data, len) | One-shot CRC-32 (returns uint32_t) |
HMAC Functions
| Function | Description |
|---|---|
xHmac(hash, key, key_len, data, data_len, digest) | Generic one-shot HMAC with any xHashVtable |
xHmacInit(ctx, hash, key, key_len) / xHmacUpdate(ctx, data, len) / xHmacFinal(ctx, digest) | Generic streaming HMAC |
xHmacSha1(key, key_len, data, data_len, digest) | One-shot HMAC-SHA1 convenience wrapper |
xHmacSha256(key, key_len, data, data_len, digest) | One-shot HMAC-SHA256 convenience wrapper |
xHmacMd5(key, key_len, data, data_len, digest) | One-shot HMAC-MD5 convenience wrapper |
All functions return xErrno_Ok on success (except xCrc32 which returns the checksum directly). After calling a Final function, the context must be re-initialized before reuse.
Quick Start
One-Shot SHA-256
#include <stdio.h>
#include <string.h>
#include <x/crypto/sha256.h>
int main(void) {
const char *msg = "Hello, World!";
uint8_t digest[XCRYPTO_SHA256_DIGEST_SIZE];
xErrno err = xSha256((const uint8_t *)msg, strlen(msg), digest);
if (err != xErrno_Ok) return 1;
printf("SHA-256: ");
for (int i = 0; i < XCRYPTO_SHA256_DIGEST_SIZE; i++) {
printf("%02x", digest[i]);
}
printf("\n");
return 0;
}
HMAC-SHA256
#include <stdio.h>
#include <string.h>
#include <x/crypto/hmac_sha256.h>
int main(void) {
const char *key = "secret";
const char *msg = "Hello, World!";
uint8_t digest[32];
xErrno err = xHmacSha256(
(const uint8_t *)key, strlen(key),
(const uint8_t *)msg, strlen(msg),
digest);
if (err != xErrno_Ok) return 1;
printf("HMAC-SHA256: ");
for (int i = 0; i < 32; i++) {
printf("%02x", digest[i]);
}
printf("\n");
return 0;
}
Streaming HMAC (Generic)
#include <x/crypto/hmac.h>
#include <x/crypto/hmac_sha1.h> /* for xHashVtableSha1 */
int main(void) {
xHmacCtx ctx;
uint8_t digest[20];
xHmacInit(&ctx, &xHashVtableSha1,
(const uint8_t *)"key", 3);
xHmacUpdate(&ctx, (const uint8_t *)"Hello, ", 7);
xHmacUpdate(&ctx, (const uint8_t *)"World!", 6);
xHmacFinal(&ctx, digest);
return 0;
}
Compile with:
gcc -o example example.c -I/path/to/moo -lxcrypto -lxbase
Relationship with Other Modules
graph LR
XCRYPTO["xcrypto"]
XBASE["xbase"]
XHTTP["xhttp"]
XP2P["xp2p"]
XFER["xfer"]
XCRYPTO -->|"error codes + base types"| XBASE
XHTTP -.->|"WebSocket handshake SHA-1"| XCRYPTO
XP2P -.->|"STUN HMAC-SHA1 + CRC-32"| XCRYPTO
XFER -.->|"SHA-1 integrity check"| XCRYPTO
style XCRYPTO fill:#4a90d9,color:#fff
style XBASE fill:#50b86c,color:#fff
style XHTTP fill:#f5a623,color:#fff
style XP2P fill:#e74c3c,color:#fff
style XFER fill:#9b59b6,color:#fff
- xbase — xcrypto depends on xbase for
xErrnoerror codes,XDEF_STRUCT, andXCAPImacros. - xhttp — The WebSocket handshake (RFC 6455) requires SHA-1 to compute the
Sec-WebSocket-Acceptheader. - xp2p — STUN message integrity (RFC 5389) uses HMAC-SHA1 and CRC-32 fingerprint. xp2p uses xcrypto directly.
- xfer — File transfer integrity verification uses SHA-1 checksums from xcrypto.
xp2p — P2P Connectivity & WebRTC DataChannel
Introduction
xp2p is moo's peer-to-peer connectivity module, providing a lightweight WebRTC DataChannel stack in pure C99. It implements the full protocol pipeline — ICE (NAT traversal) → DTLS (encryption) → SCTP (reliable/unreliable transport) → DataChannel (messaging) — orchestrated by a top-level xPeerConnection API that mirrors the browser RTCPeerConnection.
At the lower level, xp2p includes a complete STUN/TURN client stack, SDP encoding/decoding, and an event-driven ICE agent that handles candidate gathering, connectivity checks, and nomination. At the higher level, xPeerConnection manages SDP offer/answer negotiation, DTLS 1.2 handshake with self-signed ECDSA certificates, user-space SCTP association (via usrsctp), and the DataChannel Establishment Protocol (DCEP, RFC 8832).
Design Philosophy
-
Single-Threaded, Event-Driven — The entire stack (ICE, DTLS, SCTP, DataChannel) runs on the moo event loop. All callbacks are invoked on the event loop thread, keeping the async programming model consistent with the rest of moo.
-
RFC Compliance — Implements ICE (RFC 8445), STUN (RFC 5389), TURN (RFC 5766), DTLS 1.2 (RFC 6347), SCTP (RFC 4960), and DataChannel (DCEP, RFC 8832) with proper message integrity, fingerprint, and retransmission.
-
Pluggable DTLS Backend — The DTLS layer supports both OpenSSL and mbedTLS at compile time, making xp2p suitable for both server and embedded environments. The ICE layer's built-in crypto (MD5, SHA-1, HMAC-SHA1, CRC-32) requires no external libraries.
-
Layered Architecture — The module is cleanly layered: STUN message codec → STUN transaction manager → TURN client → ICE agent → DTLS transport → SCTP transport → DataChannel. Each layer can be used independently, or composed via
xPeerConnectionfor the full WebRTC experience. -
Minimal Footprint — Unlike full WebRTC implementations (libwebrtc ~50 MiB), xp2p focuses exclusively on DataChannel connectivity with a shared library size of ~200 KiB.
Architecture
High-Level: PeerConnection Stack
graph TD
subgraph "Application"
APP["User Application"]
end
subgraph "xPeerConnection"
PC["xPeerConnection<br/>peer_connection.h"]
DC["xDataChannelMgr / xDataChannel<br/>datachannel.h"]
SCTP["xSctpTransport<br/>sctp_transport.h"]
DTLS["xDtlsTransport<br/>dtls_transport.h"]
ICE["xIceAgent<br/>ice_agent.h"]
end
subgraph "xbase"
EV["xEventLoop<br/>event.h"]
end
APP --> PC
PC --> DC
DC --> SCTP
SCTP --> DTLS
DTLS --> ICE
ICE --> EV
style PC fill:#4a90d9,color:#fff
style DC fill:#50b86c,color:#fff
style SCTP fill:#f5a623,color:#fff
style DTLS fill:#e74c3c,color:#fff
style ICE fill:#9b59b6,color:#fff
Protocol Stack
┌─────────────────────────────┐
│ DataChannel (DCEP) │ RFC 8832 — message framing
├─────────────────────────────┤
│ SCTP (usrsctp) │ RFC 4960 — reliable/unreliable streams
├─────────────────────────────┤
│ DTLS 1.2 │ RFC 6347 — encryption
├─────────────────────────────┤
│ ICE (STUN/TURN) │ RFC 8445 — NAT traversal
├─────────────────────────────┤
│ UDP │
└─────────────────────────────┘
Low-Level: ICE Internals
graph TD
subgraph "ICE Layer"
ICE["xIceAgent<br/>ice_agent.h"]
SDP["xIceSdp<br/>SDP Codec<br/>sdp.h"]
TURN["xTurnClient<br/>TURN Client<br/>turn_client.h"]
CHAN["xTurnChannel<br/>ChannelData Framing<br/>turn_channel.h"]
TXN["xStunTxnMgr<br/>Transaction Manager<br/>stun_txn.h"]
MSG["xStunMsg<br/>Message Codec<br/>stun_msg.h"]
ATTR["xStunAttrWriter / xStunAttrIter<br/>Attribute Codec<br/>stun_attr.h"]
CAND["xIceCandidate / xIcePair<br/>Candidate & Pair<br/>ice_candidate.h / ice_pair.h"]
CRYPTO["xIceHmacSHA1 / xIceCrc32<br/>Crypto Helpers<br/>ice_crypto.h"]
end
subgraph "xbase / xnet"
EV["xEventLoop<br/>event.h"]
SOCK["xSocket<br/>socket.h"]
end
ICE --> SDP
ICE --> TURN
ICE --> TXN
ICE --> CAND
TURN --> TXN
TURN --> CHAN
TXN --> MSG
TXN --> ATTR
MSG --> CRYPTO
ATTR --> CRYPTO
ICE --> EV
ICE --> SOCK
TXN --> EV
style ICE fill:#50b86c,color:#fff
style SDP fill:#4a90d9,color:#fff
style TURN fill:#e74c3c,color:#fff
style TXN fill:#f5a623,color:#fff
style MSG fill:#9b59b6,color:#fff
style ATTR fill:#9b59b6,color:#fff
Sub-Module Overview
| Header | Component | Description | Doc |
|---|---|---|---|
peer_connection.h | xPeerConnection | WebRTC PeerConnection — orchestrates ICE + DTLS + SCTP + DataChannel | pc.md |
datachannel.h | xDataChannel / xDataChannelMgr | WebRTC DataChannel (DCEP, RFC 8832) over SCTP streams | pc.md |
dtls_transport.h | xDtlsTransport | DTLS 1.2 transport with backend-agnostic design (OpenSSL / mbedTLS) | pc.md |
sctp_transport.h | xSctpTransport | SCTP over DTLS via usrsctp for WebRTC DataChannel | pc.md |
ice_agent.h | xIceAgent | Full ICE agent — gathering, checks, nomination, data send/recv | ice.md |
ice_candidate.h | xIceCandidate | Candidate representation and priority calculation (RFC 8445 §5.1.2.1) | — |
ice_pair.h | xIcePair | Candidate pair priority and sorting (RFC 8445 §6.1.2.3) | — |
sdp.h | xIceSdp | SDP offer/answer encoding and decoding (RFC 4566) | — |
stun_msg.h | xStunMsg | STUN message header encoding/decoding (RFC 5389) | — |
stun_attr.h | xStunAttrWriter / xStunAttrIter | STUN attribute encoding/decoding with integrity and fingerprint | — |
stun_txn.h | xStunTxnMgr | STUN transaction manager with exponential-backoff retransmission | — |
turn_client.h | xTurnClient | TURN allocation, permissions, channel bindings, and relay data (RFC 5766) | — |
turn_channel.h | xTurnChannel | TURN ChannelData framing (RFC 5766 §11) | — |
ice_crypto.h | xIceHmacSHA1 / xIceCrc32 | Built-in HMAC-SHA1, SHA-1, MD5, CRC-32 | — |
Quick Start
PeerConnection (Recommended)
The xPeerConnection API is the recommended entry point for most applications. It orchestrates the full ICE → DTLS → SCTP → DataChannel pipeline:
#include <x/base/event.h>
#include <x/p2p/peer_connection.h>
#include <stdio.h>
#include <string.h>
static void on_state(xPeerConnection pc, xPeerConnectionState state, void *arg) {
printf("PeerConnection state: %d\n", state);
}
static void on_dc_open(xDataChannel channel, void *arg) {
printf("DataChannel open: %s\n", xDataChannelGetLabel(channel));
const char *msg = "Hello DataChannel!";
xDataChannelSendString(channel, msg, strlen(msg));
}
static void on_dc_message(xDataChannel channel, xDataChannelMsgType type,
const uint8_t *data, size_t len, void *arg) {
printf("Received: %.*s\n", (int)len, (const char *)data);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xPeerConnectionConf conf = {0};
conf.stun_server = "stun.l.google.com:19302";
conf.on_state_change = on_state;
conf.on_dc_open = on_dc_open;
conf.on_dc_message = on_dc_message;
xPeerConnection pc = xPeerConnectionCreate(loop, &conf);
/* Create a DataChannel */
xDataChannelConf dc_conf = {0};
strncpy(dc_conf.label, "chat", sizeof(dc_conf.label) - 1);
dc_conf.ordered = true;
xPeerConnectionCreateDataChannel(pc, &dc_conf);
/* Generate offer, exchange via signaling, then: */
// char *offer = xPeerConnectionCreateOffer(pc);
// xPeerConnectionSetLocalDescription(pc, offer);
// ... send offer to remote, receive answer ...
// xPeerConnectionSetRemoteDescription(pc, remote_answer);
xEventLoopRun(loop);
xPeerConnectionDestroy(pc);
xEventLoopDestroy(loop);
return 0;
}
See pc.md for the full PeerConnection API reference, DataChannel API, connection lifecycle, and examples.
ICE Agent (Low-Level)
For raw ICE connectivity without DTLS/SCTP/DataChannel, use the ICE agent directly:
#include <x/base/event.h>
#include <x/p2p/ice_agent.h>
#include <stdio.h>
#include <string.h>
static void on_state(xIceAgent agent, xIceState state, void *arg) {
printf("ICE state: %d\n", state);
if (state == xIceState_Connected) {
const char *msg = "Hello P2P!";
xIceAgentSend(agent, (const uint8_t *)msg, strlen(msg));
}
}
static void on_candidate(xIceAgent agent, const char *sdp, void *arg) {
if (sdp) {
printf("candidate: %s\n", sdp);
} else {
printf("gathering complete\n");
// Exchange SDP with remote peer here
}
}
static void on_data(xIceAgent agent, const uint8_t *data,
size_t len, void *arg) {
printf("received: %.*s\n", (int)len, (const char *)data);
}
int main(void) {
xEventLoop loop = xEventLoopCreate();
xIceConf conf = {0};
conf.role = xIceRole_Controlling;
conf.stun_server = "stun.l.google.com:19302";
conf.enable_ipv6 = false;
conf.on_state_change = on_state;
conf.on_candidate = on_candidate;
conf.on_data = on_data;
xIceAgent agent = xIceAgentCreate(loop, &conf);
xIceAgentGather(agent);
// After gathering, exchange SDP with remote peer:
// char *offer = xIceAgentCreateOffer(agent);
// // send offer to remote, receive answer
// xIceAgentSetRemoteDescription(agent, remote_answer);
xEventLoopRun(loop);
xIceAgentDestroy(agent);
xEventLoopDestroy(loop);
return 0;
}
See ice.md for the full ICE agent API reference.
Relationship with Other Modules
- xbase — Uses
xEventLoopfor I/O multiplexing,xSocketfor non-blocking UDP socket management, and timers for ICE connectivity checks and DTLS retransmission. - xbuf — Uses
xBufferfor SDP string assembly andxIOBufferfor DTLS read/write buffering between the ICE and SCTP layers. - xnet — Links against xnet for shared networking types.
- usrsctp — External dependency. Provides user-space SCTP (RFC 4960) for reliable/unreliable message delivery over the DTLS tunnel.
- OpenSSL / mbedTLS — External dependency (DTLS backend, compile-time selection). Provides DTLS 1.2 handshake, encryption, self-signed certificate generation, and SHA-256 fingerprint computation for SDP.
- Application — The
xPeerConnectionAPI exposes a callback-driven interface. Applications create a PeerConnection, exchange SDP offer/answer via a signaling channel, and send/receive messages over DataChannels once connected. For lower-level use, the ICE agent can be used directly.
ICE Agent — ice_agent.h
Overview
xIceAgent is the central component of the xp2p module. It implements the full ICE (Interactive Connectivity Establishment) protocol as defined in RFC 8445, providing NAT traversal and peer-to-peer UDP connectivity.
The agent handles:
- Candidate gathering — Enumerates local network interfaces (host candidates), queries STUN servers (server-reflexive candidates), and optionally allocates TURN relays (relay candidates).
- Connectivity checks — Performs STUN Binding request/response exchanges on all candidate pairs to find working paths.
- Nomination — Selects the best candidate pair for data transport (aggressive nomination in controlling mode).
- Data transport — Sends and receives application data over the nominated pair, with TURN relay fallback via ChannelData framing.
- Consent freshness — Periodically verifies the peer is still reachable (RFC 7675).
Header
#include <x/p2p/ice_agent.h>
States
The ICE agent progresses through the following states:
New → Gathering → Checking → Connected → Completed
↘ ↗
Failed
↓
Closed
| State | Value | Description |
|---|---|---|
xIceState_New | 0 | Initial state, no activity yet |
xIceState_Gathering | 1 | Gathering local candidates (host / srflx / relay) |
xIceState_Checking | 2 | Performing connectivity checks on candidate pairs |
xIceState_Connected | 3 | At least one valid pair found |
xIceState_Completed | 4 | All checks done, nominated pair selected |
xIceState_Failed | 5 | All checks failed, no valid pair |
xIceState_Closed | 6 | Agent has been shut down |
Roles
| Role | Value | Description |
|---|---|---|
xIceRole_Controlling | 0 | Initiates nomination (sends USE-CANDIDATE) |
xIceRole_Controlled | 1 | Accepts nomination from the controlling agent |
Configuration
struct xIceConf {
xIceRole role; // Controlling or Controlled
bool enable_ipv6; // Enable IPv6 candidates (default: false)
const char *stun_server; // STUN server "host:port" (or NULL)
const char *turn_server; // TURN server "host:port" (or NULL)
const char *turn_username; // TURN long-term credential username
const char *turn_password; // TURN long-term credential password
xIceOnStateChange on_state_change; // State change callback
xIceOnCandidate on_candidate; // New candidate callback
xIceOnData on_data; // Data received callback
void *ctx; // Forwarded to all callbacks
};
Callbacks
xIceOnStateChange
typedef void (*xIceOnStateChange)(xIceAgent agent, xIceState state, void *arg);
Called when the agent transitions to a new state. Use this to detect when the connection is established (Connected / Completed) or has failed.
xIceOnCandidate
typedef void (*xIceOnCandidate)(xIceAgent agent, const char *candidate_sdp, void *arg);
Called when a new local candidate is gathered. The candidate_sdp is an SDP candidate line (e.g. "candidate:...") suitable for Trickle ICE. When candidate_sdp is NULL, gathering is complete (end-of-candidates signal).
xIceOnData
typedef void (*xIceOnData)(xIceAgent agent, const uint8_t *data, size_t len, void *arg);
Called when application data is received on the nominated pair. The data buffer is valid only for the duration of the callback.
API Reference
Lifecycle
| Function | Description |
|---|---|
xIceAgentCreate(loop, conf) | Create a new ICE agent. Generates random ice-ufrag/ice-pwd. Returns NULL on failure. |
xIceAgentDestroy(agent) | Destroy the agent, close sockets, cancel timers. Safe to call with NULL. |
Gathering
| Function | Description |
|---|---|
xIceAgentGather(agent) | Start candidate gathering. Enumerates interfaces, sends STUN/TURN requests. Candidates reported via on_candidate. |
SDP Exchange
| Function | Description |
|---|---|
xIceAgentCreateOffer(agent) | Generate an SDP offer string. Caller must free() the result. |
xIceAgentCreateAnswer(agent) | Generate an SDP answer string. Caller must free() the result. |
xIceAgentSetRemoteDescription(agent, sdp) | Parse remote SDP (ice-ufrag, ice-pwd, candidates) and start connectivity checks. |
xIceAgentAddRemoteCandidate(agent, sdp) | Add a single remote candidate (Trickle ICE). |
Data Transport
| Function | Description |
|---|---|
xIceAgentSend(agent, data, len) | Send data through the nominated pair. Only valid in Connected or Completed state. |
Candidate Types
| Type | Priority Pref | Description |
|---|---|---|
host | 126 | Direct local interface address |
srflx | 100 | Server-reflexive (public address from STUN) |
prflx | 110 | Peer-reflexive (discovered during checks) |
relay | 0 | TURN relay address |
Priority is computed per RFC 8445 §5.1.2.1:
priority = (2^24) × type_pref + (2^8) × local_pref + (256 - component_id)
ICE Lifecycle Flow
sequenceDiagram
participant App as Application
participant A as Agent A (Controlling)
participant B as Agent B (Controlled)
participant STUN as STUN Server
App->>A: xIceAgentCreate(loop, conf)
App->>B: xIceAgentCreate(loop, conf)
App->>A: xIceAgentGather()
App->>B: xIceAgentGather()
A->>STUN: STUN Binding Request
B->>STUN: STUN Binding Request
STUN-->>A: Binding Response (srflx addr)
STUN-->>B: Binding Response (srflx addr)
A-->>App: on_candidate(host), on_candidate(srflx), on_candidate(NULL)
B-->>App: on_candidate(host), on_candidate(srflx), on_candidate(NULL)
App->>A: offer = xIceAgentCreateOffer()
App->>B: xIceAgentSetRemoteDescription(offer)
App->>B: answer = xIceAgentCreateAnswer()
App->>A: xIceAgentSetRemoteDescription(answer)
A->>B: STUN Binding Request (connectivity check)
B-->>A: Binding Response
A->>B: STUN Binding Request + USE-CANDIDATE
A-->>App: on_state_change(Connected)
B-->>App: on_state_change(Connected)
App->>A: xIceAgentSend("Hello!")
A->>B: UDP data
B-->>App: on_data("Hello!")
Example — Loopback Echo
The examples/ice_echo.c demo creates two agents in the same process, exchanges SDP, and echoes data:
# Default (host candidates only, no STUN)
./build/ice_echo
# With STUN server
./build/ice_echo -s stun.l.google.com:19302
# Filter to only use server-reflexive candidates
./build/ice_echo -s stun.l.google.com:19302 -f srflx
# Enable IPv6 candidate gathering
./build/ice_echo -6
Command-Line Options
| Flag | Description |
|---|---|
-s host:port | STUN server address (default: stun.l.google.com:19302). Pass -s "" to disable. |
-f type | Filter candidates by type (host, srflx, relay). Default: keep all. |
-6 | Enable IPv6 candidate gathering (disabled by default). |
Protocol Constants
| Constant | Value | Description |
|---|---|---|
XICE_GATHER_TIMEOUT_MS | 5000 | Candidate gathering timeout |
XICE_CHECK_TIMEOUT_MS | 10000 | Connectivity check timeout |
XICE_CHECK_PACING_MS | 50 | Check pacing interval |
XICE_CONSENT_INTERVAL_MS | 15000 | Consent freshness interval (RFC 7675) |
XICE_MAX_CANDIDATES | 32 | Max candidates per agent |
XICE_MAX_PAIRS | 128 | Max candidate pairs |
XSTUN_INITIAL_RTO_MS | 500 | Initial STUN retransmission timeout |
XSTUN_MAX_RETRANSMITS | 7 | Max STUN retransmissions |
PeerConnection — peer_connection.h
Overview
xPeerConnection is the top-level WebRTC API in the xp2p module. It orchestrates the full protocol stack — ICE (connectivity) → DTLS (encryption) → SCTP (transport) → DataChannel (messaging) — into a single, easy-to-use handle that mirrors the browser RTCPeerConnection API.
The PeerConnection manages:
- SDP Negotiation — Create offer/answer, set local/remote descriptions, and add trickle ICE candidates.
- ICE Connectivity — Gathers candidates, performs connectivity checks, and selects the best path.
- DTLS Encryption — Performs a DTLS 1.2 handshake over the ICE transport with self-signed ECDSA P-256 certificates.
- SCTP Association — Establishes a user-space SCTP association (via usrsctp) over the encrypted DTLS channel.
- DataChannel — Implements the DataChannel Establishment Protocol (DCEP, RFC 8832) for creating reliable/unreliable message channels.
Header
#include <x/p2p/peer_connection.h>
Architecture
graph TD
subgraph "Application"
APP["User Application"]
end
subgraph "xPeerConnection"
PC["xPeerConnection<br/>peer_connection.h"]
DC["xDataChannelMgr / xDataChannel<br/>datachannel.h"]
SCTP["xSctpTransport<br/>sctp_transport.h"]
DTLS["xDtlsTransport<br/>dtls_transport.h"]
ICE["xIceAgent<br/>ice_agent.h"]
end
subgraph "xbase"
EV["xEventLoop<br/>event.h"]
end
APP --> PC
PC --> DC
DC --> SCTP
SCTP --> DTLS
DTLS --> ICE
ICE --> EV
style PC fill:#4a90d9,color:#fff
style DC fill:#50b86c,color:#fff
style SCTP fill:#f5a623,color:#fff
style DTLS fill:#e74c3c,color:#fff
style ICE fill:#9b59b6,color:#fff
Protocol Stack
┌─────────────────────────────┐
│ DataChannel (DCEP) │ RFC 8832 — message framing
├─────────────────────────────┤
│ SCTP (usrsctp) │ RFC 4960 — reliable/unreliable streams
├─────────────────────────────┤
│ DTLS 1.2 │ RFC 6347 — encryption
├─────────────────────────────┤
│ ICE (STUN/TURN) │ RFC 8445 — NAT traversal
├─────────────────────────────┤
│ UDP │
└─────────────────────────────┘
Connection States
New → Connecting → Connected → Closed
↘ ↗
Failed / Disconnected
| State | Value | Description |
|---|---|---|
xPeerConnectionState_New | 0 | Initial state, no activity yet. |
xPeerConnectionState_Connecting | 1 | ICE/DTLS/SCTP handshake in progress. |
xPeerConnectionState_Connected | 2 | DataChannel ready for use. |
xPeerConnectionState_Disconnected | 3 | Connectivity lost (may recover). |
xPeerConnectionState_Failed | 4 | Unrecoverable failure. |
xPeerConnectionState_Closed | 5 | Explicitly closed by the application. |
Configuration
struct xPeerConnectionConf {
/* ICE configuration */
const char *stun_server; /* STUN server "host:port" or NULL. */
const char *turn_server; /* TURN server "host:port" or NULL. */
const char *turn_username; /* TURN credential username. */
const char *turn_password; /* TURN credential password. */
bool enable_ipv6; /* Enable IPv6 candidates (default: false). */
/* SCTP port (0 = default 5000). */
uint16_t sctp_port;
/* Callbacks */
xPeerConnectionOnStateChange on_state_change;
xPeerConnectionOnIceCandidate on_ice_candidate;
xPeerConnectionOnDataChannel on_datachannel;
/* Default callbacks for remotely-opened DataChannels. */
xDataChannelOnOpen on_dc_open;
xDataChannelOnMessage on_dc_message;
xDataChannelOnClose on_dc_close;
void *ctx; /* Forwarded to all callbacks. */
};
Callbacks
xPeerConnectionOnStateChange
typedef void (*xPeerConnectionOnStateChange)(xPeerConnection pc,
xPeerConnectionState state,
void *arg);
Called when the overall connection state changes. Use this to detect when the full stack (ICE + DTLS + SCTP) is ready or has failed.
xPeerConnectionOnIceCandidate
typedef void (*xPeerConnectionOnIceCandidate)(xPeerConnection pc,
const char *candidate_sdp,
void *arg);
Called when a new local ICE candidate is gathered. When candidate_sdp is NULL, gathering is complete (end-of-candidates signal). Send each candidate to the remote peer via your signaling channel for Trickle ICE.
xPeerConnectionOnDataChannel
typedef void (*xPeerConnectionOnDataChannel)(xPeerConnection pc,
xDataChannel channel,
void *arg);
Called when the remote peer opens a DataChannel. The channel handle is ready for sending/receiving messages.
API Reference
Lifecycle
| Function | Description |
|---|---|
xPeerConnectionCreate(loop, conf) | Create a new PeerConnection. Internally creates an ICE agent and DTLS transport with a self-signed certificate. Returns NULL on failure. |
xPeerConnectionDestroy(pc) | Destroy the PeerConnection and all owned resources (DataChannel, SCTP, DTLS, ICE). Safe to call with NULL. |
SDP Negotiation
| Function | Description |
|---|---|
xPeerConnectionCreateOffer(pc) | Generate a WebRTC SDP offer. Starts ICE gathering if not already started. Caller must free() the result. |
xPeerConnectionCreateAnswer(pc) | Generate a WebRTC SDP answer. Should be called after SetRemoteDescription with the offer. Caller must free() the result. |
xPeerConnectionSetLocalDescription(pc, sdp) | Set the local SDP description. Starts ICE gathering if not already started. |
xPeerConnectionSetRemoteDescription(pc, sdp) | Parse remote SDP (ICE credentials, DTLS fingerprint, SCTP port) and add remote ICE candidates. |
xPeerConnectionAddIceCandidate(pc, sdp) | Add a single remote ICE candidate (Trickle ICE). |
DataChannel
| Function | Description |
|---|---|
xPeerConnectionCreateDataChannel(pc, conf) | Create a new DataChannel. The channel opens once the SCTP association is established. Returns NULL on failure. |
Accessors
| Function | Description |
|---|---|
xPeerConnectionGetState(pc) | Get the current connection state. |
xPeerConnectionGetIceAgent(pc) | Get the underlying ICE agent handle. |
xPeerConnectionGetDtlsTransport(pc) | Get the DTLS transport handle. |
xPeerConnectionGetSctpTransport(pc) | Get the SCTP transport handle. |
xPeerConnectionGetDataChannelMgr(pc) | Get the DataChannel manager handle. |
DataChannel API
Once a DataChannel is obtained (via xPeerConnectionCreateDataChannel or the on_datachannel callback), use the following APIs:
DataChannel Configuration
struct xDataChannelConf {
char label[256]; /* Channel label. */
char protocol[256]; /* Sub-protocol (optional). */
bool ordered; /* Ordered delivery (default: true). */
uint16_t max_retransmits; /* Max retransmits (0 = reliable). */
uint16_t max_packet_life_time; /* Max lifetime ms (0 = reliable). */
/* Per-channel callbacks (override PeerConnection defaults). */
xDataChannelOnOpen on_open;
xDataChannelOnMessage on_message;
xDataChannelOnClose on_close;
xDataChannelOnError on_error;
void *ctx;
};
DataChannel Functions
| Function | Description |
|---|---|
xDataChannelSendString(channel, str, len) | Send a UTF-8 string message. |
xDataChannelSendBinary(channel, data, len) | Send a binary message. |
xDataChannelClose(channel) | Close the DataChannel. |
xDataChannelGetLabel(channel) | Get the channel label. |
xDataChannelGetState(channel) | Get the current channel state (Connecting, Open, Closing, Closed). |
xDataChannelGetStreamId(channel) | Get the underlying SCTP stream ID. |
DataChannel States
| State | Value | Description |
|---|---|---|
xDataChannelState_Connecting | 0 | OPEN sent, waiting for ACK. |
xDataChannelState_Open | 1 | Channel is open for data. |
xDataChannelState_Closing | 2 | Close initiated. |
xDataChannelState_Closed | 3 | Channel is closed. |
Connection Lifecycle Flow
sequenceDiagram
participant App as Application
participant PC_A as PeerConnection A<br/>(Offerer)
participant PC_B as PeerConnection B<br/>(Answerer)
participant STUN as STUN Server
Note over App,PC_B: 1. Create PeerConnections
App->>PC_A: xPeerConnectionCreate(loop, conf)
App->>PC_B: xPeerConnectionCreate(loop, conf)
Note over App,PC_B: 2. Create DataChannel (offerer side)
App->>PC_A: xPeerConnectionCreateDataChannel(pc, &dc_conf)
Note over App,STUN: 3. Gather ICE candidates
App->>PC_A: xIceAgentGather(xPeerConnectionGetIceAgent(pc))
App->>PC_B: xIceAgentGather(xPeerConnectionGetIceAgent(pc))
PC_A->>STUN: STUN Binding Request
PC_B->>STUN: STUN Binding Request
STUN-->>PC_A: Binding Response
STUN-->>PC_B: Binding Response
PC_A-->>App: on_ice_candidate(candidate)
PC_A-->>App: on_ice_candidate(NULL) — gathering done
PC_B-->>App: on_ice_candidate(NULL) — gathering done
Note over App,PC_B: 4. Exchange SDP
App->>PC_A: offer = xPeerConnectionCreateOffer()
App->>PC_A: xPeerConnectionSetLocalDescription(offer)
App->>PC_B: xPeerConnectionSetRemoteDescription(offer)
App->>PC_B: answer = xPeerConnectionCreateAnswer()
App->>PC_B: xPeerConnectionSetLocalDescription(answer)
App->>PC_A: xPeerConnectionSetRemoteDescription(answer)
Note over PC_A,PC_B: 5. ICE → DTLS → SCTP handshake
PC_A->>PC_B: ICE connectivity checks
PC_A-->>App: on_state_change(Connecting)
PC_A->>PC_B: DTLS handshake (ClientHello / ServerHello)
PC_A->>PC_B: SCTP INIT / INIT-ACK / COOKIE
PC_A-->>App: on_state_change(Connected)
PC_B-->>App: on_state_change(Connected)
Note over PC_A,PC_B: 6. DataChannel open
PC_A->>PC_B: DCEP DATA_CHANNEL_OPEN
PC_B-->>PC_A: DCEP DATA_CHANNEL_ACK
PC_A-->>App: on_dc_open(channel)
PC_B-->>App: on_datachannel(channel)
Note over PC_A,PC_B: 7. Exchange messages
App->>PC_A: xDataChannelSendString(channel, "Hello!")
PC_A->>PC_B: SCTP data
PC_B-->>App: on_dc_message("Hello!")
Example — Loopback Echo
The examples/pc_echo.c demo creates two PeerConnections in the same process, exchanges SDP between them, and echoes a DataChannel message:
#include <x/base/event.h>
#include <x/p2p/peer_connection.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
static xEventLoop g_loop;
static xPeerConnection g_pc_a; /* Offerer */
static xPeerConnection g_pc_b; /* Answerer */
static void on_state_change(xPeerConnection pc, xPeerConnectionState state,
void *ctx) {
const char *name = (const char *)ctx;
printf("[%s] State: %d\n", name, state);
}
static void on_dc_open(xDataChannel channel, void *ctx) {
const char *name = (const char *)ctx;
printf("[%s] DataChannel open: %s\n", name, xDataChannelGetLabel(channel));
if (strcmp(name, "PC-A") == 0) {
const char *msg = "Hello DataChannel!";
xDataChannelSendString(channel, msg, strlen(msg));
}
}
static void on_dc_message(xDataChannel channel, xDataChannelMsgType type,
const uint8_t *data, size_t len, void *ctx) {
const char *name = (const char *)ctx;
printf("[%s] Received: %.*s\n", name, (int)len, (const char *)data);
if (strcmp(name, "PC-B") == 0) {
/* Echo back */
xDataChannelSendString(channel, (const char *)data, len);
} else {
printf("Echo successful!\n");
xEventLoopStop(g_loop);
}
}
int main(void) {
g_loop = xEventLoopCreate();
/* Create offerer */
xPeerConnectionConf conf_a = {0};
conf_a.stun_server = "stun.l.google.com:19302";
conf_a.on_state_change = on_state_change;
conf_a.on_dc_open = on_dc_open;
conf_a.on_dc_message = on_dc_message;
conf_a.ctx = (void *)"PC-A";
g_pc_a = xPeerConnectionCreate(g_loop, &conf_a);
/* Create answerer */
xPeerConnectionConf conf_b = {0};
conf_b.stun_server = "stun.l.google.com:19302";
conf_b.on_state_change = on_state_change;
conf_b.on_dc_open = on_dc_open;
conf_b.on_dc_message = on_dc_message;
conf_b.ctx = (void *)"PC-B";
g_pc_b = xPeerConnectionCreate(g_loop, &conf_b);
/* Create DataChannel on offerer */
xDataChannelConf dc_conf = {0};
strncpy(dc_conf.label, "echo", XDC_MAX_LABEL_LEN - 1);
dc_conf.ordered = true;
xPeerConnectionCreateDataChannel(g_pc_a, &dc_conf);
/* Start gathering */
xIceAgentGather(xPeerConnectionGetIceAgent(g_pc_a));
xIceAgentGather(xPeerConnectionGetIceAgent(g_pc_b));
/* After both sides finish gathering, exchange SDP:
* offer = xPeerConnectionCreateOffer(g_pc_a);
* xPeerConnectionSetLocalDescription(g_pc_a, offer);
* xPeerConnectionSetRemoteDescription(g_pc_b, offer);
* answer = xPeerConnectionCreateAnswer(g_pc_b);
* xPeerConnectionSetLocalDescription(g_pc_b, answer);
* xPeerConnectionSetRemoteDescription(g_pc_a, answer);
*/
xEventLoopRun(g_loop);
xPeerConnectionDestroy(g_pc_a);
xPeerConnectionDestroy(g_pc_b);
xEventLoopDestroy(g_loop);
return 0;
}
# Build and run
./build/pc_echo
# With custom STUN server
./build/pc_echo -s stun.l.google.com:19302
# Enable IPv6
./build/pc_echo -6
DTLS Backend
The DTLS layer supports two TLS backends, selected at compile time:
| Backend | CMake Option | Description |
|---|---|---|
| OpenSSL | -DX_TLS_BACKEND=openssl (default) | Uses OpenSSL for DTLS 1.2 handshake and encryption. |
| mbedTLS | -DX_TLS_BACKEND=mbedtls | Uses mbedTLS for DTLS 1.2 handshake and encryption. |
Both backends generate a self-signed ECDSA P-256 certificate at xPeerConnectionCreate time and compute a SHA-256 fingerprint for SDP a=fingerprint.
Thread Safety
| Operation | Thread Safety |
|---|---|
xPeerConnectionCreate() | Call from event loop thread only |
xPeerConnectionDestroy() | Call from event loop thread only |
xPeerConnectionCreateOffer/Answer() | Call from event loop thread only |
xPeerConnectionSetLocal/RemoteDescription() | Call from event loop thread only |
xDataChannelSendString/Binary() | Call from event loop thread only |
| All callbacks | Always invoked on event loop thread |
Error Handling
| Scenario | Behavior |
|---|---|
NULL loop or conf in Create | Returns NULL |
| ICE gathering failure | on_state_change reports Failed |
| DTLS handshake failure | on_state_change reports Failed |
| SCTP association failure | on_state_change reports Failed |
| Invalid remote SDP | SetRemoteDescription returns error xErrno |
| Send on closed DataChannel | Returns xErrno error |
xPeerConnectionDestroy(NULL) | No-op (safe) |
Best Practices
- Exchange SDP after gathering completes — Wait for the
on_ice_candidate(NULL)signal before callingCreateOffer/CreateAnswerto include all candidates in the SDP. Alternatively, use Trickle ICE withAddIceCandidatefor faster setup. - Set callbacks in conf before Create — All callbacks must be configured in
xPeerConnectionConfbefore callingxPeerConnectionCreate. They cannot be changed after creation. - Use per-channel callbacks for complex apps — Set
on_open/on_message/on_closeinxDataChannelConfto override the PeerConnection-level defaults for individual channels. - Destroy in order — Call
xPeerConnectionDestroywhich tears down DataChannel → SCTP → DTLS → ICE in the correct order. Do not destroy sub-components individually. - One event loop thread — All PeerConnection operations and callbacks run on the event loop thread. Do not call PeerConnection APIs from other threads.
Comparison with Other Libraries
| Feature | xp2p PeerConnection | libdatachannel | Pion (Go) | libwebrtc (Google) | webtransport-go |
|---|---|---|---|---|---|
| Language | C99 | C++ | Go | C++ | Go |
| I/O Model | Async (xEventLoop, single-threaded) | Async (internal thread pool) | Goroutines | Multi-threaded | Goroutines |
| ICE | Built-in (RFC 8445, full agent) | Built-in (libnice / libjuice) | Built-in | Built-in | N/A (QUIC) |
| DTLS Backend | Pluggable (OpenSSL / mbedTLS) | GnuTLS / OpenSSL | pion/dtls (pure Go) | BoringSSL | N/A (QUIC TLS) |
| SCTP | usrsctp (user-space) | usrsctp | pion/sctp (pure Go) | usrsctp | N/A |
| DataChannel | DCEP (RFC 8832) | DCEP (RFC 8832) | DCEP (RFC 8832) | DCEP (RFC 8832) | Datagrams / Streams |
| Audio/Video | Not supported (data-only) | Optional (via libSRTP) | Full media stack | Full media stack | Not applicable |
| Binary Size | ~200 KiB (shared lib) | ~1 MiB | ~10 MiB (static) | ~50 MiB | ~5 MiB |
| Dependencies | xbase, usrsctp, OpenSSL or mbedTLS | usrsctp, GnuTLS/OpenSSL | Pure Go (zero CGo) | Many (build system) | Pure Go |
| Thread Model | Single event loop thread | Internal thread pool | Per-connection goroutines | Complex multi-threaded | Per-connection goroutines |
| API Style | C function pointers (callbacks) | C++ lambdas / callbacks | Go interfaces / channels | C++ observers | Go interfaces |
Key Differentiator: xp2p provides a lightweight, data-only WebRTC stack in pure C99 with a single-threaded event-driven architecture. Unlike libwebrtc (which bundles a full media engine at ~50 MiB), xp2p focuses exclusively on DataChannel connectivity with minimal footprint (~200 KiB). The pluggable DTLS backend (OpenSSL or mbedTLS) makes it suitable for both server and embedded environments. Compared to libdatachannel (the closest C/C++ alternative), xp2p integrates directly with xbase's event loop — no internal thread pool — giving the application full control over scheduling and avoiding synchronization overhead.
Relationship with Other Modules
- xbase — Uses
xEventLoopfor I/O multiplexing,xSocketfor non-blocking UDP socket management, and timers for ICE connectivity checks and DTLS retransmission. - xbuf — Uses
xBufferfor SDP string assembly andxIOBufferfor DTLS read/write buffering between the ICE and SCTP layers. - usrsctp — External dependency. Provides user-space SCTP (RFC 4960) for reliable/unreliable message delivery over the DTLS tunnel. Runs its own timer thread for retransmission.
- OpenSSL / mbedTLS — External dependency (DTLS backend, compile-time selection via
X_TLS_BACKEND). Provides DTLS 1.2 handshake, encryption, self-signed certificate generation, and SHA-256 fingerprint computation for SDP.
xfer — P2P File Transfer
Introduction
xfer is moo's peer-to-peer file transfer module, providing a high-level API for sending and receiving files over WebRTC DataChannels. Built on top of xp2p, it handles the full transfer pipeline — signaling server rendezvous, SDP/ICE exchange, file chunking, integrity verification (SHA-1), progress reporting, and resume support — all driven by the moo event loop.
The module ships with a built-in signaling server (xSignalServer) and client (xSignalClient) that handle session creation, peer pairing, and SDP/ICE relay over WebSocket. Applications only need to provide a file path (sender) or a transfer code (receiver) to initiate a transfer. The transfer code (e.g. AB12CD) is a short, plain session ID assigned by the signaling server. Both sender and receiver must connect to the same signaling server.
Design Philosophy
-
Zero-Configuration P2P — The sender registers with a signaling server and receives a short transfer code (session ID). The receiver uses this code along with the signaling server URL to connect. NAT traversal, encryption, and chunking are handled automatically.
-
Event-Driven, Single-Threaded — All callbacks (state changes, progress, errors) are invoked on the moo event loop thread, consistent with the rest of the moo stack.
-
Resumable Transfers — The wire protocol includes a
FILE_RESUMEmessage with a bitmap of received chunks, enabling the sender to skip already-transferred chunks after a reconnection. -
Integrity Verification — Files are SHA-1 hashed before transfer. The receiver verifies the hash after reassembly, detecting corruption or incomplete transfers.
-
Layered Architecture — The module is cleanly separated into three layers: the high-level
xTransferAPI, the signaling layer (xSignalServer/xSignalClient), and the binary wire protocol (xfer_protocol.h). Each layer can be used independently. -
Pluggable Storage Backend — All file I/O (reading the source file, writing the received file) goes through a
xTransferVfsinterface. The default implementation uses POSIXfopen/fread/fwrite, but callers can supply a custom VFS for in-memory transfers, encrypted storage, cloud-backed storage, or any other backend.
Architecture
Component Stack
graph TD
subgraph "Application"
APP["User Application"]
CUSTOM_VFS["Custom VFS<br/>(optional)"]
end
subgraph "xfer"
XFER["xTransfer<br/>xfer.h"]
SENDER["Sender Logic<br/>xfer_sender.c"]
RECEIVER["Receiver Logic<br/>xfer_receiver.c"]
VFS["xTransferVfs<br/>xfer_vfs.h"]
VFS_POSIX["POSIX VFS<br/>xfer_vfs_posix.c"]
SIG_C["xSignalClient<br/>xfer_signal.h"]
SIG_S["xSignalServer<br/>xfer_signal.h"]
PROTO["Wire Protocol<br/>xfer_protocol.h"]
end
subgraph "xp2p"
PC["xPeerConnection<br/>peer_connection.h"]
end
subgraph "xhttp"
WS_S["WebSocket Server"]
WS_C["WebSocket Client"]
end
subgraph "xbase"
EV["xEventLoop<br/>event.h"]
end
APP --> XFER
CUSTOM_VFS -.-> VFS
XFER --> SENDER
XFER --> RECEIVER
SENDER --> VFS
RECEIVER --> VFS
VFS --> VFS_POSIX
XFER --> SIG_C
XFER --> PC
XFER --> PROTO
SIG_S --> WS_S
SIG_C --> WS_C
PC --> EV
WS_S --> EV
WS_C --> EV
style XFER fill:#4a90d9,color:#fff
style SENDER fill:#4a90d9,color:#fff
style RECEIVER fill:#4a90d9,color:#fff
style VFS fill:#e74c3c,color:#fff
style VFS_POSIX fill:#e74c3c,color:#fff
style CUSTOM_VFS fill:#e74c3c,color:#fff,stroke-dasharray: 5 5
style SIG_C fill:#50b86c,color:#fff
style SIG_S fill:#50b86c,color:#fff
style PROTO fill:#f5a623,color:#fff
style PC fill:#9b59b6,color:#fff
Transfer Flow
sequenceDiagram
participant Sender
participant SignalServer
participant Receiver
Note over Sender: xTransferSendFile()
Sender->>SignalServer: WebSocket connect + "create"
SignalServer-->>Sender: code = "AB12CD"
Note over Sender: on_code("AB12CD")
Note over Receiver: xTransferRecvFile("AB12CD")
Receiver->>SignalServer: WebSocket connect + "join(AB12CD)"
SignalServer-->>Sender: peer_joined
SignalServer-->>Receiver: joined
Sender->>SignalServer: SDP offer
SignalServer->>Receiver: SDP offer
Receiver->>SignalServer: SDP answer
SignalServer->>Sender: SDP answer
Note over Sender,Receiver: ICE candidates exchanged via SignalServer
Note over Sender,Receiver: P2P DataChannel established
Sender->>Receiver: FILE_META (name, size, sha1)
loop For each chunk
Sender->>Receiver: FILE_CHUNK (id, data)
Note over Receiver: on_progress()
end
Sender->>Receiver: FILE_DONE (total_chunks, sha1)
Receiver->>Sender: FILE_ACK (status)
Note over Sender: on_state_change(Done)
Note over Receiver: on_state_change(Done)
Wire Protocol
All messages are sent over the WebRTC DataChannel in binary. Multi-byte integers use network byte order (big-endian).
┌──────────────────────────────────────────────────────────────┐
│ FILE_META │ type(1B) │ name_len(2B) │ name │ size(8B) │
│ │ │ chunk_sz(4B) │ sha1(20B) │
├──────────────────────────────────────────────────────────────┤
│ FILE_CHUNK │ type(1B) │ chunk_id(4B) │ data(variable) │
├──────────────────────────────────────────────────────────────┤
│ FILE_DONE │ type(1B) │ total_chunks(4B) │ sha1(20B) │
├──────────────────────────────────────────────────────────────┤
│ FILE_ACK │ type(1B) │ status(1B) │
├──────────────────────────────────────────────────────────────┤
│ FILE_RESUME │ type(1B) │ total_chunks(4B) │ bitmap_len(4B) │
│ │ bitmap(variable) │
└──────────────────────────────────────────────────────────────┘
| Message Type | Value | Direction | Description |
|---|---|---|---|
XFER_MSG_FILE_META | 0x01 | Sender → Receiver | File metadata (name, size, chunk size, SHA-1) |
XFER_MSG_FILE_CHUNK | 0x02 | Sender → Receiver | File data chunk |
XFER_MSG_FILE_DONE | 0x03 | Sender → Receiver | Transfer complete signal |
XFER_MSG_ACK | 0x04 | Receiver → Sender | Acknowledgement (success/failure) |
XFER_MSG_ERROR | 0x05 | Both | Error message |
XFER_MSG_CANCEL | 0x06 | Both | Cancel transfer |
XFER_MSG_FILE_RESUME | 0x07 | Receiver → Sender | Resume bitmap for skipping received chunks |
Sub-Module Overview
| Header / Source | Component | Description |
|---|---|---|
xfer.h | xTransfer | High-level file transfer API — send/receive files with progress and state callbacks |
xfer_vfs.h | xTransferVfs | Virtual file system interface for pluggable storage backends |
xfer_vfs_posix.c | xTransferPosixVfs | Built-in POSIX VFS implementation (fopen/fread/fwrite) |
xfer_sender.c | Sender Logic | Sender-side data flow: file reading, chunking, flow control |
xfer_receiver.c | Receiver Logic | Receiver-side data flow: message parsing, file writing, SHA-1 verification |
xfer_private.h | Internal Header | Shared internal structures and helpers (not part of the public API) |
xfer_signal.h | xSignalServer | WebSocket-based signaling server for session management and SDP/ICE relay |
xfer_signal.h | xSignalClient | Signaling client for connecting to the server and exchanging SDP/ICE |
xfer_protocol.h | Wire Protocol | Binary message encoding/decoding for file metadata, chunks, and control messages |
API Reference
Constants
| Constant | Value | Description |
|---|---|---|
XFER_DEFAULT_CHUNK_SIZE | 64 KB | Default chunk size for file transfer |
XFER_MAX_FILENAME_LEN | 256 | Maximum file name length |
XFER_MAX_CODE_LEN | 128 | Maximum session code length |
Types
| Type | Description |
|---|---|
xTransfer | Opaque handle to a transfer session |
xTransferState | Enum: Idle, WaitingPeer, Connecting, Transferring, Done, Failed |
xTransferRole | Enum: Sender, Receiver |
xTransferConf | Configuration struct with P2P settings, signaling URL, VFS, and callbacks |
xTransferVfs | Virtual file system interface — function pointers for open/pread/pwrite/close/etc. |
Callbacks
| Callback | Signature | Description |
|---|---|---|
xTransferOnStateChange | void (*)(xTransfer, xTransferState, void *ctx) | State transition notification |
xTransferOnProgress | void (*)(xTransfer, uint64_t transferred, uint64_t total, void *ctx) | Progress reporting |
xTransferOnCode | void (*)(xTransfer, const char *code, void *ctx) | Sender receives session code |
xTransferOnFileMeta | void (*)(xTransfer, const char *filename, uint64_t filesize, void *ctx) | Receiver learns file metadata |
xTransferOnError | void (*)(xTransfer, xErrno, const char *msg, void *ctx) | Error notification |
xTransferOnIceCandidate | void (*)(xTransfer, const char *candidate, void *ctx) | ICE candidate gathered |
VFS (Virtual File System)
The xTransferVfs struct (defined in xfer_vfs.h) abstracts all file I/O. Pass a custom VFS via xTransferConf.vfs, or leave it NULL to use the default POSIX implementation.
| Field | Signature | Required | Description |
|---|---|---|---|
ctx | void * | — | Opaque context forwarded to all callbacks |
open | void *(*)(void *ctx, const char *path, const char *mode) | ✅ | Open a file, returns opaque handle or NULL |
pread | xErrno (*)(void *ctx, void *handle, uint8_t *buf, size_t len, uint64_t offset, size_t *nread) | ✅ | Random-access read at offset |
pwrite | xErrno (*)(void *ctx, void *handle, const uint8_t *buf, size_t len, uint64_t offset, size_t *nwritten) | ✅ | Random-access write at offset |
size | xErrno (*)(void *ctx, void *handle, uint64_t *out_size) | ✅ | Get total file size |
truncate | xErrno (*)(void *ctx, void *handle, uint64_t size) | Optional | Pre-allocate / truncate storage |
flush | xErrno (*)(void *ctx, void *handle) | ✅ | Flush buffered data to persistent storage |
close | void (*)(void *ctx, void *handle) | ✅ | Close the handle |
rename | xErrno (*)(void *ctx, const char *from, const char *to) | Optional | Rename a file |
remove | xErrno (*)(void *ctx, const char *path) | Optional | Remove a file |
| Function | Signature | Description |
|---|---|---|
xTransferPosixVfs | const xTransferVfs *xTransferPosixVfs(void) | Return the built-in POSIX VFS (valid for the lifetime of the process) |
Transfer Lifecycle
| Function | Signature | Description |
|---|---|---|
xTransferCreate | xTransfer xTransferCreate(xEventLoop loop, const xTransferConf *conf) | Create a transfer session |
xTransferDestroy | void xTransferDestroy(xTransfer xfer) | Destroy and free all resources |
xTransferSendFile | xErrno xTransferSendFile(xTransfer xfer, const char *filepath) | Start sending a file |
xTransferRecvFile | xErrno xTransferRecvFile(xTransfer xfer, const char *code, const char *dest_dir) | Start receiving a file |
xTransferGetState | xTransferState xTransferGetState(xTransfer xfer) | Query current state |
xTransferGetRole | xTransferRole xTransferGetRole(xTransfer xfer) | Query role (sender/receiver) |
xTransferCancel | void xTransferCancel(xTransfer xfer) | Cancel an in-progress transfer |
SDP Negotiation (Advanced)
These functions are used internally by the signaling client but are exposed for manual SDP exchange scenarios:
| Function | Signature | Description |
|---|---|---|
xTransferCreateOffer | char *xTransferCreateOffer(xTransfer xfer) | Create SDP offer (sender, caller frees) |
xTransferCreateAnswer | char *xTransferCreateAnswer(xTransfer xfer) | Create SDP answer (receiver, caller frees) |
xTransferSetLocalDescription | xErrno xTransferSetLocalDescription(xTransfer xfer, const char *sdp) | Set local SDP |
xTransferSetRemoteDescription | xErrno xTransferSetRemoteDescription(xTransfer xfer, const char *sdp) | Set remote SDP |
xTransferGatherCandidates | xErrno xTransferGatherCandidates(xTransfer xfer) | Start ICE gathering |
Signaling Server
| Function | Signature | Description |
|---|---|---|
xSignalServerCreate | xSignalServer xSignalServerCreate(xEventLoop loop, const xSignalServerConf *conf) | Create and start a signaling server |
xSignalServerDestroy | void xSignalServerDestroy(xSignalServer server) | Destroy the server |
Signaling Client
| Function | Signature | Description |
|---|---|---|
xSignalClientCreate | xSignalClient xSignalClientCreate(xEventLoop loop, const xSignalClientConf *conf) | Create and connect to signaling server |
xSignalClientDestroy | void xSignalClientDestroy(xSignalClient client) | Destroy the client |
xSignalClientSendOffer | xErrno xSignalClientSendOffer(xSignalClient client, const char *sdp) | Send SDP offer |
xSignalClientSendAnswer | xErrno xSignalClientSendAnswer(xSignalClient client, const char *sdp) | Send SDP answer |
xSignalClientSendCandidate | xErrno xSignalClientSendCandidate(xSignalClient client, const char *candidate) | Send ICE candidate |
State Machine
stateDiagram-v2
[*] --> Idle: xTransferCreate()
Idle --> WaitingPeer: xTransferSendFile() / xTransferRecvFile()
WaitingPeer --> Connecting: Peer joined, SDP exchanged
Connecting --> Transferring: DataChannel opened
Transferring --> Done: All chunks transferred + ACK
Transferring --> Failed: Error / Cancel
WaitingPeer --> Failed: Signaling error
Connecting --> Failed: ICE / DTLS failure
Done --> [*]
Failed --> [*]
Quick Start
Sending a File
#include <x/base/event.h>
#include <x/fer/xfer.h>
#include <signal.h>
#include <stdio.h>
#include <string.h>
static xEventLoop g_loop;
static xTransfer g_xfer;
static void on_state_change(xTransfer xfer, xTransferState state, void *ctx) {
(void)xfer; (void)ctx;
switch (state) {
case xTransferState_Done:
printf("\n✅ Transfer complete!\n");
xEventLoopStop(g_loop);
return;
case xTransferState_Failed:
printf("\n❌ Transfer failed.\n");
xEventLoopStop(g_loop);
return;
default: break;
}
}
static void on_progress(xTransfer xfer, uint64_t transferred,
uint64_t total, void *ctx) {
(void)xfer; (void)ctx;
printf("\rProgress: %llu / %llu bytes (%.1f%%) ",
(unsigned long long)transferred, (unsigned long long)total,
total > 0 ? 100.0 * transferred / total : 0.0);
fflush(stdout);
}
static void on_code(xTransfer xfer, const char *code, void *ctx) {
(void)xfer; (void)ctx;
printf("Share this code with the receiver:\n %s\n", code);
}
int main(void) {
g_loop = xEventLoopCreate();
xTransferConf conf;
memset(&conf, 0, sizeof(conf));
conf.stun_server = "stun.l.google.com:19302";
conf.signal_server = "ws://127.0.0.1:8080/ws";
conf.on_state_change = on_state_change;
conf.on_progress = on_progress;
conf.on_code = on_code;
conf.vfs = NULL; /* NULL = default POSIX VFS */
g_xfer = xTransferCreate(g_loop, &conf);
xTransferSendFile(g_xfer, "myfile.bin");
xEventLoopRun(g_loop);
xTransferDestroy(g_xfer);
xEventLoopDestroy(g_loop);
return 0;
}
Receiving a File
#include <x/base/event.h>
#include <x/fer/xfer.h>
#include <stdio.h>
#include <string.h>
static xEventLoop g_loop;
static xTransfer g_xfer;
static void on_state_change(xTransfer xfer, xTransferState state, void *ctx) {
(void)xfer; (void)ctx;
switch (state) {
case xTransferState_Done:
printf("\n✅ File received!\n");
xEventLoopStop(g_loop);
return;
case xTransferState_Failed:
printf("\n❌ Transfer failed.\n");
xEventLoopStop(g_loop);
return;
default: break;
}
}
static void on_progress(xTransfer xfer, uint64_t transferred,
uint64_t total, void *ctx) {
(void)xfer; (void)ctx;
printf("\rProgress: %llu / %llu bytes (%.1f%%) ",
(unsigned long long)transferred, (unsigned long long)total,
total > 0 ? 100.0 * transferred / total : 0.0);
fflush(stdout);
}
static void on_file_meta(xTransfer xfer, const char *filename,
uint64_t filesize, void *ctx) {
(void)xfer; (void)ctx;
printf("Incoming: \"%s\" (%llu bytes)\n",
filename, (unsigned long long)filesize);
}
int main(void) {
g_loop = xEventLoopCreate();
xTransferConf conf;
memset(&conf, 0, sizeof(conf));
conf.stun_server = "stun.l.google.com:19302";
conf.signal_server = "ws://127.0.0.1:8080/ws";
conf.on_state_change = on_state_change;
conf.on_progress = on_progress;
conf.on_file_meta = on_file_meta;
g_xfer = xTransferCreate(g_loop, &conf);
xTransferRecvFile(g_xfer, "AB12CD", "/tmp/received");
xEventLoopRun(g_loop);
xTransferDestroy(g_xfer);
xEventLoopDestroy(g_loop);
return 0;
}
Running the Examples
The examples/ directory includes complete sender and receiver programs:
# Terminal 1: Start the signaling server (built-in)
# The signaling server is started automatically by xfer when needed,
# or you can run a standalone one.
./xfer_signal -p 8080
# Terminal 2: Send a file
./xfer_send -f myfile.bin -u ws://127.0.0.1:8080/ws
# Terminal 3: Receive the file (use the code printed by the sender)
./xfer_recv -c AB12CD -u ws://127.0.0.1:8080/ws -d /tmp/received
Command-line options:
| Option | xfer_send | xfer_recv | Description |
|---|---|---|---|
-f <file> | ✅ Required | — | File to send |
-c <code> | — | ✅ Required | Transfer code from sender (plain session ID) |
-d <dir> | — | Optional | Destination directory (default: /tmp/xfer_recv) |
-u <url> | ✅ Required | ✅ Required | Signaling server URL |
-s <host:port> | Optional | Optional | STUN server (default: stun.l.google.com:19302) |
-6 | Optional | Optional | Enable IPv6 candidates |
Relationship with Other Modules
- xp2p — Uses
xPeerConnectionfor the full WebRTC DataChannel stack (ICE + DTLS + SCTP + DataChannel). xfer creates a PeerConnection internally and sends/receives file data over a DataChannel. - xhttp — The signaling server and client use xhttp's WebSocket server and client for SDP/ICE relay.
- xbase — Uses
xEventLoopfor I/O multiplexing and the single-threaded callback model. - xcrypto — Uses SHA-1 for file integrity verification.
- xnet — Uses URL parsing for signaling server addresses.
Custom VFS Example
The following example shows how to implement a minimal in-memory VFS for testing:
#include <x/fer/xfer_vfs.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
uint8_t *data;
uint64_t size;
uint64_t capacity;
} MemFile;
static void *mem_open(void *ctx, const char *path, const char *mode) {
(void)ctx; (void)path; (void)mode;
MemFile *f = calloc(1, sizeof(MemFile));
return f;
}
static xErrno mem_pread(void *ctx, void *handle, uint8_t *buf,
size_t len, uint64_t offset, size_t *nread) {
(void)ctx;
MemFile *f = handle;
if (offset >= f->size) { *nread = 0; return xErrno_Ok; }
size_t avail = (size_t)(f->size - offset);
size_t n = len < avail ? len : avail;
memcpy(buf, f->data + offset, n);
*nread = n;
return xErrno_Ok;
}
static xErrno mem_pwrite(void *ctx, void *handle, const uint8_t *buf,
size_t len, uint64_t offset, size_t *nwritten) {
(void)ctx;
MemFile *f = handle;
uint64_t end = offset + len;
if (end > f->capacity) {
f->data = realloc(f->data, (size_t)end);
f->capacity = end;
}
memcpy(f->data + offset, buf, len);
if (end > f->size) f->size = end;
*nwritten = len;
return xErrno_Ok;
}
static xErrno mem_size(void *ctx, void *handle, uint64_t *out) {
(void)ctx;
*out = ((MemFile *)handle)->size;
return xErrno_Ok;
}
static xErrno mem_flush(void *ctx, void *handle) {
(void)ctx; (void)handle;
return xErrno_Ok; /* no-op for in-memory */
}
static void mem_close(void *ctx, void *handle) {
(void)ctx;
MemFile *f = handle;
if (f) { free(f->data); free(f); }
}
static const xTransferVfs g_mem_vfs = {
.ctx = NULL,
.open = mem_open,
.pread = mem_pread,
.pwrite = mem_pwrite,
.size = mem_size,
.truncate = NULL, /* optional */
.flush = mem_flush,
.close = mem_close,
.rename = NULL, /* optional */
.remove = NULL, /* optional */
};
/* Usage: */
xTransferConf conf;
memset(&conf, 0, sizeof(conf));
conf.vfs = &g_mem_vfs;
/* ... set other fields ... */
xTransfer xfer = xTransferCreate(loop, &conf);
Benchmark
End-to-end benchmarks for moo, measuring real-world performance across complete scenarios.
All benchmarks run on Apple M3 Pro (12 cores, 36 GB), macOS 26.4, Clang 17, Release (-O2).
For micro-benchmark results, see the Benchmark section at the bottom of each module's documentation page.
Available Benchmarks
| Benchmark | Description |
|---|---|
| HTTP Server | moo single-threaded HTTP/1.1 server vs Go net/http — 152 K req/s, +15–60% faster across all scenarios |
| HTTP/2 Server | moo single-threaded h2c server vs Go net/http + x/net/http2 — 576 K req/s, +15–405% faster across all scenarios |
| HTTPS Server | moo single-threaded HTTPS server vs Go net/http + crypto/tls — 512 K req/s (HTTPS/2), TLS-bound parity on HTTPS/1.1 |
| WebSocket Server | moo single-threaded WS echo server vs Go gorilla/websocket, nhooyr/websocket, gobwas/ws — 220 K msg/s, +18–27% faster than best Go library |
HTTP Server Benchmark
End-to-end HTTP/1.1 server benchmark comparing moo (single-threaded event-loop) against Go net/http (goroutine-per-connection).
Test Environment
| Item | Value |
|---|---|
| CPU | Apple M3 Pro (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.4 (Darwin) |
| Compiler | Apple Clang 17.0.0 |
| Build | Release (-O2) |
| Load Generator | wrk — 4 threads, 10s duration |
Server Implementations
moo (bench/http_bench_server.cpp)
Single-threaded event-loop HTTP/1.1 server built on xbase/event.h + xhttp/server.h. Uses kqueue on macOS, epoll on Linux. All I/O is handled in one thread — no thread pool, no goroutines.
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
./build/bench/http_bench_server 8080
Go (bench/http_bench_server.go)
Standard net/http server with default settings. Go's runtime spawns one goroutine per connection and uses its own epoll/kqueue poller internally.
go build -o build/bench/go_http_bench bench/http_bench_server.go
./build/bench/go_http_bench 8081
Routes
Both servers implement identical routes:
| Route | Method | Description |
|---|---|---|
/ping | GET | Returns "pong" (4 bytes) — minimal response latency test |
/echo?size=N | GET | Returns N bytes of 'x' — variable response size test |
/echo | POST | Echoes request body — request body throughput test |
Benchmark Methodology
All benchmarks use wrk with the following defaults unless noted:
- 4 threads (
-t4) - 100 connections (
-c100) - 10 seconds (
-d10s)
POST benchmarks use Lua scripts to set the request body:
wrk.method = "POST"
wrk.headers["Content-Type"] = "application/octet-stream"
wrk.body = string.rep("x", BODY_SIZE)
Results
GET /ping — Minimal Response Latency
Tests raw request/response overhead with a 4-byte "pong" response. Varies connection count to measure scalability.
| Connections | moo Req/s | Go Req/s | moo Latency | Go Latency | Δ |
|---|---|---|---|---|---|
| 50 | 151,935 | 128,639 | 315 μs | 365 μs | moo +18% |
| 100 | 152,316 | 128,915 | 658 μs | 761 μs | moo +18% |
| 200 | 151,007 | 128,162 | 1.33 ms | 1.55 ms | moo +18% |
| 500 | 155,486 | 125,471 | 3.20 ms | 3.96 ms | moo +24% |
Analysis:
- moo maintains ~152K req/s regardless of connection count, showing excellent scalability of the single-threaded event loop.
- Go's throughput slightly degrades at 500 connections due to goroutine scheduling overhead.
- moo's advantage grows from +18% to +24% as connection count increases — the event loop's O(1) dispatch scales better than goroutine context switching.
GET /echo — Variable Response Size
Tests response serialization throughput with different payload sizes. Fixed at 100 connections.
| Response Size | moo Req/s | Go Req/s | moo Latency | Go Latency | Δ |
|---|---|---|---|---|---|
| 64 B | 150,592 | 127,432 | 666 μs | 771 μs | moo +18% |
| 256 B | 146,487 | 126,907 | 682 μs | 774 μs | moo +15% |
| 1 KiB | 144,831 | 125,729 | 689 μs | 785 μs | moo +15% |
| 4 KiB | 141,511 | 91,886 | 707 μs | 1.08 ms | moo +54% |
Analysis:
- moo throughput degrades gracefully from 151K to 142K req/s as response size grows from 64B to 4KB — only a 6% drop.
- Go drops sharply at 4KB (92K req/s, -27% from 64B), likely due to
bytes.Repeatallocation pressure and GC overhead. - moo's largest advantage (+54%) appears at 4KB, where Go's per-request heap allocation becomes the bottleneck.
POST /echo — Request Body Throughput
Tests request body parsing and echo throughput. Fixed at 100 connections.
| Body Size | moo Req/s | Go Req/s | moo Transfer/s | Go Transfer/s | Δ |
|---|---|---|---|---|---|
| 1 KiB | 141,495 | 122,584 | 152.35 MB/s | 133.51 MB/s | moo +15% |
| 4 KiB | 133,935 | 83,512 | 536.60 MB/s | 337.13 MB/s | moo +60% |
| 16 KiB | 82,231 | 53,828 | 1.26 GB/s | 848.10 MB/s | moo +53% |
| 64 KiB | 35,908 | 31,124 | 2.20 GB/s | 1.90 GB/s | moo +15% |
Analysis:
- moo achieves 2.20 GB/s transfer rate at 64KB body size — impressive for a single-threaded server.
- The largest advantage (+60%) appears at 4KB, consistent with the GET /echo pattern — Go's allocation overhead dominates at medium payload sizes.
- At 64KB, the gap narrows to +15% as both servers become I/O bound (kernel socket buffer management dominates).
Summary
moo vs Go net/http (Release build)
====================================
GET /ping: moo +18% ~ +24% (consistent across all concurrency levels)
GET /echo: moo +15% ~ +54% (advantage grows with response size)
POST /echo: moo +15% ~ +60% (advantage peaks at medium body sizes)
Peak throughput: moo 155K req/s (GET /ping, 500 connections)
Peak transfer: moo 2.20 GB/s (POST /echo, 64KB body)
Key Takeaways:
- moo wins every scenario. A single-threaded C event loop outperforms Go's multi-goroutine runtime across all request types and payload sizes.
- Scalability. moo's throughput is nearly flat from 50 to 500 connections. Go degrades under high connection counts due to goroutine scheduling overhead.
- Payload efficiency. moo's advantage is most pronounced at medium payloads (1–4 KiB) where Go's per-request heap allocation and GC pressure become significant.
- Architecture matters. moo's single-threaded design eliminates all synchronization overhead. Go pays for goroutine creation, scheduling, and garbage collection on every request.
Reproducing
# Build moo server
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
# Build Go server
go build -o build/bench/go_http_bench bench/http_bench_server.go
# Run moo benchmark
./build/bench/http_bench_server 8080 &
wrk -t4 -c100 -d10s http://127.0.0.1:8080/ping
wrk -t4 -c100 -d10s "http://127.0.0.1:8080/echo?size=64"
wrk -t4 -c100 -d10s "http://127.0.0.1:8080/echo?size=4096"
# POST with lua script
cat > /tmp/post.lua << 'EOF'
wrk.method = "POST"
wrk.headers["Content-Type"] = "application/octet-stream"
wrk.body = string.rep("x", 4096)
EOF
wrk -t4 -c100 -d10s -s /tmp/post.lua http://127.0.0.1:8080/echo
# Run Go benchmark (same wrk commands, different port)
./build/bench/go_http_bench 8081 &
wrk -t4 -c100 -d10s http://127.0.0.1:8081/ping
HTTP/2 Server Benchmark
End-to-end HTTP/2 (h2c, cleartext) server benchmark comparing moo (single-threaded event-loop) against Go net/http + x/net/http2/h2c (goroutine-per-connection).
Test Environment
| Item | Value |
|---|---|
| CPU | Apple M3 Pro (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.4 (Darwin) |
| Compiler | Apple Clang 17.0.0 |
| Build | Release (-O2) |
| Load Generator | h2load (nghttp2 1.68.1) — 4 threads, 10s duration, 10 max concurrent streams per connection |
Server Implementations
moo (bench/http_bench_server.cpp)
Single-threaded event-loop HTTP/2 server built on xbase/event.h + xhttp/server.h. Supports h2c (cleartext HTTP/2) via Prior Knowledge — the same binary as the HTTP/1.1 benchmark, since moo auto-detects the protocol on the first bytes of each connection.
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
./build/bench/http_bench_server 8080
Go (bench/h2c_bench_server.go)
Standard net/http server wrapped with golang.org/x/net/http2/h2c.NewHandler() to support cleartext HTTP/2 via Prior Knowledge. Go's runtime spawns one goroutine per connection and uses its own epoll/kqueue poller internally.
cd bench && go build -o ../build/bench/go_h2c_bench h2c_bench_server.go
./build/bench/go_h2c_bench 8081
Routes
Both servers implement identical routes:
| Route | Method | Description |
|---|---|---|
/ping | GET | Returns "pong" (4 bytes) — minimal response latency test |
/echo?size=N | GET | Returns N bytes of 'x' — variable response size test |
/echo | POST | Echoes request body — request body throughput test |
Benchmark Methodology
All benchmarks use h2load with the following defaults unless noted:
- 4 threads (
-t4) - 100 connections (
-c100) - 10 max concurrent streams per connection (
-m10) - 10 seconds (
-D 10)
POST benchmarks use -d <file> to specify the request body.
Why h2load? Unlike wrk (HTTP/1.1 only), h2load is purpose-built for HTTP/2 benchmarking. It supports stream multiplexing (
-m), h2c Prior Knowledge, and reports per-stream latency.
Results
GET /ping — Minimal Response Latency
Tests raw request/response overhead with a 4-byte "pong" response. Varies connection count to measure scalability under HTTP/2 multiplexing.
| Connections | moo Req/s | Go Req/s | moo Latency | Go Latency | Δ |
|---|---|---|---|---|---|
| 50 | 576,249 | 141,655 | 863 μs | 3.51 ms | moo +307% |
| 100 | 561,825 | 120,732 | 1.78 ms | 8.27 ms | moo +365% |
| 200 | 555,800 | 110,143 | 3.59 ms | 18.10 ms | moo +405% |
| 500 | 538,905 | 136,719 | 9.22 ms | 36.21 ms | moo +294% |
Analysis:
- moo sustains ~560K req/s across all connection counts — a massive improvement over its HTTP/1.1 numbers (~152K) thanks to HTTP/2 stream multiplexing on fewer TCP connections.
- Go's h2c throughput (~110–142K) is comparable to its HTTP/1.1 numbers, suggesting Go's HTTP/2 implementation doesn't benefit as much from multiplexing.
- moo's advantage ranges from +294% to +405% — far larger than the +18–24% gap seen in HTTP/1.1. The single-threaded event loop excels at handling multiplexed streams without context-switching overhead.
- At 200 connections, moo's advantage peaks at +405%. Go's throughput degrades more steeply under high connection counts due to goroutine scheduling and HTTP/2 flow control overhead.
GET /echo — Variable Response Size
Tests response serialization throughput with different payload sizes under HTTP/2 framing. Fixed at 100 connections.
| Response Size | moo Req/s | Go Req/s | moo Latency | Go Latency | Δ |
|---|---|---|---|---|---|
| 64 B | 518,176 | 123,386 | 1.92 ms | 8.08 ms | moo +320% |
| 256 B | 511,276 | 116,267 | 1.95 ms | 8.60 ms | moo +340% |
| 1 KiB | 493,405 | 115,267 | 2.03 ms | 8.64 ms | moo +328% |
| 4 KiB | 383,507 | 107,457 | 2.59 ms | 9.23 ms | moo +257% |
Analysis:
- moo throughput degrades gracefully from 518K to 384K req/s as response size grows from 64B to 4KB — a 26% drop, mostly due to HTTP/2 DATA frame serialization overhead.
- Go stays relatively flat (~107–123K) but at a much lower baseline. The
bytes.Repeatallocation + GC pressure is compounded by HTTP/2 framing overhead. - moo's advantage is consistently +257% to +340% — HTTP/2's HPACK header compression and binary framing amplify moo's architectural advantage over Go.
POST /echo — Request Body Throughput
Tests request body parsing and echo throughput under HTTP/2. Fixed at 100 connections.
| Body Size | moo Req/s | Go Req/s | moo Transfer/s | Go Transfer/s | Δ |
|---|---|---|---|---|---|
| 1 KiB | 401,047 | 119,739 | 399.45 MB/s | 119.82 MB/s | moo +235% |
| 4 KiB | 195,221 | 90,585 | 766.61 MB/s | 356.84 MB/s | moo +115% |
| 16 KiB | 57,304 | 41,313 | 896.83 MB/s | 648.24 MB/s | moo +39% |
| 64 KiB | 19,040 | 16,557 | 1.16 GB/s | 1.01 GB/s | moo +15% |
Analysis:
- moo achieves 1.16 GB/s transfer rate at 64KB body size — comparable to its HTTP/1.1 performance (2.20 GB/s), with the difference attributable to HTTP/2 flow control and framing overhead.
- The advantage narrows from +235% (1KB) to +15% (64KB) as both servers become I/O bound. HTTP/2 flow control (default 64KB window) becomes the bottleneck at large payloads.
- At small payloads (1KB), moo's +235% advantage shows the efficiency of its nghttp2-based H2 implementation vs Go's
x/net/http2.
HTTP/2 vs HTTP/1.1 Comparison
How does HTTP/2 compare to HTTP/1.1 for each server? (GET /ping, 100 connections)
| Server | HTTP/1.1 Req/s | HTTP/2 Req/s | Δ |
|---|---|---|---|
| moo | 152,316 | 561,825 | +269% |
| Go | 128,915 | 120,732 | −6% |
Key Insight: moo's single-threaded event loop benefits enormously from HTTP/2 multiplexing — handling multiple streams on fewer connections eliminates per-connection overhead. Go's goroutine-per-connection model doesn't gain from multiplexing because it already handles concurrency at the goroutine level; the added HTTP/2 framing overhead actually causes a slight regression.
Summary
moo vs Go h2c (Release build, h2load -m10)
=============================================
GET /ping: moo +294% ~ +405% (massive advantage across all concurrency)
GET /echo: moo +257% ~ +340% (consistent across all response sizes)
POST /echo: moo +15% ~ +235% (advantage narrows as payloads grow)
Peak throughput: moo 576K req/s (GET /ping, 50 connections)
Peak transfer: moo 1.16 GB/s (POST /echo, 64KB body)
Key Takeaways:
- HTTP/2 amplifies moo's advantage. The gap widens from +18–24% (HTTP/1.1) to +294–405% (HTTP/2) on GET /ping. Stream multiplexing plays to the strengths of a single-threaded event loop.
- moo scales with multiplexing. moo's throughput jumps from 152K (HTTP/1.1) to 576K (HTTP/2) req/s — a 3.8× improvement. Go's throughput stays flat or slightly regresses.
- Payload efficiency. At small-to-medium payloads, moo's nghttp2-based H2 implementation is dramatically faster. At large payloads (64KB), both servers converge as I/O and flow control dominate.
- Architecture matters even more for H2. HTTP/2's stream multiplexing, HPACK compression, and flow control add complexity that a lean C event loop handles more efficiently than Go's runtime.
Reproducing
# Build moo server
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
# Build Go h2c server
cd bench && go build -o ../build/bench/go_h2c_bench h2c_bench_server.go && cd ..
# Install h2load (macOS)
brew install nghttp2
# Start servers
./build/bench/http_bench_server 8080 &
./build/bench/go_h2c_bench 8081 &
# GET /ping benchmark
h2load -t4 -c100 -m10 -D 10 http://127.0.0.1:8080/ping
h2load -t4 -c100 -m10 -D 10 http://127.0.0.1:8081/ping
# GET /echo benchmark
h2load -t4 -c100 -m10 -D 10 "http://127.0.0.1:8080/echo?size=1024"
h2load -t4 -c100 -m10 -D 10 "http://127.0.0.1:8081/echo?size=1024"
# POST /echo benchmark (create body file first)
dd if=/dev/zero bs=4096 count=1 | tr '\0' 'x' > /tmp/body_4k.bin
h2load -t4 -c100 -m10 -D 10 -d /tmp/body_4k.bin http://127.0.0.1:8080/echo
h2load -t4 -c100 -m10 -D 10 -d /tmp/body_4k.bin http://127.0.0.1:8081/echo
# Cleanup
pkill -f http_bench_server
pkill -f go_h2c_bench
HTTPS Server Benchmark
End-to-end HTTPS server benchmark comparing moo (single-threaded event-loop, OpenSSL) against Go net/http + crypto/tls (goroutine-per-connection). Tests both HTTPS/1.1 (wrk) and HTTPS/2 (h2load with ALPN).
Test Environment
| Item | Value |
|---|---|
| CPU | Apple M3 Pro (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.4 (Darwin) |
| Compiler | Apple Clang 17.0.0 |
| Build | Release (-O2) |
| TLS Backend | OpenSSL 3.6.1 (moo), Go crypto/tls (Go) |
| Certificate | RSA 2048-bit self-signed, TLS 1.3 |
| Load Generator | wrk (HTTP/1.1 over TLS), h2load (HTTP/2 over TLS with ALPN) |
Server Implementations
moo (bench/https_bench_server.cpp)
Single-threaded event-loop HTTPS server built on xbase/event.h + xhttp/server.h + OpenSSL. Uses xHttpServerListenTls() which automatically sets ALPN to {"h2", "http/1.1"}, so the same server handles both HTTPS/1.1 and HTTPS/2 depending on client negotiation.
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
openssl req -x509 -newkey rsa:2048 -keyout bench_key.pem -out bench_cert.pem \
-days 365 -nodes -subj '/CN=localhost'
./build/bench/https_bench_server 8443 bench_cert.pem bench_key.pem
Go (bench/https_bench_server.go)
Standard net/http server with crypto/tls and x/net/http2.ConfigureServer(). Go's TLS implementation is in pure Go (crypto/tls), while moo uses OpenSSL's C implementation. Both servers configure ALPN for h2 and http/1.1.
cd bench && go build -o ../build/bench/go_https_bench https_bench_server.go
./build/bench/go_https_bench 8444 bench_cert.pem bench_key.pem
Routes
Both servers implement identical routes:
| Route | Method | Description |
|---|---|---|
/ping | GET | Returns "pong" (4 bytes) — minimal response latency test |
/echo?size=N | GET | Returns N bytes of 'x' — variable response size test |
/echo | POST | Echoes request body — request body throughput test |
Results
HTTPS/1.1 — GET /ping (wrk, varying connections)
Tests HTTPS/1.1 performance where each connection maintains its own TLS session. wrk reuses connections (no per-request handshake), so this measures encrypted request/response throughput.
| Connections | moo Req/s | Go Req/s | moo Latency | Go Latency | Δ |
|---|---|---|---|---|---|
| 50 | 125,147 | 125,076 | 395 μs | 372 μs | ≈ 0% |
| 100 | 124,593 | 128,277 | 0.86 ms | 764 μs | Go +3% |
| 200 | 122,837 | 127,075 | 1.88 ms | 1.57 ms | Go +3% |
| 500 | 111,397 | 122,498 | 5.25 ms | 4.06 ms | Go +10% |
Analysis:
- Under HTTPS/1.1, moo and Go are nearly identical at low connection counts (~125K req/s each). This is a dramatic contrast to plaintext HTTP/1.1 where moo was +18–24% faster.
- TLS encryption is the bottleneck, not the HTTP layer. OpenSSL's AES-GCM encryption on a single thread saturates at ~125K req/s regardless of the HTTP framework above it.
- At 500 connections, Go pulls ahead by ~10% because Go's multi-threaded runtime can parallelize TLS encryption across all CPU cores, while moo's single-threaded event loop is limited to one core for both TLS and HTTP processing.
- moo's latency is slightly higher at high connection counts (5.25 ms vs 4.06 ms at 500 connections) — the single thread must serialize all TLS encrypt/decrypt operations.
HTTPS/2 — GET /ping (h2load, varying connections)
Tests HTTPS/2 performance with TLS + ALPN negotiation. HTTP/2 multiplexing reduces the number of TLS sessions needed, which should benefit the single-threaded moo.
| Connections | moo Req/s | Go Req/s | moo Latency | Go Latency | Δ |
|---|---|---|---|---|---|
| 50 | 511,586 | 165,341 | 975 μs | 2.99 ms | moo +209% |
| 100 | 508,685 | 144,024 | 1.96 ms | 6.88 ms | moo +253% |
| 200 | 497,775 | 131,749 | 4.01 ms | 15.00 ms | moo +278% |
Analysis:
- With HTTPS/2, moo regains its massive advantage: +209% to +278% over Go. HTTP/2 multiplexing means fewer TLS sessions are needed — multiple streams share one encrypted connection, so the TLS overhead is amortized.
- moo achieves ~510K req/s over HTTPS/2 — only ~10% less than its h2c (cleartext HTTP/2) performance of 562K. The TLS overhead is minimal when amortized across multiplexed streams.
- Go's HTTPS/2 throughput (~131–165K) is comparable to its h2c numbers (~121–142K), suggesting Go's TLS overhead is also well-amortized but the HTTP/2 processing itself is the bottleneck.
HTTPS/2 — GET /echo (h2load, varying response size)
Tests response serialization + TLS encryption throughput with different payload sizes. Fixed at 100 connections.
| Response Size | moo Req/s | Go Req/s | moo Latency | Go Latency | Δ |
|---|---|---|---|---|---|
| 64 B | 470,607 | 146,727 | 2.11 ms | 6.74 ms | moo +221% |
| 1 KiB | 388,828 | 140,926 | 2.56 ms | 6.99 ms | moo +176% |
| 4 KiB | 227,414 | 118,595 | 4.38 ms | 8.22 ms | moo +92% |
Analysis:
- moo's advantage narrows as response size grows (from +221% at 64B to +92% at 4KB) because TLS encryption of larger payloads becomes a bigger fraction of total work.
- At 4KB responses, moo still achieves 893 MB/s encrypted throughput vs Go's 466 MB/s.
HTTPS/2 — POST /echo (h2load, varying body size)
Tests request body parsing + TLS decryption/encryption throughput. Fixed at 100 connections.
| Body Size | moo Req/s | Go Req/s | moo Transfer/s | Go Transfer/s | Δ |
|---|---|---|---|---|---|
| 1 KiB | 291,086 | 146,916 | 289.93 MB/s | 147.01 MB/s | moo +98% |
| 4 KiB | 128,229 | 104,892 | 503.54 MB/s | 413.20 MB/s | moo +22% |
| 16 KiB | 38,975 | 37,391 | 609.97 MB/s | 586.70 MB/s | moo +4% |
| 64 KiB | 10,278 | 14,994 | 643.30 MB/s | 939.77 MB/s | Go +46% |
Analysis:
- At small payloads (1KB), moo is +98% faster. At medium payloads (4KB), the gap narrows to +22%.
- At 16KB, the two are nearly tied (+4%). At 64KB, Go wins by +46% — this is the first scenario where Go decisively beats moo.
- The 64KB crossover happens because: (1) TLS encryption of 64KB payloads is CPU-intensive and benefits from Go's multi-core parallelism, (2) HTTP/2 flow control window (default 64KB) creates back-pressure that the single-threaded event loop handles less efficiently than Go's goroutine scheduler.
Protocol Comparison
How does TLS affect performance for each protocol? (GET /ping, 100 connections)
| Server | HTTP/1.1 | HTTPS/1.1 | Δ (TLS cost) |
|---|---|---|---|
| moo | 152,316 | 124,593 | −18% |
| Go | 128,915 | 128,277 | −0.5% |
| Server | h2c | HTTPS/2 | Δ (TLS cost) |
|---|---|---|---|
| moo | 561,825 | 508,685 | −9% |
| Go | 120,732 | 144,024 | +19% |
Key Insights:
- TLS costs moo 18% on HTTP/1.1 because every connection requires its own TLS session, and all encryption runs on a single thread. Go's multi-core TLS is essentially free (−0.5%).
- TLS costs moo only 9% on HTTP/2 because multiplexed streams share TLS sessions. This is why HTTPS/2 is moo's sweet spot.
- Go actually gets faster with HTTPS/2 vs h2c (+19%) — likely because TLS session caching and ALPN negotiation provide a more optimized code path in Go's
crypto/tls+x/net/http2stack.
Summary
moo vs Go HTTPS (Release build, OpenSSL 3.6.1)
=================================================
HTTPS/1.1 (wrk):
GET /ping: Go ≈ moo (−0% to +10% Go advantage at high connections)
GET /echo 1KB: Go +10%
HTTPS/2 (h2load -m10):
GET /ping: moo +209% ~ +278%
GET /echo: moo +92% ~ +221%
POST /echo: moo +98% (1KB) → Go +46% (64KB)
Peak throughput: moo 512K req/s (HTTPS/2 GET /ping, 50 connections)
Peak transfer: Go 940 MB/s (HTTPS/2 POST /echo, 64KB body)
Key Takeaways:
- HTTPS/1.1 is TLS-bound. Single-threaded OpenSSL encryption caps moo at ~125K req/s — the same as Go. The HTTP framework advantage disappears when TLS dominates.
- HTTPS/2 restores moo's advantage. Stream multiplexing amortizes TLS overhead across streams, letting moo's efficient event loop shine again (+209–278% on GET /ping).
- Large payloads favor Go. At 64KB POST bodies, Go's multi-core TLS parallelism wins by +46%. This is the only scenario where Go decisively beats moo.
- Choose your protocol wisely. For latency-sensitive APIs with small payloads, HTTPS/2 + moo is optimal. For bulk data transfer, Go's multi-core TLS is more efficient.
Reproducing
# Build moo server
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
# Build Go HTTPS server
cd bench && go build -o ../build/bench/go_https_bench https_bench_server.go && cd ..
# Generate self-signed certificate
openssl req -x509 -newkey rsa:2048 -keyout /tmp/bench_key.pem \
-out /tmp/bench_cert.pem -days 365 -nodes -subj '/CN=localhost'
# Install tools (macOS)
brew install wrk nghttp2
# Start servers
./build/bench/https_bench_server 8443 /tmp/bench_cert.pem /tmp/bench_key.pem &
./build/bench/go_https_bench 8444 /tmp/bench_cert.pem /tmp/bench_key.pem &
# HTTPS/1.1 benchmark (wrk)
wrk -t4 -c100 -d10s https://127.0.0.1:8443/ping
wrk -t4 -c100 -d10s https://127.0.0.1:8444/ping
# HTTPS/2 benchmark (h2load)
h2load -t4 -c100 -m10 -D 10 https://127.0.0.1:8443/ping
h2load -t4 -c100 -m10 -D 10 https://127.0.0.1:8444/ping
# POST benchmark
dd if=/dev/zero bs=4096 count=1 | tr '\0' 'x' > /tmp/body_4k.bin
h2load -t4 -c100 -m10 -D 10 -d /tmp/body_4k.bin https://127.0.0.1:8443/echo
h2load -t4 -c100 -m10 -D 10 -d /tmp/body_4k.bin https://127.0.0.1:8444/echo
# Cleanup
pkill -f https_bench_server
pkill -f go_https_bench
WebSocket Server Benchmark
End-to-end WebSocket echo server benchmark comparing moo (single-threaded event-loop) against three popular Go WebSocket libraries:
- gorilla/websocket — The most widely used Go WebSocket library
- nhooyr/websocket (coder/websocket) — Modern API with context support
- gobwas/ws — Zero-allocation, low-level WebSocket library
Test Environment
| Item | Value |
|---|---|
| CPU | Apple M3 Pro (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.4 (Darwin) |
| Compiler | Apple Clang 17.0.0 |
| Build | Release (-O2) |
| Load Generator | Custom Go client (ws_bench_client.go) using gorilla/websocket |
Server Implementations
All servers implement the same behavior: accept WebSocket connections and echo every received message back to the sender.
moo (bench/ws_bench_server.cpp)
Single-threaded event-loop WebSocket server built on xbase/event.h + xhttp/ws.h. Uses xWsServe() for a one-line WebSocket-only server. All frame parsing, masking, ping/pong, and close handshake are handled automatically.
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
./build/bench/ws_bench_server 9090
gorilla/websocket (bench/ws_bench_server_gorilla.go)
Standard net/http server with gorilla/websocket.Upgrader. One goroutine per connection with a simple ReadMessage / WriteMessage loop. Buffer sizes set to 4KB.
cd bench && go build -o ../build/bench/ws_bench_gorilla ws_bench_server_gorilla.go
./build/bench/ws_bench_gorilla 9091
nhooyr/websocket (bench/ws_bench_server_nhooyr.go)
Standard net/http server with nhooyr.io/websocket.Accept. Uses the streaming Reader / Writer API with io.Copy for zero-copy echo.
cd bench && go build -o ../build/bench/ws_bench_nhooyr ws_bench_server_nhooyr.go
./build/bench/ws_bench_nhooyr 9092
gobwas/ws (bench/ws_bench_server_gobwas.go)
Raw TCP listener with gobwas/ws.Upgrader for zero-allocation upgrade. Uses wsutil.ReadClientData / wsutil.WriteServerMessage for frame I/O. One goroutine per connection.
cd bench && go build -o ../build/bench/ws_bench_gobwas ws_bench_server_gobwas.go
./build/bench/ws_bench_gobwas 9093
Benchmark Methodology
The benchmark client (ws_bench_client.go) establishes N concurrent WebSocket connections to the server. Each connection runs a synchronous echo loop: send a message → wait for the echo → measure round-trip latency → repeat. The test runs for 10 seconds.
Key parameters:
- Connections: 50, 100, 200, 500
- Message sizes: 64B, 256B, 1KB, 4KB
- Message type: Binary
- Duration: 10 seconds per test
Note: The benchmark client uses gorilla/websocket for all tests. This means the client-side overhead is identical across all server tests, ensuring a fair comparison of server-side performance.
Results
Echo 64B — Varying Connection Count
Tests raw message throughput with minimal 64-byte payloads. Varies connection count to measure scalability.
| Connections | moo Msg/s | gorilla Msg/s | nhooyr Msg/s | gobwas Msg/s |
|---|---|---|---|---|
| 50 | 219,850 | 173,133 | 107,570 | 138,360 |
| 100 | 219,813 | 180,373 | 125,386 | 140,522 |
| 200 | 218,997 | 184,335 | 140,378 | 141,859 |
| 500 | 218,078 | 184,820 | 155,729 | 141,970 |
moo vs best Go library (gorilla):
| Connections | moo | gorilla | Δ |
|---|---|---|---|
| 50 | 219,850 | 173,133 | moo +27% |
| 100 | 219,813 | 180,373 | moo +22% |
| 200 | 218,997 | 184,335 | moo +19% |
| 500 | 218,078 | 184,820 | moo +18% |
Latency (64B, varying connections):
| Connections | moo | gorilla | nhooyr | gobwas |
|---|---|---|---|---|
| 50 | 227 μs | 289 μs | 465 μs | 361 μs |
| 100 | 455 μs | 554 μs | 797 μs | 711 μs |
| 200 | 913 μs | 1.08 ms | 1.42 ms | 1.41 ms |
| 500 | 2.29 ms | 2.70 ms | 3.21 ms | 3.52 ms |
Analysis:
- moo sustains ~219K msg/s across all connection counts — virtually no throughput degradation from 50 to 500 connections. The single-threaded event loop handles all connections without context-switching overhead.
- gorilla/websocket is the fastest Go library at ~173–185K msg/s, benefiting from its mature, optimized implementation.
- gobwas/ws — despite being marketed as "zero-allocation" — is slower than gorilla in this echo benchmark (~138–142K). Its advantage is in memory efficiency for massive connection counts, not raw throughput.
- nhooyr/websocket is the slowest at ~108–156K msg/s. The streaming
Reader/WriterAPI adds overhead compared to gorilla's simplerReadMessage/WriteMessage. - moo's latency advantage is most pronounced at low connection counts (227 μs vs 289 μs at 50 connections) and narrows at high counts as all servers become scheduling-bound.
Echo — Varying Message Size (100 connections)
Tests message throughput and transfer rate with different payload sizes. Fixed at 100 connections.
| Message Size | moo Msg/s | gorilla Msg/s | nhooyr Msg/s | gobwas Msg/s |
|---|---|---|---|---|
| 64 B | 219,813 | 180,373 | 125,386 | 140,522 |
| 256 B | 216,760 | 179,909 | 122,661 | 140,677 |
| 1 KiB | 197,890 | 173,142 | 120,963 | 133,002 |
| 4 KiB | 133,553 | 125,313 | 100,829 | 92,203 |
Transfer Rate (send + recv):
| Message Size | moo | gorilla | nhooyr | gobwas |
|---|---|---|---|---|
| 64 B | 26.84 MB/s | 22.02 MB/s | 15.31 MB/s | 17.15 MB/s |
| 256 B | 105.84 MB/s | 87.85 MB/s | 59.89 MB/s | 68.69 MB/s |
| 1 KiB | 386.50 MB/s | 338.17 MB/s | 236.26 MB/s | 259.77 MB/s |
| 4 KiB | 1.02 GB/s | 979 MB/s | 788 MB/s | 720 MB/s |
Latency (100 connections, varying message size):
| Message Size | moo | gorilla | nhooyr | gobwas |
|---|---|---|---|---|
| 64 B | 455 μs | 554 μs | 797 μs | 711 μs |
| 256 B | 461 μs | 556 μs | 815 μs | 711 μs |
| 1 KiB | 505 μs | 577 μs | 826 μs | 752 μs |
| 4 KiB | 749 μs | 798 μs | 992 μs | 1.08 ms |
Analysis:
- moo achieves 1.02 GB/s transfer rate at 4KB messages — the only server to break the 1 GB/s barrier.
- At 4KB, the ranking shifts: moo > gorilla > nhooyr > gobwas. gobwas drops to last place because its
ReadClientData/WriteServerMessageAPI allocates a new byte slice per message, negating its "zero-allocation upgrade" advantage. - moo's advantage over gorilla narrows from +22% (64B) to +7% (4KB) as both servers become I/O bound at larger payloads.
- All servers show graceful throughput degradation as message size grows, with moo maintaining the lowest latency across all sizes.
Go Library Comparison (WS)
How do the three Go libraries compare against each other? (100 connections, 64B)
| Library | Msg/s | Latency | Relative |
|---|---|---|---|
| gorilla/websocket | 180,373 | 554 μs | baseline |
| gobwas/ws | 140,522 | 711 μs | −22% |
| nhooyr/websocket | 125,386 | 797 μs | −30% |
Key Insight: In a pure echo benchmark, gorilla/websocket is the fastest Go library. gobwas/ws's advantage lies in memory efficiency for 100K+ idle connections (not measured here), while nhooyr/websocket prioritizes API ergonomics over raw performance.
WSS (WebSocket over TLS) Benchmark
The same echo benchmark repeated over TLS (wss://) to measure the impact of encryption on throughput and latency. All servers use the same self-signed certificate (bench_cert.pem / bench_key.pem, RSA 2048-bit, TLSv1.3).
WSS Server Implementations
- moo (
bench/wss_bench_server.cpp) — UsesxHttpServerCreate()+xWsUpgrade()+xHttpServerListenTls(). ALPN set tohttp/1.1only (WebSocket requires HTTP/1.1 upgrade). Single-threaded event loop handles both TLS and WebSocket I/O. - Go servers (
bench/wss_bench_server_{gorilla,nhooyr,gobwas}.go) — Same logic as WS versions but withListenAndServeTLS(gorilla/nhooyr) ortls.Listen(gobwas). Go'scrypto/tlsruns TLS per-goroutine, parallelizing encryption across connections.
WSS Echo 64B — Varying Connection Count
| Connections | moo Msg/s | gorilla Msg/s | nhooyr Msg/s | gobwas Msg/s |
|---|---|---|---|---|
| 50 | 186,513 | 173,125 | 107,589 | 138,317 |
| 100 | 186,068 | 180,426 | 133,218 | 142,187 |
| 200 | 184,066 | 185,792 | 148,475 | 144,361 |
| 500 | 167,019 | 184,532 | 156,695 | 143,220 |
moo vs gorilla (WSS):
| Connections | moo | gorilla | Δ |
|---|---|---|---|
| 50 | 186,513 | 173,125 | moo +8% |
| 100 | 186,068 | 180,426 | moo +3% |
| 200 | 184,066 | 185,792 | gorilla +1% |
| 500 | 167,019 | 184,532 | gorilla +10% |
Latency (WSS 64B, varying connections):
| Connections | moo | gorilla | nhooyr | gobwas |
|---|---|---|---|---|
| 50 | 268 μs | 289 μs | 465 μs | 361 μs |
| 100 | 537 μs | 554 μs | 750 μs | 703 μs |
| 200 | 1.09 ms | 1.08 ms | 1.35 ms | 1.38 ms |
| 500 | 2.99 ms | 2.71 ms | 3.19 ms | 3.49 ms |
Analysis:
- At low connection counts (50–100), moo still leads by 3–8% over gorilla. The single-threaded event loop's efficiency offsets the TLS overhead.
- At 200+ connections, gorilla overtakes moo. Go's per-goroutine
crypto/tlsparallelizes encryption across all CPU cores, while moo's single-threaded OpenSSL must serialize all TLS operations on one core. - The TLS overhead reduces moo's throughput by ~15% compared to plain WS (186K vs 220K at 100 conns). Go libraries show minimal TLS impact because Go's TLS is already goroutine-parallel.
- moo's throughput degrades more steeply at 500 connections (167K, −10% from 50 conns) compared to plain WS (218K, −1%). This confirms TLS as the bottleneck for the single-threaded model.
WSS Echo — Varying Message Size (100 connections)
| Message Size | moo Msg/s | gorilla Msg/s | nhooyr Msg/s | gobwas Msg/s |
|---|---|---|---|---|
| 64 B | 165,952 | 180,923 | 128,983 | 141,951 |
| 256 B | 174,475 | 178,725 | 131,257 | 141,520 |
| 1 KiB | 149,246 | 172,198 | 127,026 | 135,534 |
| 4 KiB | 92,686 | 137,560 | 105,289 | 107,550 |
Transfer Rate (WSS, send + recv):
| Message Size | moo | gorilla | nhooyr | gobwas |
|---|---|---|---|---|
| 64 B | 20.26 MB/s | 22.09 MB/s | 15.75 MB/s | 17.33 MB/s |
| 256 B | 85.19 MB/s | 87.27 MB/s | 64.09 MB/s | 69.10 MB/s |
| 1 KiB | 291.50 MB/s | 336.32 MB/s | 248.10 MB/s | 264.71 MB/s |
| 4 KiB | 723.95 MB/s | 1.05 GB/s | 822.88 MB/s | 840.23 MB/s |
Analysis:
- At 64B, gorilla leads slightly (181K vs 166K). Go's per-goroutine
crypto/tlsparallelizes encryption across all CPU cores, giving it an advantage even at small payloads. - At 256B+, gorilla maintains its lead because Go parallelizes TLS encryption across goroutines while moo serializes it on one thread.
- At 4KB, moo achieves 92,686 msg/s — competitive with nhooyr (105K) and gobwas (108K), though gorilla leads at 138K. The single-threaded TLS model is the main bottleneck, but moo remains within the same order of magnitude as the Go libraries.
- Future work could add a TLS write thread pool or io_uring-based async TLS to close the gap at larger payloads.
WS vs WSS Performance Impact
How much does TLS reduce throughput? (100 connections, 64B)
| Server | WS Msg/s | WSS Msg/s | TLS Overhead |
|---|---|---|---|
| moo | 219,813 | 165,952 | −25% |
| gorilla | 180,373 | 180,923 | ~0% |
| nhooyr | 125,386 | 128,983 | +3% ¹ |
| gobwas | 140,522 | 141,951 | +1% ¹ |
¹ Slight WSS improvement over WS is within measurement noise and likely due to system load variance between test runs.
Key Insight: Go's crypto/tls adds virtually zero overhead in this benchmark because TLS operations run in parallel across goroutines. moo pays a 25% penalty because all TLS encryption/decryption happens on the single event loop thread.
Summary
WebSocket Echo Benchmark (Release build)
=========================================
WS — 64B echo (100 conns):
moo: 219,813 msg/s 455 μs
gorilla: 180,373 msg/s 554 μs (moo +22%)
gobwas: 140,522 msg/s 711 μs (moo +56%)
nhooyr: 125,386 msg/s 797 μs (moo +75%)
WS — 4KB echo (100 conns):
moo: 133,553 msg/s 749 μs 1.02 GB/s
gorilla: 125,313 msg/s 798 μs 979 MB/s (moo +7%)
nhooyr: 100,829 msg/s 992 μs 788 MB/s (moo +32%)
gobwas: 92,203 msg/s 1.08 ms 720 MB/s (moo +45%)
WSS — 64B echo (100 conns):
gorilla: 180,923 msg/s 553 μs
moo: 165,952 msg/s 603 μs (gorilla +9%)
gobwas: 141,951 msg/s 704 μs
nhooyr: 128,983 msg/s 775 μs
WSS — 4KB echo (100 conns):
gorilla: 137,560 msg/s 728 μs 1.05 GB/s
gobwas: 107,550 msg/s 930 μs 840 MB/s
nhooyr: 105,289 msg/s 950 μs 823 MB/s
moo: 92,686 msg/s 1.08 ms 724 MB/s (gorilla +48%)
Peak WS throughput: moo 219,850 msg/s (64B, 50 connections)
Peak WS transfer: moo 1.02 GB/s (4KB, 100 connections)
Peak WSS throughput: moo 186,513 msg/s (64B, 50 connections)
Peak WSS transfer: gorilla 1.05 GB/s (4KB, 100 connections)
Key Takeaways:
- moo is 18–27% faster than gorilla on plain WS (small messages), and 3–8% faster on WSS at low connection counts. The single-threaded event loop avoids goroutine scheduling overhead.
- TLS changes the picture at scale. At 200+ connections or 1KB+ messages over WSS, gorilla overtakes moo because Go parallelizes TLS across goroutines while moo serializes it on one thread.
- moo's WS throughput is remarkably stable across connection counts (219K at 50 conns vs 218K at 500 conns — less than 1% variation). WSS shows more degradation (186K → 167K) due to single-threaded TLS.
- gorilla/websocket is the fastest Go library for both WS and WSS echo workloads.
- Single-threaded TLS is the main bottleneck for large payloads. At WSS 4KB, moo (93K msg/s) trails gorilla (138K msg/s) by ~48%. Future work could add a TLS write thread pool or io_uring-based async TLS to close the gap.
Reproducing
# Build moo servers
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DX_BUILD_BENCHMARKS=ON
cmake --build build --parallel
# Build Go servers and client
cd bench
go build -o ../build/bench/ws_bench_client ws_bench_client.go
go build -o ../build/bench/ws_bench_gorilla ws_bench_server_gorilla.go
go build -o ../build/bench/ws_bench_nhooyr ws_bench_server_nhooyr.go
go build -o ../build/bench/ws_bench_gobwas ws_bench_server_gobwas.go
go build -o ../build/bench/wss_bench_gorilla wss_bench_server_gorilla.go
go build -o ../build/bench/wss_bench_nhooyr wss_bench_server_nhooyr.go
go build -o ../build/bench/wss_bench_gobwas wss_bench_server_gobwas.go
cd ..
# Generate self-signed certificate for WSS benchmarks
openssl req -x509 -newkey rsa:2048 \
-keyout build/bench/bench_key.pem \
-out build/bench/bench_cert.pem \
-days 365 -nodes -subj '/CN=localhost'
# Run WS benchmarks (one server at a time)
./build/bench/ws_bench_server 9090 &
./build/bench/ws_bench_client -url ws://127.0.0.1:9090/ -c 100 -d 10s -size 64
kill %1
./build/bench/ws_bench_gorilla 9091 &
./build/bench/ws_bench_client -url ws://127.0.0.1:9091/ -c 100 -d 10s -size 64
kill %1
./build/bench/ws_bench_nhooyr 9092 &
./build/bench/ws_bench_client -url ws://127.0.0.1:9092/ -c 100 -d 10s -size 64
kill %1
./build/bench/ws_bench_gobwas 9093 &
./build/bench/ws_bench_client -url ws://127.0.0.1:9093/ -c 100 -d 10s -size 64
kill %1
# Run WSS benchmarks (from build/bench directory for cert paths)
cd build/bench
./wss_bench_server 9090 bench_cert.pem bench_key.pem &
./ws_bench_client -url wss://127.0.0.1:9090/ -c 100 -d 10s -size 64
kill %1
./wss_bench_gorilla 9091 bench_cert.pem bench_key.pem &
./ws_bench_client -url wss://127.0.0.1:9091/ -c 100 -d 10s -size 64
kill %1
./wss_bench_nhooyr 9092 bench_cert.pem bench_key.pem &
./ws_bench_client -url wss://127.0.0.1:9092/ -c 100 -d 10s -size 64
kill %1
./wss_bench_gobwas 9093 bench_cert.pem bench_key.pem &
./ws_bench_client -url wss://127.0.0.1:9093/ -c 100 -d 10s -size 64
kill %1
WSS Async TLS Offload — Performance Regression Report
This document records the benchmark results after introducing async TLS offload (BIO pair + thread pool) to the OpenSSL backend, compared against the previous synchronous TLS baseline from ws_server.md.
Changes Under Test
The following changes were applied to the OpenSSL TLS transport:
- Async TLS offload: TLS encryption/decryption is offloaded from the event loop thread to a worker thread pool via
xEventLoopSubmit. The event loop thread handles socket I/O and BIO data transfer, while worker threads performSSL_read/SSL_write. - BIO pair transport: Replaced direct
SSL_read(fd)/SSL_write(fd)with a BIO pair architecture:read(fd)→BIO_write(bio_net)→ workerSSL_read→BIO_read(bio_int)→ callback. - xRingBuffer replaces xMemBIO_: In
transport_mbedtls.c, the customxMemBIO_ring buffer was replaced with the sharedxRingBufferfromxbuf/. - xRingBufferWrite semantic change:
xRingBufferWritechanged from all-or-nothing (xErrno) to partial-write (size_t), merging the oldxRingBufferWritePartial.
Test Environment
| Item | Value |
|---|---|
| CPU | Apple M3 Pro (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.4 (Darwin) |
| Compiler | Apple Clang 17.0.0 |
| Build | Release (-O2) |
| TLS Backend | OpenSSL (system) |
| Certificate | RSA 2048-bit, self-signed, TLSv1.3 |
| Load Generator | ws_bench_client.go (gorilla/websocket) |
Results
WSS Echo 64B — Varying Connection Count
| Connections | Sync TLS (baseline) | Async TLS Offload | Δ Throughput | Δ Latency |
|---|---|---|---|---|
| 50 | 186,513 msg/s, 268 μs | 56,737 msg/s, 881 μs | −70% | +229% |
| 100 | 186,068 msg/s, 537 μs | 56,692 msg/s, 1.76 ms | −70% | +228% |
| 200 | 184,066 msg/s, 1.09 ms | 57,223 msg/s, 3.49 ms | −69% | +220% |
| 500 | 167,019 msg/s, 2.99 ms | 55,144 msg/s, 9.06 ms | −67% | +203% |
WSS Echo — Varying Message Size (100 connections)
| Message Size | Sync TLS (baseline) | Async TLS Offload | Δ Throughput |
|---|---|---|---|
| 64 B | 165,952 msg/s | 56,692 msg/s | −66% |
| 256 B | 174,475 msg/s | 54,170 msg/s | −69% |
| 1 KiB | 149,246 msg/s | 54,589 msg/s | −63% |
| 4 KiB | 92,686 msg/s | 51,142 msg/s | −45% |
Transfer Rate (100 connections)
| Message Size | Sync TLS | Async TLS Offload | Δ |
|---|---|---|---|
| 64 B | 20.26 MB/s | 6.92 MB/s | −66% |
| 256 B | 85.19 MB/s | 26.45 MB/s | −69% |
| 1 KiB | 291.50 MB/s | 106.62 MB/s | −63% |
| 4 KiB | 723.95 MB/s | 399.55 MB/s | −45% |
Latency (100 connections, varying message size)
| Message Size | Sync TLS | Async TLS Offload | Δ |
|---|---|---|---|
| 64 B | 537 μs | 1.76 ms | +228% |
| 256 B | — | 1.85 ms | — |
| 1 KiB | — | 1.83 ms | — |
| 4 KiB | — | 1.95 ms | — |
Analysis
Performance is severely degraded
Across all test cases, the async TLS offload shows a 65–70% throughput reduction and 2–3× latency increase compared to the synchronous TLS baseline. The degradation is consistent across connection counts and message sizes.
Root causes
-
Thread pool scheduling overhead dominates small-message TLS cost. For 64-byte messages, AES-GCM encryption/decryption takes on the order of nanoseconds, but each
xEventLoopSubmit→ worker thread → done callback round-trip costs tens of microseconds due to context switching, mutex contention, and cache invalidation. The scheduling overhead is orders of magnitude larger than the crypto work itself. -
Extra data copies through BIO pair. The synchronous path does
SSL_read(fd)directly — one syscall, zero copies between buffers. The async path requires:read(fd)→ memcpy intoxRingBuffer(inbound)→ worker threadSSL_readreads from BIO →BIO_writeoutput → memcpy intoxRingBuffer(outbound)→write(fd). This adds at least 2 extra memcpy operations per message direction. -
Serialization bottleneck not eliminated. The async offload was intended to free the event loop thread from TLS work, but the event loop still must: (a)
read(fd)ciphertext, (b) feed it into the inbound ring buffer, (c) drain the outbound ring buffer, (d)write(fd)ciphertext. The worker thread only does the SSL state machine. For a single-threaded event loop, this splits one thread's work into two threads' serial work (event loop → worker → event loop), adding synchronization overhead without parallelism. -
Throughput ceiling around 57K msg/s. The async path's throughput is remarkably stable across connection counts (55K–57K), suggesting the bottleneck is the per-message offload overhead rather than I/O or crypto. This is consistent with a fixed per-message cost of ~17 μs (1/57K), which matches typical thread pool dispatch latency.
-
4KB messages show the smallest regression (−45%). As message size grows, the crypto cost increases relative to the fixed scheduling overhead, making the offload less wasteful. This confirms that the overhead is per-message, not per-byte.
Comparison with Go goroutine-parallel TLS
For reference, gorilla/websocket achieves ~180K msg/s on WSS with virtually zero TLS overhead compared to plain WS. Go's crypto/tls runs per-goroutine, parallelizing encryption across all CPU cores without the BIO-pair indirection. This is the model that async TLS offload was trying to approximate, but the single event loop + thread pool architecture cannot match it.
Conclusion
The async TLS offload architecture is a net negative for the WSS echo workload. The per-message thread dispatch overhead far exceeds the TLS crypto cost for small-to-medium messages (64B–4KB).
Recommendations
-
Revert to synchronous TLS for the default path. The synchronous
SSL_read(fd)/SSL_write(fd)model is 3× faster for this workload. The event loop thread can handle TLS inline without issue. -
Consider async offload only for large payloads. If async TLS is desired, gate it behind a message-size threshold (e.g., >16KB) where the crypto cost justifies the dispatch overhead.
-
Explore multi-threaded event loops instead. Rather than offloading TLS from a single event loop, run multiple event loop threads (one per core), each handling its own connections with synchronous TLS. This is how Go achieves parallelism — not by offloading crypto, but by running independent I/O loops in parallel.
-
If async TLS is kept, optimize the dispatch path. Reduce per-message overhead by batching multiple SSL operations per dispatch, using lock-free queues, or coalescing small messages before offloading.
Event Loop — Benchmark Report
Micro-benchmark comparison of moo's xEventLoop against libuv 1.52.1 across three dimensions: cross-thread wake latency, timer scheduling, and offload round-trip (submit work → done callback on loop thread).
Test Environment
| Item | Value |
|---|---|
| CPU | Apple M3 Pro (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.4 (Darwin) |
| Compiler | Apple Clang 17.0.0 |
| Build | Release (-O2) |
| Framework | Google Benchmark |
| Event Backend | kqueue (moo), kqueue (libuv) |
| Workers | 4 threads (for offload benchmarks) |
Results
Core Operations (moo only)
| Benchmark | Time (ns) | CPU (ns) | Iterations |
|---|---|---|---|
BM_EventLoop_CreateDestroy | 700 | 700 | 974,157 |
BM_EventLoop_WakeLatency | 413 | 413 | 1,717,088 |
BM_EventLoop_PipeAddDel | 1,144 | 1,144 | 612,118 |
- Create/Destroy takes ~700ns — reduced from ~2.8µs after eliminating the wake pipe (no more
pipe()+ two extra fds). Reflects only kqueue fd creation + internal structure allocation. - Wake latency is ~413ns per wake+wait cycle via
EVFILT_USER, down from ~879ns with the old pipe mechanism — a 2.1× improvement. - Add/Del cycle (register + unregister a pipe fd) takes ~1.1µs — low overhead for dynamic fd management.
Wake Latency — moo vs libuv
| moo | libuv | Ratio | |
|---|---|---|---|
| Time | 413 ns | 417 ns | moo 1.01× faster |
moo now uses EVFILT_USER on kqueue (macOS) and eventfd on epoll (Linux) for wake notification, replacing the previous pipe-based mechanism. Combined with an atomic wake_pending flag for coalescing, this eliminates all pipe overhead. The result is effectively tied with libuv (413ns vs 417ns), closing the previous 2.1× gap entirely.
Timer Scheduling
moo — Timer
| Benchmark | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|
BM_EventLoop_TimerSingle | 461 | 461 | 2.17M items/s |
BM_EventLoop_TimerBatch/10 | 750 | 750 | 13.34M items/s |
BM_EventLoop_TimerBatch/100 | 3,714 | 3,714 | 26.93M items/s |
BM_EventLoop_TimerBatch/1000 | 43,550 | 43,545 | 22.96M items/s |
libuv — Timer
| Benchmark | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|
BM_Libuv_TimerSingle | 12,361 | 1,517 | 659.2k items/s |
BM_Libuv_TimerBatch/10 | 12,613 | 1,787 | 5.60M items/s |
BM_Libuv_TimerBatch/100 | 16,412 | 5,311 | 18.83M items/s |
BM_Libuv_TimerBatch/1000 | 79,721 | 68,659 | 14.56M items/s |
Comparison — Timer (CPU time)
| Batch Size | moo (CPU ns) | libuv (CPU ns) | Ratio |
|---|---|---|---|
| 1 | 461 | 1,517 | moo 3.29× faster |
| 10 | 750 | 1,787 | moo 2.38× faster |
| 100 | 3,714 | 5,311 | moo 1.43× faster |
| 1,000 | 43,545 | 68,659 | moo 1.58× faster |
Analysis:
- Single timer — moo wins at ~461ns vs libuv's ~1.5µs (3.3× faster). moo's timer path is simpler: heap push +
xEventWaitpops and fires in one call. libuv'suv_timer_start+uv_run(UV_RUN_ONCE)has more overhead per invocation. - Batch timers — moo now wins across all batch sizes, a dramatic reversal from the previous results where libuv was 4–5× faster. The key optimizations that closed the gap:
- Batch pop with single lock: Timer dispatch now acquires
timer_muonce, pops all expired timers into a local list, releases the lock, then fires them — eliminating N lock/unlock cycles. - Timer struct freelist: Timer structs are recycled via a lock-free freelist, eliminating
malloc/freeper timer operation. - Throughput: At batch size 1000, moo achieves 22.96M items/s vs libuv's 14.56M items/s — 1.58× faster.
- Batch pop with single lock: Timer dispatch now acquires
Offload Round-Trip (Submit → Done Callback)
moo — Offload
| Benchmark | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|
BM_EventLoop_OffloadSingle | 6,401 | 3,785 | 264.2k items/s |
BM_EventLoop_OffloadBatch/10 | 14,989 | 12,243 | 816.8k items/s |
BM_EventLoop_OffloadBatch/100 | 56,563 | 46,534 | 2.15M items/s |
BM_EventLoop_OffloadBatch/1000 | 496,393 | 456,426 | 2.19M items/s |
libuv — Offload
| Benchmark | Time (ns) | CPU (ns) | Throughput |
|---|---|---|---|
BM_Libuv_OffloadSingle | 5,843 | 3,449 | 290.0k items/s |
BM_Libuv_OffloadBatch/10 | 13,909 | 10,239 | 976.7k items/s |
BM_Libuv_OffloadBatch/100 | 35,838 | 30,061 | 3.33M items/s |
BM_Libuv_OffloadBatch/1000 | 242,694 | 218,513 | 4.58M items/s |
Comparison — Offload (CPU time)
| Batch Size | moo (CPU ns) | libuv (CPU ns) | Ratio |
|---|---|---|---|
| 1 | 3,785 | 3,449 | libuv 1.10× faster |
| 10 | 12,243 | 10,239 | libuv 1.20× faster |
| 100 | 46,534 | 30,061 | libuv 1.55× faster |
| 1,000 | 456,426 | 218,513 | libuv 2.09× faster |
Analysis:
- Single offload — Nearly tied (~1.10× gap, narrowed from 1.16×). Both are dominated by the same bottleneck: waking a sleeping worker thread via kernel syscall.
- Batch offload — libuv remains ~2× faster at scale. The gap has narrowed slightly at smaller batch sizes (1.20× at 10, down from 1.45×) thanks to wake coalescing and work item pooling. The remaining gap is primarily due to:
- Completion notification: libuv workers post to an async handle and the loop drains all completions in one
uv__work_done()call. moo uses an MPSC queue with atomic wake coalescing. - Allocation model: libuv's
uv_work_tis caller-allocated (stack or embedded). moo uses a lock-free freelist pool, which is faster than malloc but still has CAS overhead.
- Completion notification: libuv workers post to an async handle and the loop drains all completions in one
Summary
| Dimension | Before Optimization | After Optimization | vs libuv |
|---|---|---|---|
| Wake Latency | 879 ns (libuv 2.1× faster) | 413 ns | Tied (moo 1.01× faster) |
| Timer (single) | 974 ns (moo 1.6× faster) | 461 ns | moo 3.3× faster |
| Timer (batch ×1000) | 318,805 ns (libuv 4.3× faster) | 43,545 ns | moo 1.6× faster |
| Offload (single) | 4,110 ns (libuv 1.2× faster) | 3,785 ns | libuv 1.1× faster (tied) |
| Offload (batch ×1000) | 507,346 ns (libuv 1.95× faster) | 456,426 ns | libuv 2.1× faster |
Key Improvements
| Optimization | Impact |
|---|---|
EVFILT_USER / eventfd wake | Wake latency 2.1× faster (879→413ns), closed gap with libuv |
| Timer batch-pop (single lock) | Timer batch/1000 7.3× faster (318µs→43µs), now beats libuv |
| Timer struct freelist | Eliminated per-timer malloc, contributes to batch improvement |
| Work item freelist (Treiber stack) | Reduced offload overhead, narrowed gap at small batch sizes |
| Wake coalescing (atomic flag) | Reduced redundant wake syscalls from N to 1 in batch scenarios |
Completed Optimizations
-
Timer dispatch without per-pop locking: ✅ Done — Acquiretimer_muonce, pop all expired timers into a local list, release the lock, then fire them. Eliminates N lock/unlock cycles for N expired timers. -
Timer struct pooling: ✅ Done — Timer structs are recycled via a lock-free freelist (event_timer_alloc()/event_timer_free()), eliminatingmalloc/freeper timer. -
Wake coalescing for offload: ✅ Done — An atomicwake_pendingflag ensures only the first completing worker performs the actual wake syscall. Subsequent workers see the flag already set and skip the syscall entirely. -
Caller-allocated work items: ✅ Done — Work items are pooled via a lock-free Treiber stack (event_work_alloc()/event_work_free()), eliminating per-submit malloc. Equivalent to libuv's zero-alloc model. -
Lighter wake mechanism: ✅ Done — kqueue backend usesEVFILT_USER(zero fd, no pipe) for wake; epoll backend useseventfd(single fd) instead of a pipe pair. Poll backend retains the pipe as a POSIX fallback.
xTask Thread Pool — Benchmark Report
Micro-benchmark comparison of xTaskSubmit / xTaskWait throughput before and after the optimizations introduced in commit 8eaf7a0:
- xNote — Replace per-task
pthread_mutex_t+pthread_cond_t(88 bytes) with a 4-byte one-shot notification using atomic + futex/ulock. Fast path is a single atomic load. - TLS Freelist — Per-thread task struct freelist eliminates
malloc/freein the common submit-then-wait-on-same-thread path. - xMpsc Done-Queue — Replace mutex-protected done list with a lock-free MPSC queue so workers push completed tasks without contending on
qlock.
Historical note. The "TLS Freelist" referenced below was the first iteration of the allocation optimisation. It has since been replaced by the shared multi-threaded slab allocator (
xSlabMt, see slab.md), which removes the per-thread warm-up cost and handles cross-thread frees without falling back tomalloc. Updated numbers under the current implementation are in the Post-Slab Update section at the end of this document.
Test Environment
| Item | Value |
|---|---|
| CPU | Apple M3 Pro (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.4 (Darwin) |
| Compiler | Apple Clang 17.0.0 |
| Build | Release (-O2) |
| Framework | Google Benchmark (3 repetitions, aggregates only) |
| Workers | 4 threads (unless noted) |
Results
BM_Task_SubmitWait — Single-task round-trip
Submit one noop task and immediately wait. Measures the full overhead of allocation → enqueue → dispatch → completion → deallocation.
| Before | After | Δ | |
|---|---|---|---|
| Wall time | 5,803 ns | 5,694 ns | −1.9% |
| CPU time | 3,439 ns | 3,376 ns | −1.8% |
| Throughput | 290.8K ops/s | 296.2K ops/s | +1.9% |
Modest improvement — the single-task path is dominated by thread wake-up latency (qcond signal → worker dequeue), which is unchanged. The xNote fast path doesn't help here because the waiter arrives before the worker finishes.
BM_Task_FanOut — Batch submit + GroupWait
Submit N tasks, then xTaskGroupWait(). Measures batch throughput with barrier synchronization.
| Fan-out | Before (ops/s) | After (ops/s) | Δ Throughput |
|---|---|---|---|
| 10 | 786.9K | 912.4K | +16.0% |
| 100 | 2.12M | 2.91M | +37.3% |
| 1,000 | 2.69M | 3.55M | +31.6% |
| 10,000 | 3.06M | 3.76M | +23.2% |
| Fan-out | Before (wall) | After (wall) | Δ Latency |
|---|---|---|---|
| 10 | 16,440 ns | 15,531 ns | −5.5% |
| 100 | 55,090 ns | 48,339 ns | −12.3% |
| 1,000 | 398,729 ns | 336,559 ns | −15.6% |
| 10,000 | 3,485,962 ns | 2,977,391 ns | −14.6% |
Strong improvement across all fan-out widths. The lock-free xMpsc done-queue eliminates contention when workers push completed tasks concurrently. The xNote signal (atomic store + ulock wake) is cheaper than
pthread_cond_broadcast+ mutex lock/unlock.
BM_Task_SubmitWaitBatch — Submit N, then wait each
Submit N tasks, then xTaskWait() each individually. Exercises the TLS freelist (submit and wait on the same thread).
| Batch | Before (ops/s) | After (ops/s) | Δ Throughput |
|---|---|---|---|
| 10 | 852.2K | 944.4K | +10.8% |
| 100 | 2.20M | 2.38M | +8.4% |
| 1,000 | 2.59M | 3.53M | +36.2% |
| Batch | Before (wall) | After (wall) | Δ Latency |
|---|---|---|---|
| 10 | 14,713 ns | 13,635 ns | −7.3% |
| 100 | 51,536 ns | 48,809 ns | −5.3% |
| 1,000 | 416,378 ns | 315,694 ns | −24.2% |
The TLS freelist shines at batch=1000: zero malloc/free overhead when the same thread submits and waits. At smaller batches, the improvement is more modest because the freelist is already warm after the first iteration.
BM_Task_ConcurrentSubmit — Multi-producer contention
N producer threads each submit 1,000 tasks concurrently, then GroupWait.
| Producers | Before (wall) | After (wall) | Δ Wall Time |
|---|---|---|---|
| 1 | 439,085 ns | 348,531 ns | −20.6% |
| 2 | 776,911 ns | 611,341 ns | −21.3% |
| 4 | 1,022,938 ns | 1,110,056 ns | +8.5% |
| 8 | 1,291,049 ns | 2,197,253 ns | +70.2% |
Mixed results. At low producer counts (1–2), the lock-free done-queue reduces contention and improves wall time by ~21%. At higher producer counts (4–8), the wall time increases — this is because the xMpsc push uses a CAS loop that can spin under heavy contention from 8 producers, while the old mutex-based approach serializes cleanly. The task queue submission itself still uses
qlock, so the bottleneck shifts.
BM_Task_WorkerScaling — Throughput vs worker count
10,000 tasks with varying worker thread count.
| Workers | Before (ops/s) | After (ops/s) | Δ Throughput |
|---|---|---|---|
| 1 | 26.77M | 25.28M | −5.6% |
| 2 | 7.08M | 8.88M | +25.3% |
| 4 | 3.04M | 3.79M | +24.5% |
| 8 | 886.5K | 1.32M | +49.0% |
| Workers | Before (wall) | After (wall) | Δ Latency |
|---|---|---|---|
| 1 | 501,813 ns | 1,655,869 ns | +230% |
| 2 | 1,699,183 ns | 2,520,255 ns | +48.3% |
| 4 | 3,524,048 ns | 3,012,890 ns | −14.5% |
| 8 | 11,834,183 ns | 8,327,569 ns | −29.6% |
At 4+ workers, the optimized version is significantly faster. The lock-free done-queue eliminates the bottleneck where all workers contend on
qlockto append to the done list. At 8 workers, throughput improves by 49% and wall time drops by 30%. The 1-worker regression is noise — single-worker throughput is dominated by the serial dequeue path.
Summary
| Benchmark | Best Improvement | Key Optimization |
|---|---|---|
| SubmitWait (single) | +1.9% | xNote (marginal — dominated by wake latency) |
| FanOut (batch) | +37.3% (N=100) | xMpsc done-queue + xNote |
| SubmitWaitBatch | +36.2% (N=1000) | TLS freelist + xNote |
| ConcurrentSubmit | −21.3% wall (2 prod) | xMpsc done-queue |
| WorkerScaling | +49.0% (8 workers) | xMpsc done-queue |
Key Takeaways
-
xMpsc done-queue is the biggest win. Replacing the mutex-protected done list with a lock-free MPSC queue eliminates the main contention point when multiple workers complete tasks simultaneously. This shows up most dramatically in WorkerScaling/8 (+49%) and FanOut/100 (+37%).
-
TLS freelist eliminates allocation overhead. When the same thread submits and waits (the event-loop offload pattern), task structs are recycled from a per-thread freelist with zero locks. This is most visible in SubmitWaitBatch/1000 (+36%).
-
xNote is a structural improvement. While the raw latency improvement is modest for single-task round-trips, xNote reduces
struct xTask_from ~136 bytes to ~48 bytes (−65%), eliminatespthread_mutex_init/pthread_cond_init/destroycalls, and makes the fast path (task already done) a single atomic load. -
High-contention concurrent submit shows regression at 8 producers. The CAS-based xMpsc push can spin under extreme contention. This is a known trade-off — the lock-free path is faster for the common case (2–4 producers) but can degrade under pathological contention. Future work: consider work-stealing queues to eliminate the shared submission queue entirely.
libuv Baseline Comparison
Comparison against libuv 1.52.1's uv_queue_work API. libuv uses a global thread pool (default 4 workers) with pthread_cond_signal for precise wake-up. The libuv benchmarks use uv_run(UV_RUN_ONCE) to drive the event loop and collect completions.
Note on fairness: libuv's
uv_queue_workis tightly integrated with its event loop — the after_work_cb fires on the loop thread duringuv_run(), which avoids cross-thread synchronization for completion notification. xTask'sxTaskWait()blocks the calling thread with a futex/ulock, which is a different (and more general) synchronization model. The comparison measures end-to-end throughput of "submit work → collect result" regardless of the underlying mechanism.
SubmitWait — Single-task round-trip (xTask vs libuv)
| xTask | libuv | Δ | |
|---|---|---|---|
| Wall time | 5,702 ns | 5,878 ns | xTask −3.0% |
| Throughput | 293.5K ops/s | 289.0K ops/s | xTask +1.6% |
Essentially tied. Both are dominated by the same bottleneck: waking a sleeping worker thread via kernel syscall (ulock_wake / pthread_cond_signal).
FanOut — Batch submit + barrier (xTask vs libuv)
| Fan-out | xTask (ops/s) | libuv (ops/s) | Δ |
|---|---|---|---|
| 10 | 903.8K | 963.6K | libuv +6.6% |
| 100 | 2.86M | 3.18M | libuv +11.2% |
| 1,000 | 3.52M | 5.93M | libuv +68.5% |
| 10,000 | 3.72M | 5.81M | libuv +56.1% |
| Fan-out | xTask (wall) | libuv (wall) | Δ |
|---|---|---|---|
| 10 | 15,672 ns | 13,968 ns | libuv −10.9% |
| 100 | 48,985 ns | 36,804 ns | libuv −24.9% |
| 1,000 | 338,617 ns | 191,886 ns | libuv −43.4% |
| 10,000 | 3,017,059 ns | 1,963,693 ns | libuv −34.9% |
libuv is significantly faster at high fan-out. Key differences:
- Completion path: libuv workers post completions to an async handle (pipe/eventfd write), and the loop thread drains them in a single
uv__work_done()call — no per-task synchronization. xTask workers push to an xMpsc queue and signal xNote per task.- No per-task allocation: libuv's
uv_work_tis caller-allocated (stack or embedding struct), while xTask mallocs astruct xTask_per submit (mitigated by TLS freelist, but still present on first use).- Batch drain: libuv's
uv__work_done()drains all completed work in one loop iteration, amortizing the event-loop overhead. xTask'sxTaskGroupWait()spins onpendingwith a condvar.
SubmitWaitBatch — Submit N + wait each (xTask vs libuv)
| Batch | xTask (ops/s) | libuv (ops/s) | Δ |
|---|---|---|---|
| 10 | 860.8K | 968.8K | libuv +12.5% |
| 100 | 2.32M | 3.30M | libuv +42.4% |
| 1,000 | 3.46M | 4.51M | libuv +30.2% |
| Batch | xTask (wall) | libuv (wall) | Δ |
|---|---|---|---|
| 10 | 14,092 ns | 13,909 ns | libuv −1.3% |
| 100 | 49,749 ns | 35,792 ns | libuv −28.0% |
| 1,000 | 320,438 ns | 242,952 ns | libuv −24.2% |
Same pattern as FanOut. libuv's batch drain and zero-alloc model give it an edge at scale.
libuv Comparison Summary
| Benchmark | xTask vs libuv | Gap |
|---|---|---|
| SubmitWait (single) | ≈ tied | xTask +1.6% |
| FanOut/10 | libuv faster | −6.6% |
| FanOut/1000 | libuv faster | −68.5% |
| FanOut/10000 | libuv faster | −56.1% |
| SubmitWaitBatch/100 | libuv faster | −42.4% |
| SubmitWaitBatch/1000 | libuv faster | −30.2% |
Opportunities for Improvement
-
Batch drain in GroupWait: Instead of spinning on
pending+ condvar, drain the xMpsc done-queue in a batch (like libuv'suv__work_done()). This would amortize the per-task overhead of xNote signal + atomic decrement. -
Caller-allocated tasks: Allow an
xTaskSubmitInline(group, work_t*, fn)path where the caller provides the task struct (e.g. embedded in a larger request object), eliminating malloc entirely — matching libuv'suv_work_tmodel. -
Coalesced wake: When multiple tasks complete in rapid succession, coalesce the xNote signals into a single kernel wake (batch futex_wake / ulock_wake). Currently each worker signals independently.
Post-Slab Update (2026-05)
The original measurements above were taken when task struct allocation went through a per-thread TLS freelist layered on top of malloc. That freelist has since been replaced by the new shared xSlabMt allocator (see slab.md), which removes the "first use pays malloc" cost on every thread and makes cross-thread free paths allocator-aware.
Test Environment (Post-Slab)
| Item | Value |
|---|---|
| CPU | Apple Mac15,7 (12 cores) |
| Memory | 36 GB |
| OS | macOS 26.x (Darwin) |
| Compiler | Apple Clang (Xcode) |
| Build | Release (-O2) |
| Framework | Google Benchmark (3 repetitions, median, aggregates only) |
| Workers | 4 threads (unless noted) |
SubmitWait — Single-task round-trip (Post-Slab)
| Wall time | CPU time | Throughput | |
|---|---|---|---|
BM_Task_SubmitWait | 3,773 ns | 2,026 ns | 493.5 K ops/s |
Down from ~5,700 ns wall / 3,400 ns CPU — the xSlabMt alloc is materially cheaper than the prior freelist-on-malloc path, even for the single-task case where allocation is already warm. Throughput rises to ~494 K ops/s.
FanOut — Batch submit + GroupWait (Post-Slab)
| Fan-out | Wall (ns) | CPU (ns) | Throughput |
|---|---|---|---|
| 10 | 13,567 | 8,996 | 1.11 M ops/s |
| 100 | 39,208 | 20,925 | 4.78 M ops/s |
| 1,000 | 238,138 | 125,282 | 7.98 M ops/s |
| 10,000 | 2,331,742 | 1,383,197 | 7.23 M ops/s |
The large-batch throughput more than doubles versus the earlier measurement (3.76 M → 7.23 M ops/s at 10,000). xSlabMt lets both the submitting thread and the completing worker recycle task structs without ever touching malloc/free, removing the last per-task allocation from the batch path.
SubmitWaitBatch — Submit N + wait each (Post-Slab)
| Batch | Wall (ns) | CPU (ns) | Throughput |
|---|---|---|---|
| 10 | 12,216 | 9,216 | 1.09 M ops/s |
| 100 | 36,984 | 27,556 | 3.63 M ops/s |
| 1,000 | 250,484 | 194,483 | 5.14 M ops/s |
Comparable to the post-optimisation figures above; the submit-then-wait-on-same-thread path was already near-optimal with the TLS freelist, so the gain from xSlabMt is modest but positive.
ConcurrentSubmit — Multi-producer contention (Post-Slab)
| Producers | Wall (ns) | CPU (ns) | Throughput |
|---|---|---|---|
| 1 | 293,205 | 29,388 | 34.0 M ops/s |
| 2 | 571,184 | 44,812 | 44.6 M ops/s |
| 4 | 1,061,687 | 75,828 | 52.8 M ops/s |
| 8 | 2,325,239 | 238,690 | 33.5 M ops/s |
The 8-producer regression that existed with the TLS freelist is still visible — the bottleneck is no longer allocation but the shared task submission queue and the xSlabMt spinlock under eight contending threads (see the slab doc's multi-threaded benchmark for the raw contention curve). Work-stealing and caller-inline task structs remain the right follow-ups here.
WorkerScaling — Throughput vs worker count (Post-Slab)
| Workers | Wall (ns) | CPU (ns) | Throughput |
|---|---|---|---|
| 1 | 1,283,926 | 150,640 | 66.4 M ops/s |
| 2 | 1,863,470 | 454,054 | 22.0 M ops/s |
| 4 | 2,339,310 | 1,388,014 | 7.20 M ops/s |
| 8 | 5,037,388 | 4,252,296 | 2.35 M ops/s |
Single-worker throughput improves meaningfully (25 M → 66 M ops/s) — with only one worker there is no xMpsc contention and the allocation fast-path cost is what dominates, so the slab win shows through directly. At 4+ workers the done-queue CAS remains the bottleneck and the curve shape is unchanged from the prior run.
Key Takeaways (Post-Slab)
- Shared slab > per-thread freelist for cross-thread recycle. The old TLS freelist was great when the same thread submitted and waited, but any task freed by a worker on a different thread had to bounce back to
free(). xSlabMt removes that case entirely. - Single-task and single-worker paths are where the slab win shows clearest. In those scenarios there is no queue contention left, so allocator cost is front-and-centre.
- Under heavy contention, allocation is no longer the bottleneck. 8-producer / 8-worker workloads are limited by the shared queues, not by task struct acquisition. The next round of work should target those queues, not the allocator.
Design
A collection of architecture-level design documents that are not tied to any single module. These are methodology notes — reusable patterns, cross-cutting decisions, and design rationale that outlive any individual implementation.
Each document here states a problem shape, proposes a structure, and compares the structure against the common alternative of not doing it. They are intended to be readable on their own, without prior knowledge of moo internals.
Index
- Three-Layer Conversation Model — A way to carve systems that have "long-lived identity + multi-turn session + one-shot request" topology into three layers (Agent / Session / Query), and what it concretely buys you compared to the one-fat-object default.
- Context Budget —
How the Session layer keeps outgoing prompts under a token ceiling without
bleeding history ownership into Provider or Query. Covers the three-piece
split (estimator / EWMA calibrator / front-trimmer), the policy gate wiring,
and walks through the live numbers printed by
cli/. - Layered Memory — The four-layer memory / behaviour stack that sits on top of the three-layer conversation model: L1 immediate extraction, L2 long-term store & retrieval, L3 mood & vitality tracking, L4 proactive wake-up & scheduling. Covers the data flow, the per-layer protocols, the three-type session interaction model, and the MVP landing sequence.
三层会话模型:Agent / Session / Query
一种给 AI agent 系统重新切分层次的方法论——把"长期身份"、"一段对话"、"一次请求"明确拆成三个一等公民。
本文主要面向已经熟悉当代 AI agent 架构(Claude Code、LangChain Agent、ReAct、AutoGPT、MemGPT 等)的读者,讨论为什么这些架构在面对"类人 AI"的长期需求时会开始吃力,以及这个切法具体解决了什么。
TL;DR
当代 AI agent 架构几乎都围绕一次 query 的控制循环在做文章——while(!done) { llm_call(); tool_call(); }。这个循环很优雅,但它默认把"AI 是谁"、"这段对话从什么时候开始"、"这一次用户请求"三件事挤在同一个对象里(通常叫 Agent、AgentExecutor、ChatSession 等等,命名不同但形状类似)。
三层切法主张把这三件事拆成三个相互独立的对象:
| 层 | 生存期 | 承载 | 类比 |
|---|---|---|---|
| Agent | 跨进程、跨会话、持久化 | 身份、长期记忆、情绪基线、人格 | 一个"人" |
| Session | 一次对话从开始到结束 | 短期记忆、当前情绪状态、工具启用集 | 一次"见面" |
| Query | 一次 user turn 到 assistant 完成 | 消息、tool call loop、取消、usage | 一次"发问" |
graph TD A["Agent(身份层)<br/>长期记忆 · 人格 · 情绪基线"] -->|派生| S1["Session #1<br/>短期记忆 · mood"] A -->|派生| S2["Session #2<br/>短期记忆 · mood"] A -->|派生| S3["Session #3<br/>短期记忆 · mood"] S1 -->|发起| Q11["Query"] S1 -->|发起| Q12["Query"] S2 -->|发起| Q21["Query"] S3 -->|发起| Q31["Query"] S3 -->|发起| Q32["Query"] classDef agent fill:#FFE5B4,stroke:#E8A87C,color:#5D4037,stroke-width:2px classDef session fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px classDef query fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px class A agent class S1,S2,S3 session class Q11,Q12,Q21,Q31,Q32 query
这不是一个"更好的实现",是一个更好的切法。下文说明为什么要切,以及和当前业界主流架构的具体差异。
关于配图配色:全文所有架构图统一配色语义—— 🟡 杏黄 = Agent 层 / 持久身份; 🔵 淡蓝 = Session 层 / 会话态; 🟢 薄荷绿 = Query 层 / 请求执行; 🟣 淡紫 = 通用节点(User、LLM、Tools、Output 等外部实体); 🔴 樱花粉 = 反面例子 / 问题项。
看图只要记颜色,就能跨图对齐概念。
动机:为什么当前架构撑不起"类人 AI"
我们先把话题拉到动机,否则"为什么要拆三层"会显得没来由。
在另一篇讨论 类人 AI 的四个维度(分层记忆 / 情感连续性 / 选择性遗忘 / 主动唤醒)中,我们定义了一个判据:一个 AI 要像人,至少得同时满足四件事。
现在把这四件事反过来拷问当代 agent 架构:
- 分层记忆——记忆放哪?放
Agent.memory还是Session.history?当前大多数框架只给了一个 memory 对象,于是"这件事是我作为这个 AI 的长期积累,还是这次对话的临时上下文"永远混着。 - 情感连续性——mood 的生存期跟谁绑?如果跟单个 agent 实例绑,重启就没了;如果跟每条消息绑,跨对话就接不上。
- 选择性遗忘——要遗忘什么?短期对话内容?还是长期人格中的某些事实?这两种遗忘的代价完全不同,需要不同对象承担。
- 主动唤醒——谁来触发?"agent 自己想起一件事"和"这次对话里 AI 提出一个问题"不是同一回事,前者是 Agent 层行为,后者是 Session 层行为。
这四个需求都在要求架构暴露出一个比"一次请求"更粗、比"一个进程"更细的中间层——也就是 Session。没有这一层的架构,要么被迫把短期记忆和长期记忆挤在一起,要么把 mood 挂在错的生存期上。
当代 agent 架构的几种典型形态
为了说清楚差异,我们先把当前业界几种代表性架构的骨架画出来。
1. Claude Code:query-centric 架构
Claude Code 是目前开源实现里最完整的 coding agent 之一,核心是一个 query() AsyncGenerator:
graph LR U[User Input] --> Q["query(AsyncGenerator)"] Q --> S["State<br/>messages / tools / permissions"] S --> LLM[LLM Call] LLM --> RE["Response Engine<br/>Terminal | Continue"] RE -->|Continue| TOOLS[Tool Execution] TOOLS --> S RE -->|Terminal| OUT[Output] style Q fill:#FFE5B4,stroke:#E8A87C,color:#5D4037,stroke-width:2px style S fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style RE fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px style U fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px style LLM fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px style TOOLS fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px style OUT fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
特点:
- State 是一个扁平对象,messages / tools / permissions / todos 都在里面。
- 没有"会话"这个概念——一次
query()调用从开始到结束就是全部生命周期。 - 没有"身份"这个概念——AI 是谁由 system prompt + CLAUDE.md 等外部文件隐式组成,不是一等公民。
- 跨对话的状态(比如
/resume)通过把整个 messages 数组持久化来实现。
这种架构在一次性编程任务上非常好用——它的设计目标就是如此。但把它当作通用 agent 架构时,"AI 身份"和"对话实例"都是缺席的。
2. LangChain AgentExecutor:memory-as-plugin 架构
graph LR U[User] --> AE[AgentExecutor] AE --> MEM["Memory(可插拔)<br/>Buffer / Summary / Vector"] AE --> AGT[Agent LLM] AGT -->|action| TOOLS[Tools] TOOLS --> AGT AGT -->|final| OUT[Output] MEM -.读写.-> AGT style AE fill:#FFE5B4,stroke:#E8A87C,color:#5D4037,stroke-width:2px style MEM fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style AGT fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px style U fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px style TOOLS fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px style OUT fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
特点:
- Memory 是可插拔组件,有很多种实现(
ConversationBufferMemory、ConversationSummaryMemory、VectorStoreRetrieverMemory)。 - 但 Memory 的生存期跟谁绑没有统一答案——用户常常自己 new 一个 Memory 挂到 AgentExecutor 上,然后靠业务代码维护它和"某个用户的某次对话"的对应关系。
- "Agent 是谁"和"这次对话"的边界由使用者自己划,框架不管。
结果:长期记忆、短期记忆、mood 怎么分、怎么持久化,完全是使用者的作业。框架给了 Memory 插槽,但没给"把什么插在什么生存期上"的答案。
3. ReAct / AutoGPT:goal-driven 循环
graph TD
G[Goal] --> L{ReAct Loop}
L --> THINK[Thought]
THINK --> ACT[Action]
ACT --> OBS[Observation]
OBS --> L
L -->|Done| R[Result]
style L fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px
style G fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
style THINK fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
style ACT fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
style OBS fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
style R fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
特点:
- 核心是 Thought → Action → Observation 循环,为完成一个 goal 服务。
- 没有对话概念——一次运行就是一个任务实例。
- 长期记忆通常通过外挂向量库实现,但"AI 跨任务的自我"基本不存在。
这个范式把 agent 当任务执行器而不是对话对象——很多场景够用,但做不了"类人 AI"。
4. MemGPT / Letta:memory-first 架构
MemGPT 走向了另一个极端——把记忆提升到一等公民:
graph LR AG["Agent(持久)"] --> CORE[Core Memory<br/>人格 · 用户画像] AG --> ARCH[Archival Memory<br/>向量库] AG --> RECALL[Recall Memory<br/>消息历史] U[User] -->|message| AG AG --> LLM[LLM] LLM -->|memory tool| CORE LLM -->|memory tool| ARCH style AG fill:#FFE5B4,stroke:#E8A87C,color:#5D4037,stroke-width:2px style CORE fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style ARCH fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style RECALL fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style U fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px style LLM fill:#F3E5F5,stroke:#CE93D8,color:#4A148C,stroke-width:2px
特点:
- Agent 是一等公民,而且是持久化的——这比 Claude Code 和 LangChain 都进了一步。
- Core / Archival / Recall 三种 memory 让记忆分层了。
- 但仍然没有 Session 这一层——多次对话和一次对话在数据模型上没有边界,都是 recall memory 里的连续消息流。
- 于是"这次见面从什么时候开始到什么时候结束"、"这段短期上下文要不要写进长期记忆"这类决策,没有一个具体对象来承载。
小结
| 架构 | 身份层 | 会话层 | 请求层 |
|---|---|---|---|
| Claude Code | ✗(外部文件) | ✗ | ✓(query) |
| LangChain | 部分(prompt) | 部分(Memory) | ✓(run) |
| ReAct / AutoGPT | ✗ | ✗ | ✓(loop) |
| MemGPT / Letta | ✓ | ✗ | ✓ |
| 三层切法 | ✓ | ✓ | ✓ |
Session 是几乎所有当代架构都缺的一层——这正是本文要补上的。
三层切法:定义和边界
Agent:身份层
Agent 是一个有持久身份的实体。它的生存期是"从被创造出来到被销毁",跨越任意次进程重启。
承载的内容:
- 谁:名字、角色、system prompt、人格设定
- 长期记忆:经年累月积累下来的事实、经验、偏好
- 情绪基线:这个 AI 的"性格倾向"——容易开心?容易焦虑?
- 能力目录:它能用哪些 tool、连接哪些 provider
Agent 不直接处理请求。当一个对话要发生时,它派生出一个 Session。
Session:会话层
Session 是一次有明确开始和结束的对话实例。它的生存期从"开始聊"到"结束聊",短则几分钟,长则几小时。
承载的内容:
- 短期记忆:这次对话的上下文——最近说过什么、共同约定了什么
- 当前情绪状态:mood 在这次对话里的演化(被骂了会沮丧,得到感谢会愉悦)
- 工具启用集:这次对话能用哪些工具(可以是 Agent 能力目录的子集)
- 对话元数据:开始时间、对方是谁、所在设备/环境
Session 结束时有一个关键时刻:决定短期记忆里的哪些内容要沉淀到 Agent 的长期记忆里——这就是选择性遗忘的绑定点。
Query:请求层
Query 是一次 user turn 到 assistant 完成的过程。它的生存期从"用户发来一条消息"到"AI 完成所有回复和 tool call"。
承载的内容:
- 这次的消息对:user message + assistant reply(可能穿插若干 tool call)
- tool call loop:ReAct 风格的 think→act→observe 在这里发生
- 取消作用域:用户按 Ctrl+C 取消的是这一次 Query,不影响 Session 或 Agent
- usage / token 统计:这一次的 token 开销
Query 是无状态的——它只借用 Session 的短期记忆和 Agent 的长期记忆,自己不存任何跨 Query 的东西。
三层的时序
sequenceDiagram actor U as User participant A as Agent participant S as Session participant Q as Query participant LLM Note over A: 进程启动,Agent 从存储加载身份与长期记忆 U->>A: 开始聊天 A->>S: 派生 Session(注入身份 + 长期记忆引用) U->>S: "帮我看看这段代码" S->>Q: 创建 Query 1 Q->>LLM: prompt = identity + long_mem + short_mem + user_msg LLM-->>Q: assistant + tool_call Q->>Q: 执行 tool call loop Q-->>S: 完成,返回 reply S->>S: 更新短期记忆 + mood U->>S: "那这里能不能优化" S->>Q: 创建 Query 2 Q->>LLM: prompt = ...(复用同一个 Session 的短期记忆) LLM-->>Q: assistant Q-->>S: 完成 S->>S: 更新短期记忆 + mood U->>S: 结束对话 S->>A: 结束前做记忆沉淀(哪些写入长期记忆) A->>A: 更新长期记忆 + 情绪基线 Note over A: Session 销毁,Agent 继续存在
几个关键观察:
- Query 只和 Session 交互,不直接碰 Agent——这是封装。
- Session 结束时有一个固定的"沉淀时刻",这是短期记忆变长期记忆的唯一入口。
- Agent 跨 Session 持久——下一次聊天的 Session 能看到上一次沉淀进来的内容。
对比:和当代架构的具体差异
这一节是全文要点。我们取四个具体维度,说明三层切法和前面四种架构的本质区别。
差异 1:记忆的归属
| 架构 | 短期记忆 | 长期记忆 | 跨对话连续性 |
|---|---|---|---|
| Claude Code | state.messages | 外部文件(CLAUDE.md 等) | /resume 加载旧 messages |
| LangChain | Memory 对象 | Memory 对象(可能另一个) | 使用者自己维护 |
| ReAct | 循环内部 | 不存在 | 不存在 |
| MemGPT | Recall memory | Core + Archival | Recall 连续流 |
| 三层切法 | Session 内部 | Agent 内部 | Session 结束时的沉淀步骤 |
关键差异:三层切法是唯一明确把"短期→长期"的转换定为架构事件的。在 MemGPT 里,短期和长期的边界是"消息在 recall 里被压缩/搬到 archival 的时机"——但这个时机不对应任何真实的人类概念。而 Session 结束这件事对应人类经验里"这次聊天结束了,让我想想有什么值得记住的",是一个更自然的切入点。
差异 2:情绪的生存期
graph TB
subgraph "当代架构(mood 无处安放)"
direction LR
C1[每条消息<br/>存 mood?] -.too granular.-> C2[每次 query<br/>存 mood?] -.cross-query 丢失.-> C3[Agent 对象<br/>存 mood?] -.跨对话就错了.-> C1
end
subgraph "三层切法"
direction LR
T1[Agent: 情绪基线<br/>人格中的倾向]
T2[Session: 当前 mood<br/>对话内演化]
T3[Query: 不存 mood<br/>借用 Session]
T1 -->|派生初值| T2
T2 -.|Session 结束时<br/>可能微调基线|.-> T1
end
style C1 fill:#F8C8C8,stroke:#E88B8B,color:#7B2828,stroke-width:2px
style C2 fill:#F8C8C8,stroke:#E88B8B,color:#7B2828,stroke-width:2px
style C3 fill:#F8C8C8,stroke:#E88B8B,color:#7B2828,stroke-width:2px
style T1 fill:#FFE5B4,stroke:#E8A87C,color:#5D4037,stroke-width:2px
style T2 fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px
style T3 fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px
mood 天然是"一段对话内的事"——它比一次 query 长,比一个 agent 的一生短。没有 Session 这一层,mood 只能要么挂错要么丢失。
差异 3:并发的表达
假设一个 agent 同时和三个用户聊天。
Claude Code 做法:跑三个进程或三个 query() 实例,各有各的 state——身份/记忆靠读同一份外部文件做到"共享",但实际上是拷贝。
LangChain 做法:三个 AgentExecutor 实例,各自挂各自的 Memory。"这三个 AI 其实是同一个 AI"这件事框架不感知。
MemGPT 做法:三个 Agent 实例,或一个 Agent 处理 session_id 不同的消息流。如果选后者,那 recall memory 就必须按 session_id 分区——但 MemGPT 里 session 不是一等公民,这个分区得使用者自己拼。
三层切法做法:
graph TB A["Agent(单例)<br/>长期记忆只有一份"] S1["Session(Alice)"] S2["Session(Bob)"] S3["Session(Charlie)"] A --> S1 A --> S2 A --> S3 S1 --> Q1["Query 进行中"] S2 --> Q2["Query 进行中"] S3 --> Q3["Query 进行中"] style A fill:#FFE5B4,stroke:#E8A87C,color:#5D4037,stroke-width:2px style S1 fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style S2 fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style S3 fill:#B5D8F0,stroke:#7FB3D5,color:#1B4965,stroke-width:2px style Q1 fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px style Q2 fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px style Q3 fill:#C8E6C9,stroke:#81C784,color:#1B5E20,stroke-width:2px
Agent 在架构层面就是共享的——三个 Session 读同一份长期记忆,写入时通过 Session 结束的沉淀步骤串行化。mood 因为挂在 Session 上,天然对三个用户独立。Query 因为挂在 Session 上,取消一个不影响另一个。
差异 4:取消的作用域
stateDiagram-v2 [*] --> QueryRunning : 用户发消息 QueryRunning --> QueryCancelled : Ctrl+C QueryRunning --> QueryDone : LLM 完成 QueryCancelled --> SessionIdle : 丢弃这次请求 QueryDone --> SessionIdle : 更新短期记忆 SessionIdle --> QueryRunning : 下一条消息 SessionIdle --> SessionClosing : 用户结束对话 SessionClosing --> [*] : 沉淀到 Agent
三层架构下"取消"有非常清晰的语义:取消一次 Query不影响 Session(下一次还能聊),关闭 Session不影响 Agent(下一次对话还能找回身份),销毁 Agent才是真的 bye bye。
当代 agent 架构普遍做不到这一点——因为它们没区分这三层。取消一个 Claude Code 的 query 意味着什么?技术上是 cancel 那个 AsyncGenerator,但"这次 query 之前积累的短期上下文要不要留下"框架不置可否,由使用者自己处理。
这个切法解锁了什么
说了这么多差异,具体能干什么?
解锁 1:自然的记忆沉淀点
Session 结束就是记忆沉淀的天然时机。这比 MemGPT 的"在 recall memory 里用 tool 主动搬运"更省 token,也比 LangChain 的"使用者自己写一个 callback"更标准化。
解锁 2:可预测的情绪演化
mood 挂在 Session 上——对话内演化,对话结束时可能对 Agent 基线产生微小影响。这一模型非常贴近人类经验:一次糟糕的聊天会让你记仇几天,但不会永久改变你的性格。
解锁 3:多人格/多会话的并发
一个 Agent 可以同时维护多个 Session,而且它们在架构上就是隔离的——不需要使用者额外用 session_id 做分区。这对 server-side 的 agent-as-a-service 场景是刚需。
解锁 4:清晰的测试边界
- 测 Query 层——不需要 Session,mock 一个就行
- 测 Session 层——不需要 Agent,mock 一个就行
- 测 Agent 层——甚至不需要真实 LLM,只测长期记忆的读写
解锁 5:主动唤醒的落点
类人 AI 的第四个维度(主动唤醒)是"AI 自己想起一件事来说"——触发者不是 user,而是 AI 自己。这是四个维度里最难落地的一个,因为它直接挑战了当代所有 agent 架构的底层前提:一切对话都从 user 消息开始。
关键观察:主动唤醒不是一种行为,是两种。混为一谈是所有已有架构的共同错误。
形态 A:Agent 层唤醒(跨会话)
触发源是时间 / 外部事件 / 后台反刍。AI 突然想起和某个 user 上周聊过但没结论的事,主动找他开口。
sequenceDiagram autonumber participant Timer as ⏰ 定时器/事件源 participant A as 🟡 Agent (AI 本体) participant LTM as 🧠 长期记忆 participant S as 🔵 Session (对某 user) participant U as 👤 User Note over A: 空闲循环/后台反刍<br/>(不绑定任何 session) Timer->>A: 心跳 / 外部事件 / 定时器 A->>LTM: 扫描未完结话题 / 记忆关联 LTM-->>A: 命中:"上周和 Alice 聊的 X 还没结论" A->>A: 决策:要不要真的开口?<br/>(频率限制 / mood / 场合) A->>S: 创建 Session (或复用活跃 session) A->>S: 注入"主动消息" Query S->>U: 发送 assistant 消息 "对了,关于 X..." U->>S: 用户回复 Note over A,S: 回到常规对话节奏
关键点:
- 触发器在 Agent 层——
while (true) { sleep; check_memory; maybe_speak; }这类 dormant loop 必须是 Agent 的一部分,不能挂在任何 Session 下。 - 对话渠道由 Agent 主动创建或复用 Session——这意味着 Session 不能是"user 来了才创建"的被动资源。
- "要不要开口"的决策需要访问跨 Session 的历史——只有 Agent 层持有这个视角。
形态 B:Session 层唤醒(会话内)
触发源是当前对话里的信息不足。AI 读完 user 消息,觉得不澄清就没法答,在开始正式回答前先主动抛一个问题。
sequenceDiagram autonumber participant U as 👤 User participant S as 🔵 Session participant Q1 as 🟢 Query N (user turn) participant Q2 as 🟢 Query N+0.5 (clarify turn) participant LLM as 🤖 LLM U->>S: "帮我订一张票" S->>Q1: 开始 Query N Q1->>LLM: 推理 + tool call LLM-->>Q1: signal="need_clarification"<br/>(意图不全) Q1->>S: Query 提前终止 (non-fatal) Note over S: Session 决策:<br/>不推给 user 半成品,<br/>改主动问一句 S->>Q2: 创建 clarify Query<br/>(assistant-initiated) Q2->>U: "订哪天的?从哪里到哪里?" U->>S: "明天早上,北京到上海" Note over S: 补齐槽位,回到主流程 S->>Q1: 重启原 Query (带澄清信息)
关键点:
- 触发器在 Session 层——是 Session 对"上一个 Query 结果不完整"的反应策略。
- 不需要创建新 Session,也不需要访问跨会话记忆。
- Query N+0.5 是 assistant-initiated 的——messages 数组里多一条 assistant 消息,但它不是对某条 user message 的回复。
两种形态必须区分
| 维度 | 形态 A(Agent 层) | 形态 B(Session 层) |
|---|---|---|
| 触发源 | 时间 / 外部事件 / 后台反刍 | 当前 Query 的结果不完整 |
| 触发频率 | 小时 / 天 级别 | 毫秒 / 秒级 |
| 所需视角 | 跨所有 Session 的长期记忆 | 当前 Session 的上下文 |
| 是否新建 Session | 可能需要(如果没有活跃 session) | 不需要 |
| 失败代价 | 打扰 user,mood 要保守 | 多一轮对话,代价低 |
| 实现位置 | Agent 的 dormant loop | Session 的 query scheduler |
混为一谈的后果很具体:
- 把形态 A 塞进 Session——Session 被迫背一个"后台定时器",违反 Session 应该是 user 驱动的半被动资源的设定;多 Session 并发时每个 Session 都跑自己的 timer,语义乱。
- 把形态 B 塞进 Agent——每次需要澄清都要惊动 Agent 层(跨 session 的重决策),延迟飙升,而且 Agent 没有 Session 的即时上下文,决策质量还更差。
- 完全不区分(当代多数架构的现状)——主动唤醒这个维度落不了地,因为你不知道把 dormant loop 挂在哪里,也不知道它能访问什么状态。
为什么三层是主动唤醒的必要条件
没有 Agent 层 → 无处挂载"跨 session 的后台反刍" 没有 Session 层 → 无处表达"澄清轮"和"原始轮"的关系 没有 Query 层 → 无法区分"user-initiated"和"assistant-initiated"的消息来源
主动唤醒不是功能,是一个架构判据:一个 agent 架构如果不能优雅地表达这两种形态,它就不可能真的像人。Claude Code(只有 Query+State)、LangChain(memory 不是一等公民)、ReAct(连 Session 都没有)、MemGPT(有 Agent 没 Session)——都只能实现其中一种,或者都实现得很扭曲。
三层切法给主动唤醒留了两个明确的落点——Agent 的 dormant loop 和 Session 的 mid-turn clarifier——这才是这个维度能落地的前提。
什么时候不该这样切
这个切法不是万能的——当以下条件之一成立时,它带来的复杂度不划算:
- 一次性任务。如果你的 agent 就是"跑一个 goal 然后退出",Claude Code 和 AutoGPT 的 query-centric / loop 架构更简单。
- 无状态 API。如果你的 agent 是无状态的问答 API,连 Session 都不需要。
- demo / POC。验证概念阶段别过度设计,LangChain 的 Memory 插槽够用。
三层切法的成本是多出两层对象和两次状态转换(Agent→Session→Query),收益是"类人 AI"所需的全部非功能性属性(记忆分层、情绪连续、取消作用域、并发隔离)都有了自然归宿。你得先确认收益大于成本。
常见误区
- "Session 就是 message list"——不对。Session 承载的是一次对话的完整状态,包括 mood、工具启用集、元数据。message list 只是它的一部分。
- "Agent 就是 system prompt"——不对。system prompt 是身份的投影,Agent 还包括长期记忆、情绪基线、能力目录这些不会直接出现在 prompt 里的东西。
- "Query 就是一次 LLM 调用"——不对。一次 Query 里可能有若干次 LLM 调用(tool call loop),但对外只是一次请求。
- "分三层就是写三个 class"——不完全对。三层是概念上的边界,实现上可以是三个对象、也可以是带 scope 标记的一个对象。重点是让"这件事归谁"在代码里有一个清晰的答案。
和 Actor 模型的关系
熟悉 Actor 的读者会发现,Agent 层非常像 Actor——有身份、有邮箱、可并发。但 Actor 模型没有原生的 Session 概念——多个 message 组成一次对话这件事是使用者自己在 Actor 内部状态里维护的。
可以这样理解:三层切法是在 Actor 的基础上,把"一段对话"提升成一等公民。底层完全可以用 Actor 实现。
最小实现指南
如果要在一门静态语言(比如 C、Go、Rust)里落地这个切法,大致有几条准则:
- 三个显式类型:
Agent、Session、Query,带各自的创建/销毁函数。 - 生存期约束:Session 持有 Agent 的引用;Query 持有 Session 的引用;反向引用通过事件/回调。
- 状态归属清单:写一张表,把每个状态字段归到一层(这张表就是你的架构契约)。
- 三个明确的转换点:Agent→Session(开始对话)、Session→Query(收到消息)、Session→Agent(记忆沉淀)。每个转换点暴露一个 hook 给使用者。
- 取消的层次化传播:cancel query 不 cancel session;close session 不 destroy agent。
附:在 moo 中的落地
moo 的 xagent 模块大体就是按这个切法做的:
xAgent承担 Agent 层——身份、长期记忆(计划中)、能力目录(tool 注册表)。xAgentSession承担 Session 层——message history、streaming 回调、cancel 作用域。- 单次
xAgentSessionSend的执行过程对应 Query 层——虽然没有独立的xAgentQuery类型(用运行中的内部状态表达),但它的生存期和取消作用域就是 Query 层概念。
这个映射不是本文想展开的重点——真正的重点是方法论本身。具体实现细节见 xagent 架构文档。
参考
- 类人 AI 的四个维度
- Claude Code 架构分析(Anthropic 开源实现,query-centric 范式的代表作)
- MemGPT: Towards LLMs as Operating Systems(Packer et al., 2023)
- LangChain Agent 文档(memory-as-plugin 范式)
- ReAct: Synergizing Reasoning and Acting in Language Models(Yao et al., 2022)
TODO
Planning and feasibility analysis for future improvements.
- Remove libcurl Dependency — Feasibility, benefits, and trade-offs of removing xhttp's dependency on libcurl
- xTaskGroup Work-Stealing — Migrating xTaskGroup's task queue from a single-lock design to a work-stealing architecture
- NAT4 Birthday Attack Traversal — Feasibility analysis of using birthday attack for port prediction to traverse symmetric NAT (NAT4)
- ICE Nomination Strategy — Optimize nomination timing to reduce connection establishment latency, with comparison to libwebrtc
- Human-like AI (xagent roadmap) — Long-term product direction for the xagent module: layered memory, mood continuity, selective forgetting, proactive recall
- xagent Architecture (Agent/Session/Query) — Three-layer architecture design & execution plan: Session/Query split (near-term) + Agent layer (future)
移除 libcurl 依赖的可行性与收益分析
一、当前 libcurl 的使用范围
libcurl 仅被 HTTP Client 部分使用,涉及以下文件:
| 文件 | 依赖程度 | 说明 |
|---|---|---|
client.c | 核心 | 整个文件围绕 curl_multi / curl_easy 构建 |
client.h | API 层 | xHttpResponse 暴露了 curl_code / curl_error |
client_private.h | 核心 | CURL *easy、CURLM *multi、CURLcode、CURL_ERROR_SIZE |
sse.c | 核心 | SSE 流式传输完全基于 curl write callback |
xhttp/CMakeLists.txt | 构建 | Libcurl::Libcurl 链接 |
CMakeLists.txt (顶层) | 构建 | 整个 xhttp 模块的编译以 Libcurl_FOUND 为前提 |
不依赖 curl 的部分(占 xhttp 模块的大部分):
- HTTP Server(
server.c、proto_h1.c、proto_h2.c)→ 用 llhttp + nghttp2 - WebSocket Server(
ws.c、ws_serve.c、ws_handshake_server.c) - WebSocket Client(
ws_connect.c、ws_handshake_client.c)→ 纯 socket + xEventLoop - Transport 层(
transport_*.c)→ 纯 OpenSSL / mbedTLS - WS Frame / Deflate / Crypto
二、libcurl 提供了什么
libcurl 在 xhttp client 中承担了以下职责:
graph TD
A[libcurl 提供的能力] --> B[HTTP/1.1 协议解析<br/>请求序列化 + 响应解析]
A --> C[HTTP/2 协议支持<br/>HPACK, 流复用, 帧处理]
A --> D[TLS 握手管理<br/>证书验证, ALPN 协商]
A --> E[Multi-Socket API<br/>非阻塞 I/O 集成]
A --> F[连接池 / Keep-Alive<br/>DNS 缓存]
A --> G[Chunked Transfer<br/>Content-Encoding 解压]
A --> H[重定向跟随<br/>Cookie 管理]
A --> I[代理支持<br/>SOCKS / HTTP proxy]
三、替换方案分析
如果移除 libcurl,需要自己实现 HTTP Client 协议栈:
| 需要自建的组件 | 复杂度 | 说明 |
|---|---|---|
| HTTP/1.1 请求序列化 | ⭐ 低 | 手动拼 GET /path HTTP/1.1\r\n... |
| HTTP/1.1 响应解析 | ⭐⭐ 中 | 可复用已有的 llhttp(server 已在用) |
| Chunked Transfer Decoding | ⭐⭐ 中 | llhttp 可处理 |
| TLS 客户端握手 | ⭐⭐ 中 | WS Client 已有 transport_tls_client_openssl/mbedtls,可复用 |
| HTTP/2 客户端 | ⭐⭐⭐⭐ 高 | 需要 nghttp2 的 client session API(server 已用 nghttp2,但 client 模式不同) |
| 连接池 / Keep-Alive | ⭐⭐⭐ 高 | 需要自己管理连接复用、idle timeout |
| Multi-Socket 事件集成 | ⭐⭐ 中 | 已有 xEventLoop,但需要自己管理连接状态机 |
| DNS 异步解析 | ⭐⭐⭐ 高 | curl 内置 c-ares 集成,自建需要额外依赖或阻塞 |
| 重定向 / Cookie / Proxy | ⭐⭐ 中 | 按需实现 |
四、收益分析
✅ 收益
-
减少外部依赖
- 当前 xhttp 模块需要 libcurl(~600KB 动态库),移除后减少一个系统级依赖
- 嵌入式 / 交叉编译场景更友好(libcurl 的交叉编译配置较复杂)
-
统一 TLS 管理
- 目前 HTTP Client 的 TLS 由 curl 内部管理(
CURLOPT_CAINFO等),与 xnet/xhttp 其他部分的xTlsCtx体系割裂 - 移除后可统一使用
xTlsCtx共享模式,与 TCP/WS Client/HTTP Server 一致
- 目前 HTTP Client 的 TLS 由 curl 内部管理(
-
消除 API 泄漏
xHttpResponse中的curl_code/curl_error是 curl 特有概念,暴露给用户不够抽象- 移除后可用
xErrno统一错误体系
-
减小二进制体积
- 对于只用 server 或 WS 的场景,不再需要链接 curl
-
更精细的控制
- 连接池策略、超时行为、buffer 管理等可以完全自定义
❌ 代价
-
工作量巨大(估算 2000-3000 行新代码)
- HTTP/1.1 Client 协议栈:~500 行
- HTTP/2 Client(nghttp2 client session):~800 行
- 连接池 + Keep-Alive 管理:~500 行
- SSE 重新集成:~300 行
- DNS 解析:~200 行(或引入 c-ares)
- 测试重写:~500 行
-
HTTP/2 Client 是最大难点
- nghttp2 的 client API 与 server API 差异大,需要处理 SETTINGS、WINDOW_UPDATE、流优先级等
- curl 内部对 nghttp2 client 做了大量边界处理
-
失去 curl 的成熟度
- libcurl 经过 25+ 年打磨,处理了无数 HTTP 边界情况(畸形响应、各种 Transfer-Encoding、代理认证等)
- 自建实现短期内很难达到同等健壮性
-
维护负担增加
- HTTP 协议的 edge case 很多,自建意味着长期维护成本
五、折中方案
如果目标是减少依赖但不完全重写,有几个渐进路径:
graph LR
A[当前状态<br/>curl 必选] --> B[方案1: curl 可选<br/>有 curl 用 curl<br/>无 curl 用内置 H1]
A --> C[方案2: 仅移除 H2 Client<br/>内置 H1 Client<br/>H2 仍用 curl]
A --> D[方案3: 完全移除<br/>内置 H1 + H2 Client]
B --> E[工作量: ~800行<br/>风险: 低]
C --> F[工作量: ~600行<br/>风险: 低]
D --> G[工作量: ~2500行<br/>风险: 高]
推荐方案1:让 curl 变为可选依赖
- 新增一个轻量的内置 HTTP/1.1 Client(基于已有的 llhttp +
transport_tls_client+ xEventLoop) - 有 curl 时用 curl(支持 H2、连接池等高级特性)
- 无 curl 时 fallback 到内置 H1 Client(覆盖 80% 的使用场景)
- HTTP Server、WS Server/Client 完全不受影响(它们本来就不依赖 curl)
这样可以:
- 让 xhttp 模块在无 curl 环境下也能编译(server + ws + 基础 client)
- 保留 curl 作为增强选项(H2 client、连接池、代理等)
- 统一 TLS 管理(内置 client 用
xTlsCtx) - 逐步迁移,风险可控
六、结论
| 维度 | 完全移除 | 可选依赖(推荐) |
|---|---|---|
| 工作量 | ~2500 行 + 测试重写 | ~800 行 |
| 风险 | 高(H2 client 复杂) | 低(H1 only,复用现有组件) |
| 收益 | 零外部依赖 | 无 curl 也能用,有 curl 更强 |
| API 变化 | 需要重新设计 Response | 可以抽象一层,渐进迁移 |
| 时间 | 2-3 周 | 3-5 天 |
建议:先做方案1(curl 可选),把 HTTP Server / WS 从 curl 依赖中解耦出来(实际上它们已经解耦了,只是 CMake 层面整个 xhttp 模块被 curl 门控了)。然后再根据实际需求决定是否进一步移除 curl。
xbase — TODO
Planned optimizations and additions to the xbase module. Items are listed roughly in priority order.
xTaskGroup — Work-Stealing Thread Pool
Problem
The current xTaskGroup uses a single shared task queue protected by pthread_mutex_t (qlock). All workers contend on this lock when dequeuing tasks, and all submitters contend on it when enqueuing. Under high task throughput with many worker threads, qlock becomes a scalability bottleneck.
The lock cannot be replaced with xMpsc because the task queue is MPMC (multiple producers, multiple consumers), while xMpsc only supports single-consumer access.
Proposed Solution — Work-Stealing
Each worker thread owns a local task deque (double-ended queue). Submitters distribute tasks to worker deques via round-robin or least-loaded selection. Workers pop from their own deque (LIFO, cache-friendly); when a worker's deque is empty, it steals from another worker's deque (FIFO, fairness).
Submitter ──round-robin──▶ Worker 0 deque ◀──steal── Worker 1
Worker 1 deque ◀──steal── Worker 2
Worker 2 deque ◀──steal── Worker 0
Key Design Points
| Aspect | Detail |
|---|---|
| Local deque | Chase-Lev work-stealing deque — lock-free for owner push/pop, CAS-based for stealer |
| Task distribution | Round-robin with atomic_fetch_add on a shared counter |
| Steal policy | Random victim selection to avoid thundering herd |
| Idle wait | Per-worker xNote or eventfd; submitter signals the target worker |
| Fallback | If all deques are full, fall back to a shared overflow queue (current qlock-based queue) |
Benefits
- Eliminates the single
qlockbottleneck — workers rarely contend with each other - LIFO local execution improves cache locality (recently submitted tasks are hot)
- Stealing provides automatic load balancing without centralized scheduling
Complexity
High. Requires a correct Chase-Lev deque implementation with careful memory ordering, plus steal-half vs steal-one policy tuning. Recommended as a future optimization when profiling shows qlock contention is a real bottleneck.
Priority
P2 — The current single-queue design is adequate for typical workloads (event-loop offload with moderate worker counts). The TLS freelist and xNote-based completion already address the main hot paths. Revisit when benchmarks show lock contention under high core counts (≥32 threads).
xp2p — TODO
Analysis and feasibility study for NAT4 (Symmetric NAT) traversal via birthday attack port prediction.
Symmetric NAT Traversal — Birthday Attack
Background
RFC 3489 classifies NAT4 as Symmetric NAT: each (src_ip, src_port, dst_ip, dst_port) tuple maps to a different external port. This means the srflx candidate obtained via STUN (XOR-MAPPED-ADDRESS) has a port that differs from the port the NAT assigns when the peer sends to a different destination. Standard ICE srflx candidates are therefore ineffective under Symmetric NAT.
The current ICE agent falls back to TURN relay for Symmetric NAT scenarios, which always works but adds relay-hop latency. A birthday attack approach could potentially establish a direct path before resorting to TURN.
Birthday Attack Principle
When both peers are behind Symmetric NATs:
- Peer A opens
Nlocal UDP sockets and sends from each to B's STUN-reflected address - Peer B opens
Mlocal UDP sockets and sends from each to A's STUN-reflected address - A's NAT creates
Ndistinct external port mappings; B's NAT createsMdistinct mappings - If any of A's external ports matches the port B is targeting (or vice versa), the packet traverses the NAT → connection established
This exploits the birthday paradox: in a port space of P ≈ 64512 (excluding well-known ports), opening n ports per side yields:
$$P(\text{collision}) \approx 1 - e^{-n^2 / P}$$
| Ports per side (n) | Collision probability |
|---|---|
| 128 | ~22% |
| 256 | ~63% |
| 512 | ~98% |
| 1024 | ~99.99% |
Practical Constraints
NAT Port Allocation Is Not Always Random
Many Symmetric NATs use sequential port allocation rather than random. In this case:
- The birthday attack's random-collision assumption breaks down
- A port prediction strategy works better: send two STUN requests, observe the port delta
Δ, predict the next port aslast_port + Δ - The current
send_stun_binding_for_hostsends only one STUN request per host candidate, so port deltas cannot be observed
Resource Overhead
Each side needs 256–512 bound UDP sockets sending simultaneously:
XICE_MAX_CANDIDATESis currently 32 — far too smallXICE_MAX_PAIRSwould explode toN × M- Each socket must be registered with the event loop, increasing memory and fd usage
NAT Mapping TTL
NAT mappings typically expire in 30–120 seconds. All probes must complete within this window. With the current check_pacing_cb at ~50 ms per pair, 256 pairs take 12.8 s (acceptable), but 512 pairs take 25.6 s (tight).
CGNAT Makes It Harder
Modern mobile networks use Carrier-Grade NAT (CGNAT) with larger port spaces and more complex allocation policies, reducing birthday attack success rates.
Approach Comparison
| Approach | Applicable scenario | Success rate | Complexity |
|---|---|---|---|
| Standard ICE (srflx) | NAT1/2/3 | High | Low (already implemented) |
| TURN relay | All NAT types | 100% | Low (already implemented) |
| Birthday attack | Both sides Symmetric NAT | ~60–98% | High |
| Port prediction (sequential NAT) | Sequential-allocation Symmetric NAT | ~70–90% | Medium |
Implementation Plan (If Pursued)
- Port delta detection — During gathering, send two STUN Binding Requests from each host candidate to observe the NAT's port allocation delta
- Expand candidate limits — Increase
XICE_MAX_CANDIDATESandXICE_MAX_PAIRS(or use dynamic allocation) to accommodate the extra sockets - Multi-port gathering — Bind multiple local UDP sockets per interface and collect srflx candidates for each
- Parallel check dispatch — Reduce pacing interval or send checks in parallel batches to fit within NAT mapping TTL
- Short timeout with TURN fallback — Set a ~5 s timeout for the birthday attack phase; on failure, immediately fall back to TURN relay
Priority
P3 — TURN relay already provides 100% connectivity for Symmetric NAT at the cost of modest relay-hop latency (typically tens of milliseconds with a well-placed TURN server). The birthday attack adds significant implementation complexity and non-deterministic success. Revisit if profiling shows TURN relay latency is a real bottleneck for the target use case, or if TURN server costs become a concern.
References
- Guha, S., Takeda, Y., & Francis, P. (2005). "NUTSS: A SIP-based Approach to UDP and TCP Network Connectivity"
- Ford, B., Srisuresh, P., & Kegel, D. (2005). "Peer-to-Peer Communication Across Network Address Translators"
- RFC 8445 — Interactive Connectivity Establishment (ICE)
- RFC 3489 — STUN (Classic NAT Type Classification)
xp2p — TODO
Optimize ICE nomination strategy to reduce connection establishment latency.
ICE Nomination Strategy Optimization
Background
During real-world testing of the xfer file transfer tool (sender behind restricted NAT, receiver on a public-IP VPS), we observed that the ICE agent takes longer than necessary to establish a connection. The root cause is the current nomination strategy: it waits for all candidate pairs to be dispatched before nominating, even if a high-priority pair has already succeeded much earlier.
Current Behavior
The current try_nominate logic in ice_agent.c requires two conditions:
if (any_succeeded && a->check_index >= a->pair_count) {
// nominate the highest-priority succeeded pair
}
- At least one pair has succeeded (
any_succeeded) - All pairs have been dispatched (
check_index >= pair_count)
With 8 candidate pairs and a 50 ms pacing interval, this means:
- Even if pair[2] succeeds at T=150 ms, nomination is delayed until T=400 ms (when all 8 pairs are dispatched)
- The extra 250 ms is pure waste — we're waiting for lower-priority pairs to be sent out, not for better results
Example from real logs
T=0ms send_check: pair[0] 192.168.1.11 -> 10.5.8.12 (host→host, will fail)
T=50ms send_check: pair[1] 192.168.255.10 -> 10.5.8.12 (host→host, will fail)
T=100ms send_check: pair[2] 192.168.1.11 -> 43.161.217.33 (host→srflx)
T=120ms ✅ check response: pair[2] SUCCESS ← could nominate here!
T=150ms send_check: pair[3] 120.229.22.97 -> 10.5.8.12 (srflx→host)
T=200ms send_check: pair[4] 192.168.255.10 -> 43.161.217.33 (host→srflx)
T=220ms ✅ check response: pair[4] SUCCESS
T=250ms send_check: pair[5] 120.229.22.97 -> 43.161.217.33 (srflx→srflx)
T=270ms ✅ check response: pair[5] SUCCESS
T=300ms send_check: pair[6] 120.229.22.97 -> 10.5.8.12 (srflx→host)
T=350ms send_check: pair[7] 120.229.22.97 -> 43.161.217.33 (srflx→srflx)
T=370ms ✅ check response: pair[7] SUCCESS
T=370ms nominated pair: pair[2] ← finally nominates!
Pair[2] succeeded at T=120 ms but nomination happened at T=370 ms — a 250 ms unnecessary delay.
Comparison with libwebrtc (Chromium)
| Aspect | moo (current) | libwebrtc (Chromium) |
|---|---|---|
| When to nominate | After all pairs dispatched | First success → immediately usable |
| Nomination model | One-shot, immutable | Dynamic, can switch to better pair later |
| USE-CANDIDATE flag | All checks carry it (aggressive) | Only on selected pair |
| Pacing impact on latency | High (N pairs × pacing = delay) | Low (first success starts DTLS) |
| Final pair quality | Guaranteed global optimum | Converges to optimum over time |
| Implementation complexity | Simple | Complex (path switching, DTLS migration) |
libwebrtc's "Continuous Nomination"
libwebrtc does not strictly follow either RFC 8445 Regular or Aggressive nomination. Instead it uses a custom strategy:
- First succeeded pair is immediately selected as
selected_connection, DTLS/data starts flowing - If a higher-priority pair succeeds later, it dynamically switches to the new pair
- A stabilization window prevents excessive switching
This gives the fastest possible time-to-first-byte while still converging to the optimal path.
Proposed Optimization
Approach A: Early Nomination (Recommended)
Change the nomination condition from "all pairs dispatched" to "no higher-priority pair is still pending":
When pair[i] succeeds:
If all pairs with priority > pair[i].priority have reached
a terminal state (Succeeded or Failed):
→ Nominate pair[i] immediately
Else:
→ Wait (a better pair might still succeed)
Benefits:
- Pair[2] in the example above would be nominated at T=120 ms (after pair[0] and pair[1] fail), not T=370 ms
- No need for path switching — we still pick the global best among completed pairs
- Minimal code change in
try_nominate
Risks:
- If pair[0] and pair[1] are still InProgress (not yet timed out), we'd still wait for them. But host→host pairs to unreachable private IPs typically fail quickly (ICMP unreachable), so this is rarely an issue in practice.
Approach B: libwebrtc-style Dynamic Switching
- First succeeded pair → immediately nominate and start DTLS
- If a better pair succeeds later → switch the nominated pair and migrate the DTLS path
Benefits:
- Absolute fastest connection establishment
- Matches browser WebRTC behavior
Risks:
- Requires DTLS layer to support path migration (re-binding to a different socket/address)
- Significantly more complex — need to handle in-flight packets during switch
- Overkill for the current use case
Approach C: Reduce Pacing Interval
Simply reduce XICE_CHECK_PACING_MS from 50 ms to a smaller value (e.g., 20 ms).
Benefits:
- Trivial change
- Reduces the "all dispatched" wait time proportionally
Risks:
- RFC 8445 recommends ≥ 50 ms pacing to avoid network congestion
- Doesn't solve the fundamental problem — just masks it
Recommendation
Approach A is the sweet spot: minimal complexity, significant latency improvement, and no RFC compliance concerns. It can be implemented by modifying the try_nominate function to check whether all higher-priority pairs (not all pairs) have been dispatched and resolved.
Approach B can be revisited later if sub-100ms connection establishment becomes a requirement.
Priority
P2 — The current strategy works correctly but adds unnecessary latency (100–300 ms depending on pair count) to every ICE connection. For interactive use cases like file transfer, this is noticeable. The fix is small and low-risk.
Affected Code
libx/x/p2p/ice_agent.c—try_nominate(),check_pacing_cb(),on_check_response()
References
- RFC 8445 §8.1.1 — Nominating Pairs (Regular and Aggressive)
- Chromium source:
p2p/base/p2p_transport_channel.cc—MaybeSwitchSelectedConnection() - Oleg Obolensky, "WebRTC ICE Nomination: How Browsers Really Do It" (webrtcHacks, 2020)
让 AI "像人":xagent 模块的长期产品方向
作者:小W(与麦伯伯讨论后整理) 日期:2026-04-23 状态:draft / 路线图,不是实现规范
0. TL;DR
- "像人" 不等于 "有记忆"。记忆只是四个维度之一,另外三个是:情绪延续、选择性遗忘、主动唤醒。
- 四个维度的难度递增,SOTA 覆盖度递减。第 1、3 维已有工业方案,第 2、4 维基本空白——护城河在后两维。
- 在现有
xAgent+xAgentSession架构之上,加三个内部组件即可铺开:xAgentMemory(分层记忆)、xAgentMood(情绪状态)、xAgentScheduler(主动唤醒)。公开 API 几乎不用动。 - 分三期:MVP(记忆 + 压缩)→ v1(情绪延续)→ v2(主动唤醒)。每期都给可测指标,不做"感觉更像人"这种玄学验收。
- 明确不做什么:不做通用 memory-as-a-service、不做无限上下文幻觉、不做"人格扮演"。
Part I. 问题定义:什么叫"像人"
"像人"是个被滥用的词。先拆清楚。
1.1 "有记忆" ≠ "像人"
当下主流的 AI Memory 产品(OpenAI Memory、Letta、MemGPT、A-MEM)都在解决一个狭义问题:
让 AI 在跨对话时能回忆起用户说过的事实。
这是必要条件但远不充分。一个有完美事实回忆的 AI 仍然会让人觉得"不像人"——因为它:
- 每次对话都是冷启动情绪(上次聊累了这次还是礼貌八股)
- 啥都记得,包括废话(缺乏遗忘这个认知功能)
- 永远 pull-only(你问它才查,从不主动想起来)
- 回忆方式是"检索到 fact 后生硬插入 prompt",而不是"这段对话让我想起你上次说过……"
真正让人觉得"像人"的,是这四个维度的组合:
| 维度 | 一句话 | 工业 SOTA |
|---|---|---|
| 分层记忆 | 区分当下、近期、长期、身份 | ⭐⭐⭐ MemGPT/Letta/A-MEM 在做 |
| 情绪延续 | mood 跨对话 carry-over | ⭐ 基本空白 |
| 选择性遗忘 | 压缩废话,保留高价值节点 | ⭐⭐ 多数是简单 time-decay |
| 主动唤醒 | push 而非 pull,适时提起旧事 | ⭐ 基本空白 |
1.2 为什么"像人"值得做
一句话:这是端侧 agent 相对云端 giant model 的唯一不对称优势。
- 云端模型(Claude/GPT)在"单次问答能力"上没人追得上,这条路打不过
- 但持续陪伴需要:长期一致的记忆、熟悉的情绪基调、低延迟响应、隐私本地化——这四个点云端都做不好
xagent跑在 moo 之上,本身就是轻量 / 嵌入式 / 本地优先的定位,正好吃这条赛道- 竞品:Character.AI(情绪在线但无持久记忆)、Replika(记忆有但肤浅)、OpenAI Memory(fact only,无 mood)——都没打穿
1.3 一个简单的判别准则
一个 AI 是否"像人",看它在下面这个场景的表现:
用户昨天说"最近项目搞崩了,很累"。今天开新会话,用户说:"早。"
- Fact-only AI:
早上好!今天想做什么? - 像人 AI:
早。昨天说很累,睡得还行吗?
差距在哪儿?
- 分层记忆命中了"昨天聊过什么"(长期)+"刚打招呼"(当前)
- 情绪延续记住了"累"这个 mood,没强行 reset
- 主动唤醒:用户没问,AI 先提——从 pull 切到 push
- 选择性遗忘:没去翻三个月前某句闲聊,只挑相关、近期的
这个测试可以作为 v2 的验收 benchmark。
Part II. 四个维度的深挖
2.1 分层记忆(Hierarchical Memory)
现象
人脑的记忆是分层的:
- 工作记忆(当下对话,7±2 项)
- 情景记忆(最近几天的具体事件)
- 语义记忆(长期稳定的事实 / 概念)
- 自传体记忆(关于"这个人是谁"的连贯叙事)
AI 如果全部塞 context window,两个问题:
- 容量天花板——128k 也就聊几天就爆
- 信号淹没——废话和重要的事同等权重,模型注意力被稀释
为什么难
- 写入路径:每轮对话后该存什么、不存什么,这是一个在线摘要问题,不是检索问题
- 读取路径:下一轮该调哪些记忆,这是语义相关性 + 时间相关性 + 情境相关性的三维打分
- 一致性:多轮对话里用户说法矛盾时怎么办("我喜欢 Python" → 一周后 "我现在主要写 Rust")
SOTA 现状(2025 年底)
六大方案的详细对比:
| 方案 | 分层架构 | 写入策略 | 读取策略 | 一致性处理 | 端侧适用 |
|---|---|---|---|---|---|
| MemGPT / Letta | 两级:Main Context(system + working + FIFO 消息)/ External Context(Archival 向量库 + Recall 消息历史) | LLM self-edit:模型自主调 core_memory_append/replace、archival_insert 等函数 | 溢出触发 recursive summarization | 靠 LLM 自己覆写 memory block | ❌ 依赖大模型 self-management |
| A-MEM | 扁平 + 原子笔记(每条 {content, timestamp, keywords, tags, context, embedding, links}) | LLM 三步:生成语义属性 → 向量检索 Top-k 邻居 → LLM 决定链接 | 向量 Top-k + 沿链接"同盒子"扩展 | Memory Evolution:新记忆会反向改写老邻居的 context/tags | ⚠️ 每次写入 |
| Mem0 | User/Session/Agent 三作用域 + Factual/Episodic/Semantic 逻辑分层 + v1.1 图记忆 | LLM 做 Add/Update/Delete/NOOP 四选一:新事实与旧记忆冲突时自动 invalidate | 向量检索 + 图关系 | 冲突覆盖(显式) | ⚠️ 写入频繁调 LLM |
| Memobase | Profile(长期画像,topic/sub-topic slot)/ Event(时间戳事件流)/ Buffer(短期缓冲) | Buffer 到阈值后 flush 进 Profile,LLM 做 slot merge/rewrite | Profile 全注入 + Event 检索 | Slot 重写 + 长度上限自动浓缩 | ⚠️ Profile slot 设计重 |
| Memary | 双层:Knowledge Graph(Neo4j 实体关系)+ Memory Stream(时序)+ Entity Store(按实体聚合 + 频次) | 实体抽取 → KG 入库 | 图推理 + Top-k 过滤 | KG 不删,靠检索阶段软过滤 | ❌ 需要图库基础设施 |
| ChatGPT Memory | 四层全量注入:Metadata / Recent 40 Conversations / Model Set Context(用户显式)/ User Knowledge Memories(AI 压缩) | 定期批量:把最近几百轮对话压缩成 10 段密集摘要 | 无 RAG,无向量——每次请求全量塞进 context | 仅靠用户显式覆盖(Model Set Context 优先级最高) | ❌ 押的是 context 窗口和成本下降(Bitter Lesson) |
两条路线的分野:
这六家其实分成两派:
- 工程派(MemGPT / A-MEM / Mem0 / Memobase / Memary):相信结构化分层 + 检索是正道。代价是写入路径有 LLM call 开销。
- 暴力派(ChatGPT Memory):赌 Sutton 的 Bitter Lesson——不做检索脚手架,全量塞,等模型和 context 窗口解决一切。代价是端侧和 API 用户用不起。
对 xagent 的启示:
- xagent 跑在端侧,context 成本硬约束——不能走 ChatGPT 的暴力路线,必须分层 + 检索。
- A-MEM 的 Memory Evolution(新记忆反向改写旧记忆)是真创新,解决了"用户前后矛盾怎么办"的一致性问题。值得吸收。
- Mem0 的 Add/Update/Delete/NOOP 四选一是比 A-MEM 更轻的一致性方案,端侧可能更适合。
- 共性缺陷:工程派的六家写入策略都是"LLM 自己决定",没有明确的价值函数。结果要么存太多(噪声),要么存太少(漏)。这是我们的机会。
xagent 落地思路
四层存储:
┌─────────────────────────────────────┐
│ L0: Working Memory │ = xAgentSession 内 messages 数组
│ 当前对话的 message 流 │ (已经有了,不用改)
├─────────────────────────────────────┤
│ L1: Episodic Buffer │ = 新组件 xAgentEpisode
│ 最近 N 轮对话的压缩摘要 │ 每轮结束时 LLM 抽取
├─────────────────────────────────────┤
│ L2: Semantic Store │ = 新组件 xAgentFact
│ 稳定事实(偏好、身份、重要决定) │ vector + keyword 双索引
├─────────────────────────────────────┤
│ L3: Self Model │ = 新组件 xAgentPersona
│ "这个用户是谁"的叙事性画像 │ 月级别更新
└─────────────────────────────────────┘
写入价值函数(避免"LLM 自己决定"的黑箱):
value(event) = α·recency + β·specificity + γ·emotional_intensity + δ·user_reference_count
α=0.2, β=0.3, γ=0.3, δ=0.2 # 初始权重,后续可学习
- specificity:事件越具体(专有名词、数字、时间)价值越高("我在 Tencent 工作"> "我有工作")
- emotional_intensity:对应 Part 2.2 的 mood 模块输出
- user_reference_count:用户后续是否又提起过(强信号)
超过阈值才升到 L2,否则过一段时间从 L1 蒸发。
读取路径:每轮用户输入进来时,并发查 L1(最近对话摘要,时间优先)+ L2(向量检索,语义优先),取 top-k 加进当轮 system prompt。L3 始终在 system prompt 头部。
一致性处理(借鉴 Mem0,而不是 A-MEM):
用户前后矛盾时("我喜欢 Python" → 一周后 "我现在主要写 Rust")怎么办?两个选项:
- A-MEM 路线:Memory Evolution,新记忆反向改写老邻居的 context/tags。优雅,但每次写入都要 LLM call,端侧太贵。
- Mem0 路线:LLM 判断 Add / Update / Delete / NOOP 四选一,只在检测到冲突时才改写。
选 Mem0 路线,但优化:
每次要写入 L2 fact 时:
1. 向量检索出语义最近的 3 条老 fact
2. 如果相似度 < 0.6:直接 Add(无冲突) ← 90% 的情况在这里结束,零 LLM call
3. 如果相似度 >= 0.6:才调 LLM 判断 Add/Update/Delete
这样90% 的写入走快速路径,只有可能冲突的 10% 才付 LLM 成本。比 A-MEM 便宜一个数量级。
与 ChatGPT Memory 对比:我们刻意放弃了它的"全量注入"路线,因为端侧玩不起。但吸收了它分模块边界清晰这一点:L0/L1/L2/L3 四层职责不重叠,每层有明确的写入源和生命周期。
2.2 情绪延续(Emotional Continuity)
现象(情绪延续)
"记住的不只是事实,还有情绪上下文。" 用户上次聊天累了,这次开场看到"累"这个上下文应该自然承接疲惫基调,而不是冷启动回到标准礼貌模式。
举个具体对比:
用户 [昨天]:忙了一整天,头都炸了 用户 [今天]:下班了
- Fact AI:
下班快乐!晚上有什么计划? - Mood AI:
下班了。昨天头还炸着,今天好点没?
第二个显然更像人。差别在于:昨天的 mood(疲惫)没有因为新对话开始而被清零。
为什么难(情绪延续)
- 情绪不是 fact——它没有好的结构化表示("疲惫"能存成 tuple 吗?)
- 衰减曲线不线性——强情绪可以 carry 几天,弱情绪一觉就散
- 多情绪混合——同时累 + 兴奋 + 焦虑是常态
- 双向:AI 的 mood 也会影响用户(AI 持续悲观 → 用户也沮丧)
这个维度没有现成工业方案。Character.AI 有情绪但不持久;Replika 有持久但模型很小 mood 表达粗糙。
xagent 落地思路(情绪延续)
引入 xAgentMoodState,一个小维度向量而非 one-hot:
XDEF_STRUCT(xAgentMoodState) {
float valence; /* -1 (消极) .. +1 (积极) */
float arousal; /* 0 (平静) .. 1 (激动) */
float fatigue; /* 0 (精力充沛) .. 1 (疲惫) */
float confidence; /* 0 (焦虑/不确定) .. 1 (笃定) */
uint64_t updated_ms;
};
这是 VAD 模型(Valence-Arousal-Dominance)的工程简化,心理学有共识基础,不是我拍脑袋。
更新:每轮对话结束时,由一个小 classifier(可以是另一个小模型 call,也可以是规则 + 关键词)给 user mood 打分,指数衰减合并到 xAgentMoodState。
mood_new = λ·mood_observed + (1-λ)·mood_prev·decay(Δt)
λ=0.3, decay(Δt) = exp(-Δt / half_life)
half_life = 12 小时(可配置)
消费:mood 序列化进 system prompt,作为"当前用户情绪基线"。模型的回复语气自然被引导。
注意:mood 不覆盖回复内容,只影响风格。AI 永远不应该说"我看你很疲惫哦"这种直接暴露检测——要隐式共情,像真实熟人。
2.3 选择性遗忘(Selective Forgetting)
现象(选择性遗忘)
人会忘。而且忘得有选择——忘掉细节,记住感觉;忘掉"吃了什么",记住"那天很开心"。
AI 如果啥都记,有两个问题:
- 存储爆炸
- 检索污染——关键信号被海量废话稀释
为什么难(选择性遗忘)
- "什么是废话"没有客观定义
- 压缩(丢信息)是不可逆的,必须谨慎
- 过度压缩 → AI 显得"健忘不靠谱";压缩不足 → 性能崩溃
SOTA 现状(选择性遗忘)(2025 年底)
这一维的业界方案比 2.1 维分裂得多——基本没有共识,每家用自己的土办法:
| 方案 | 遗忘策略 | 机制本质 | 问题 |
|---|---|---|---|
| Claude Code / Cline compact | 对话长度到阈值时整段压缩成摘要 | Lossy summarization | 粗暴一刀切,不分重要性 |
| MemGPT / Letta | Recursive summarization:旧消息递归总结归档 | 只压缩,不删 | 摘要会越来越长,二次信息失真 |
| MemoryBank | 艾宾浩斯遗忘曲线:每条记忆有 strength,随时间衰减,被访问时增强 | Time + access decay | 接近人类机制,但没看重要性 |
| Mem0 | LLM 判断 Add/Update/Delete/NOOP + TTL 衰减 | 冲突覆盖 + 时间过期 | 依赖 LLM 每次判断,成本高 |
| Memobase | Profile slot 达上限时 LLM 重写浓缩 | 容量驱动的 slot-level 压缩 | 只在容量满时触发 |
| Memary | recency + frequency 加权,检索阶段软过滤 | 低频老记忆自然沉底,不真删 | 软遗忘不节省存储 |
| A-MEM | 不做遗忘——用 "Memory Evolution" 代替(老记忆被改写不被删) | 演化替代遗忘 | 存储无限增长;"演化"本身靠 LLM,成本累积 |
| ChatGPT Memory | 没有遗忘机制——摘要一旦生成永久存在 | (none) | 作者自爆:2025 年 10 月的日本旅行计划还在记忆里,实际从未成行 |
业界共性失败:
- 只看时间(recency),不看价值(value)——LRU 对对话数据是错的前提
- 压缩=丢信息不可逆——一旦摘要就找不回细节
- LLM 判断成本高——A-MEM/Mem0 路线每次写入都要调模型,端侧玩不起
- 没有"情绪峰值保留"——重要的是情绪强度,不是语义密度
对 xagent 的启示:
- MemoryBank 的艾宾浩斯曲线是最接近人脑的,可以借鉴
- A-MEM 的演化太贵,但它的"不删只改写"哲学可以用于 L3 Persona
- Mem0 的冲突驱动覆盖轻量,可以用于 L2 Fact(我们在 2.1 已经借鉴)
- 没人做"情绪峰值保留"——这是我们的机会
xagent 落地思路(选择性遗忘)
双层压缩机制,参考 Claude Code 但做得更细:
Layer A: 实时微压缩(每 N 轮触发一次)
- 把最老的 k 轮原始消息合并成一条摘要(
xAgentMessagerole = System,content = "Earlier: ...") - 保留用户/AI 的关键发言原文(判据:在 mood 峰值 / 包含专有名词 / 用户后续引用过)
- 其余用摘要替代
Layer B: 晚期整合(会话结束后异步跑)
-
把当前会话的完整内容抽成一条 Episode(存 L1)
-
Episode 结构:
XDEF_STRUCT(xAgentEpisode) { uint64_t started_ms; uint64_t ended_ms; const char *summary; /* 3-5 句 */ const char *highlights; /* 带情绪峰值的原文片段 */ xAgentMoodState closing_mood; const char **fact_refs; /* 提升到 L2 的 fact id */ size_t fact_ref_count; }; -
Episode 级别用 value function 决定哪些 fact 升 L2
遗忘曲线:Episode 本身也会衰减。超过 30 天且从未被引用过 → 降级为纯 summary,丢掉 highlights。超过 180 天且仍未引用 → 删除。
这个机制等于给 AI 加了一条艾宾浩斯遗忘曲线。
2.4 主动唤醒(Proactive Recall)
现象(主动唤醒)
老朋友的定义之一:在合适时机主动提起旧事。
用户说过"下周去见客户很紧张" 一周后上线:AI 开口:"上次那个客户谈得怎样?"
这是push,不是 pull。现在所有 AI 产品(除了少数推送式日程提醒)都是 pull——用户不问就永远沉默。
为什么难(主动唤醒)
技术上:
- 时机判断需要 background scheduler(现有架构都是 event-driven reactive)
- 合适与否是个品味问题——push 太勤烦人、太稀形同没有
- 内容选择:哪件旧事值得提?(和"遗忘"反着用同一个 value function)
产品上:
- 边界极其敏感——push 过度会让用户觉得 AI "监视我"
- 必须对用户可控(静默模式、只在对话中主动提、不做通知推送)
SOTA:几乎无。Replika 有一个定时问候但极其机械。
xagent 落地思路(主动唤醒)
加一个后台组件 xAgentScheduler,架构上和 xEventLoop 的 timer 机制对齐:
/* 声明略——关键思路 */
XCAPI(xErrno) xAgentSchedulerArmProactive(
xAgentScheduler sch,
xAgentSession sess,
const xAgentEpisode *source_episode,
uint64_t not_before_ms, /* 最早允许 push 的时间 */
uint64_t not_after_ms, /* 超过就作废 */
float priority); /* 0-1 */
触发条件(AND 全满足才 push):
- 用户主动开启新会话(绝不在静默时打扰)
- 当前会话还没聊到相关话题
source_episode.closing_mood有未解悬念(未完成的事、强情绪)- 距上次 push 不少于 X 天(避免轰炸)
- 当前 mood 允许(用户情绪极差时别戳痛点)
落地形态:不是独立推送,而是在用户开启新会话、AI 第一句回复时,由 scheduler 往 system prompt 里注入一条 "Consider proactively asking about: ..."。是否真的开口让模型自己决定——模型读完上下文觉得不合适就不提,天然有一层过滤。
关键设计:scheduler 只"建议",不"强制"。这样模型自己的分寸感成为最后一道过滤。
Part III. 架构草图
在现有 plan.md 描述的两层对象模型上,不推翻任何公开 API,加三个内部组件:
┌──────────────────────────────────────────────┐
│ xAgent │
│ (能力模板,长生命周期) │
│ │
│ provider: xAgentProvider │
│ tools: xAgentTool[] │
│ │
│ ┌───────────── NEW ──────────────────┐ │
│ │ memory: xAgentMemory │ │
│ │ mood: xAgentMoodTracker │ │
│ │ scheduler: xAgentScheduler │ │
│ └────────────────────────────────────┘ │
└──────────────────────────────────────────────┘
│ create
▼
┌──────────────────────────────────────────────┐
│ xAgentSession │
│ (一次对话实例) │
│ │
│ messages: xAgentMessage[] ← L0 Working Mem │
│ callbacks: on_text/done/error/tool │
│ │
│ 每轮 input/output 时: │
│ ↓ 读:memory.retrieve(user_input) → inject │
│ ↓ 读:mood.current() → inject │
│ ↓ 读:scheduler.pending() → inject │
│ ↑ 写:memory.observe(turn) │
│ ↑ 写:mood.update(turn) │
│ ↑ 写:scheduler.consider(turn) │
└──────────────────────────────────────────────┘
为什么放 Agent 不放 Session:
- Memory/Mood/Persona 是跨会话的——必须随 Agent 生命周期
- Session 是一次对话,短生命;Memory 要比它活得久
- 多个 Session 并发时共享同一份 Memory(带锁,但多数是读多写少)
为什么公开 API 不用动:
- 这三个组件的更新都在
xAgentSession内部完成(每次 input/done) - 使用方从不直接操作 memory/mood
- 暴露点仅两个可选配置项加到
xAgentConf:memory_backend和persona_init
Part IV. 三期路线图
每期都有可测指标,不做"感觉更像人"。
MVP:分层记忆 + 选择性遗忘(6-8 周)
交付:
xAgentMemory(L0 复用现有 messages,L1 Episode,L2 Fact)- Layer A 实时微压缩
- 基础 value function
指标:
- 长对话(>100 轮)不崩,上下文命中率 ≥ 70%
- 存储增长:每轮 < 500 bytes 平均
- 用户主动引用过的旧事,回忆准确率 ≥ 85%(人工标注 200 条)
依赖:
- 需要一个本地嵌入模型(bge-small / all-MiniLM)做向量检索
- SQLite + sqlite-vec(已成熟,别发明轮子)
v1:情绪延续(4-6 周)
交付:
xAgentMoodTracker- mood classifier(小模型 call 或规则)
- system prompt 注入
指标:
- Mood carry-over benchmark:20 组"前后对话"测试,跨会话 mood 连续性人工评分 ≥ 7/10
- A/B:开 mood vs 不开 mood,用户留存 / 满意度对比
- 无 regression:mood on 不应导致回复质量下降(对照组 blind 评测)
v2:主动唤醒(6-8 周)
交付:
xAgentScheduler- 集成到 Session 首轮 prompt
- 用户控制(关 / 频率 / 场景白名单)
指标:
- Push 准确率:人工标注 50 次 push,"合适"率 ≥ 80%
- 骚扰率:≤ 5%(用户打分"烦"的次数 / 总 push 次数)
- 上面 Part I.3 的"早"测试,盲评通过率 ≥ 60%
Part V. 反共识的取舍
明确不做:
-
无限上下文幻觉 不追求 "1M context window" 方向。长 context 是暴力不是智能。人脑工作记忆也就 7±2,靠的是分层和压缩。
-
通用 Memory-as-a-Service 不做 Letta 那种把 memory 抽成通用服务。memory 必须深度绑定对话架构和情绪,拆开就不"像人"了。
-
人格扮演 / roleplay
xAgentPersona是对用户的画像,不是给 AI 套皮套。Character.AI 那套路我们不跟。 -
完全 LLM self-management MemGPT 那套"让大模型决定存啥"在云端大模型上能工作,在端侧小模型上会崩。我们用明确的 value function + 轻量模型辅助,工程可控。
-
push 通知 scheduler 只在用户主动开启会话时注入建议,不做主动弹窗 / 邮件推送。这是底线,破了就变骚扰产品。
附录 A:与 moo 现有设计的一致性检查
| moo 惯例 | 本方案是否符合 |
|---|---|
纯 C99、XDEF_HANDLE 不透明句柄 | ✅ xAgentMemory / xAgentMoodTracker / xAgentScheduler 都走 handle |
| 事件循环为一等入参 | ✅ scheduler 用 xEventLoopTimerAfter,memory 异步写 |
| 依赖显式传入,不自 new | ✅ memory 用到的 sqlite handle 由调用方传入 |
| 回调中指针仅回调期有效 | ✅ memory.retrieve 返回的 fact 列表遵循同约定 |
错误码 xErrno | ✅ |
| CMake 目标依赖 xbase/xnet/xhttp | ✅ 新增对 sqlite 的 optional 依赖 |
附录 B:术语表
- L0 / L1 / L2 / L3:分别对应工作记忆 / 情景缓冲 / 语义存储 / 自我模型
- VAD:Valence-Arousal-Dominance,心理学情绪维度模型
- Episode:一次完整会话压缩后的结构化记录
- Fact:从 Episode 中提升出来的稳定语义片段
- Persona:关于用户的叙事性长期画像
- Push vs Pull:AI 主动提起 vs 用户问了才答
附录 C:参考阅读
核心论文
- MemGPT: Towards LLMs as Operating Systems (Packer et al., 2023) — arxiv:2310.08560
- A-Mem: Agentic Memory for LLM Agents (Xu et al., 2025) — arxiv:2502.12110,NeurIPS 2025 poster
- MemoryBank(艾宾浩斯遗忘曲线的 LLM 记忆工程化)
- Memory in the Age of AI Agents: A Survey(2025 年底最新综述,新加坡国立/人大/复旦等联合发布)
- Memory OS of AI Agent — ACL 2025
开源实现
- Letta (原 MemGPT 产品化) — github.com/letta-ai/letta
- A-MEM 生产级实现 — github.com/WujiangXu/A-mem-sys
- Mem0 — github.com/mem0ai/mem0
- Memobase — memobase.io
- Memary — Neo4j + 向量的个人助理记忆实现
产品逆向分析
- How ChatGPT Memory Works — shloked.com/writing/chatgpt-memory-bitter-lesson(关键发现:ChatGPT Memory 不用 RAG,全量注入 + AI 压缩摘要)
心理学基础
- VAD 情绪模型:Russell (1980), "A Circumplex Model of Affect"
- Ebbinghaus 遗忘曲线(1885)
- Tulving 情景记忆 / 语义记忆区分(1972)
本地工程笔记
- Claude Code compact 机制(本地分析文档
claude-code-agent-loop-analysis.md) - xagent 第一批次 plan.md(API 骨架)
6. MVP 执行边界(2026-04-24 启动)
文档 §0-§5 是路线图,回答"做什么 / 为什么做"。本节是执行边界,回答"MVP 这一期到底做到哪、用什么做、不做什么"。Session/Query 拆分从此节得到合法性——具体拆分方案见
xagent_architecture.md§10。
6.1 MVP 为什么拆成 MVP-a / MVP-b 两小段
原 §4 的 MVP 范围(L0+L1+L2 全套 + 基础 value function + 双层压缩)6-8 周做不完。主要瓶颈是 L2 需要本地 embedding 模型 + sqlite-vec 集成,光依赖引入和端侧打包体积管控就是独立工程。
所以拆成两段,MVP-a 跑起来 → 看到跨 session 效果 → 再决定要不要做 MVP-b:
| 段 | 周期 | 核心交付 | 依赖 |
|---|---|---|---|
| MVP-a | 3-4 周 | L0 复用 + L1 Episode 抽取 + JSONL 持久化 + Agent 层 memory 勾子雏形 | 零新依赖(只加 JSONL 文本 IO) |
| MVP-b | 3-4 周 | L2 Fact 向量检索 + SQLite + sqlite-vec + embedding 模型集成 | 依赖评估:sqlite-vec 成熟度、embedding 模型选型(bge-small / all-MiniLM) |
MVP-a 不触 L2,意味着跨 session 只有时间索引 + 文本摘要,没有向量检索。这够不够"像人"?够用于验证 Part I.3 的"早"测试的一半——记得昨天聊过什么(情景记忆命中),但答不上"我三个月前提过的某个同事"这种语义模糊的长期回忆。后半部分等 MVP-b。
6.2 四条关键决策(拍板记录)
以下是 §4.MVP 留的悬念的正式拍板,2026-04-24 敲定,写死在本节。后续实施过程如遇反例要改,必须在本节留修订记录。
决策 1:MVP-a 只做 L0+L1,不做 L2
- L0:复用
xAgentSession现有messages数组,零改动 - L1 Episode:新增
xAgentEpisode结构,在 session 终结时抽取 - L2 Fact:推到 MVP-b
- L3 Persona:推到 v1 之后(和 mood 一起做,见原 §4 v1)
理由:L1 单独可验证(Part I.3 的"早"测试只需 L1 就能跑通一半);L2 的向量检索依赖是独立风险点,不应该绑在 MVP 交付路径上。
决策 2:L1 存储用 JSONL,不引 SQLite
- MVP-a 存储:每个 session 一个 JSONL 文件,每条
xAgentEpisode一行 - 文件布局:
~/.<app>/xagent/episodes/<agent_id>/<YYYY-MM>/<session_id>.jsonl - 检索方式:按时间窗口 scan(MVP-a 检索只需要"最近 N 天",不需要语义匹配)
- MVP-b 切 SQLite + sqlite-vec:迁移脚本提供,老 JSONL 直接归档不删
理由:MVP-a 不做向量检索,就不需要 SQLite。引入 sqlite-vec 是 MVP-b 的事,提前引只会让 CMake 依赖、端侧体积、license 审查都提前到账,没收益。
决策 3:L1 抽取用"规则 + 轻量 LLM call"组合,value function 延后
- MVP-a 抽取策略:
- 规则先过:明确"值得记"的条目(包含专有名词、数字、时间、URL 等硬特征)直接入库
- 不确定时调 LLM:一条 prompt ≤ 200 tokens,让模型判断 yes/no + 提取摘要
- value function 完整计算推到 MVP-b:MVP-a 先记下原始信号(specificity 指标、user_reference_count 计数),不做 α/β/γ/δ 加权计算;等 MVP-b 有线上数据了再调权重
- LLM 选型:复用 Agent 配置的 provider,不引入第二个 provider;prompt 模板内置
理由:value function 的权重调优必须有线上数据才合理,现在拍脑袋 α=0.2/β=0.3 完全没根据。MVP-a 只收集信号、不做决策,是最诚实的做法。
决策 4:Session/Query 拆分与 MVP-a 的绑定时序
序列(硬依赖,不可并行):
Step 1 (xagent_architecture.md §10) [2026-04-24 起,约 3-5 天]
└─ session.c 内部 query_*/session_* 分组 + on_provider_done 拆三份
└─ session_test 9/9 全绿作为 Step 2 开工门槛
↓
Step 2 (xagent_architecture.md §10) [Step 1 过 review 后,约 5-7 天]
└─ 引入 xAgentQuery 类型 + 落实 §8 预留勾子
└─ 对外 API 零 break
↓
MVP-a [Step 2 过 review 后,约 3-4 周]
└─ xAgentEpisode 结构 + 抽取流水线
└─ JSONL 存储层
└─ Agent 层 memory 勾子雏形(不暴露公开 API)
└─ 端到端测试:两个连续 session,第二个开场能引用第一个的 Episode
↓
MVP-b [MVP-a benchmark 通过后,约 3-4 周]
└─ sqlite-vec 依赖引入 + embedding 模型集成
└─ L2 Fact 向量检索
└─ value function 权重调优(线上数据驱动)
总预算 5-6 周到 MVP-a 交付,跟原 §4 的 6-8 周接近但可验证节点更多。
6.3 MVP-a 可测指标
交付验收的硬指标(比原 §4 的指标更严,因为只做 L0+L1):
- 跨 session 命中率:构造 30 组"上一 session 说 X → 下一 session 开场"测试,L1 命中率 ≥ 80%(人工标注)
- Episode 抽取准确率:从 L1 能恢复出原 session 核心内容,人工评分 ≥ 7/10
- 规则快速路径占比:≥ 60% 的 Episode 不需要 LLM call 就能决定入库与否(控制成本)
- 存储增长:每 session 平均 ≤ 2 KB JSONL(L1 只存摘要不存 highlights,MVP-a 阶段)
- 性能:session 终结时的 L1 抽取延迟 ≤ 500ms(中位数),不阻塞用户下一 session 开启
- 回归:开 L1 vs 不开 L1,单次对话的 on_text 延迟差 ≤ 10ms(L1 写入不能拖慢主路径)
Part I.3 的"早"测试不在 MVP-a 验收里——那个需要 mood(v1)才能真正通过,MVP-a 只覆盖"事实命中"这一半。
6.4 MVP-a 明确不做
钉死边界,避免范围漂移:
- 不做 mood:情绪延续是 v1 的事,MVP-a 连
xAgentMoodState结构都不声明 - 不做 scheduler:主动唤醒是 v2 的事,MVP-a 的 Agent 层没有后台 timer
- 不做 Layer B 晚期整合:只做实时 L1 抽取,没有异步 background 压缩任务
- 不做 L3 Persona:Agent 层会预留
persona字段但 MVP-a 不写入 - 不做 value function 加权:只收集原始信号,不做 α/β/γ/δ 计算
- 不做跨 Agent memory 共享:每个 Agent 的 Episode 文件独立,互不串
6.5 修订记录
| 日期 | 修订 | 理由 |
|---|---|---|
| 2026-04-24 | MVP 启动,拆 a/b 两段,钉死四条决策 | 决定扣扳机,动 Session/Query 拆分 |
结语
"像人"不是玄学,是四个可拆解维度的工程问题:分层记忆、情绪延续、选择性遗忘、主动唤醒。每一维都能量化、能测。
SOTA 的现状是:第 1、3 维在卷,第 2、4 维几乎空白。我们的机会在后两维,尤其是把四维组合起来——没人做过。
在 xagent 现有架构上,这条路不需要推翻 API,只需要加三个内部组件(Memory / Mood / Scheduler),分三期交付。
记人,比记事更重要。
xagent — 三层架构设计方案(Agent / Session / Query)
把
xAgentSession现在身兼数职的单层状态机,拆成三层架构: Agent Loop(进程级自我)→ Session Loop(任务级对话)→ Query Loop(请求级无状态执行)。本文档是执行蓝本:从职责切分到 API 草案到三步迁移路径全部给齐,后续直接按这份文档动手。
零、TL;DR
- 三层职责正交——Agent 问 "这个 AI 怎么活";Session 问 "这个任务怎么完成";Query 问 "这次请求怎么跑完"。
- 数量关系严格 1 : N : N——一个进程一个 Agent(通常),一个 Agent 持有 N 个 Session,一个 Session 内跑 N 次 Query。
- 近期落地:Session/Query 拆分(三步走),对外 API 零 break。
- 远期登记:Agent 层在 human-like-ai MVP 启动时开工;Session/Query 拆分时预留勾子供 Agent 将来接入,不堵死。
- 硬约束:Query 层绝对无状态、绝对干净——Agent/Session 的上下文绝不通过 Query API 穿透。
- 硬前置:Session/Query 拆分的触发条件是 human-like-ai MVP 决定启动;否则不启动。
Part I · 架构定海神针
1. 三层切分的直觉
┌──────────────── Agent Loop(进程级 / 用户级)─────────────────┐
│ "这个 AI 整体怎么活着" │
│ │
│ ● 跨 session 自我认知(L2/L3 记忆、人格、风格偏好) │
│ ● 长期记忆仓:用户稳定事实、项目约定、历史里程碑 │
│ ● 主动唤醒调度:定时器、事件触发、"想起来"的 push 通道 │
│ ● 多 session 共存管理:主线 session + sub-agent session │
│ ● 人格一致性守卫:每个新开 session 的 system prompt 预算 │
│ │
│ 持有:一份"自我" + N 个 Session │
└─────────────────────────────────────────────────────────────────┘
↓ 管理 N 个
┌──────────────── Session Loop(任务级 / 对话级)───────────────┐
│ "这个任务/对话怎么推进到完成" │
│ │
│ ● 本次对话完整 context(history + 工作记忆 L0/L1) │
│ ● Context 压缩 / summarize │
│ ● System prompt 组装(含从 Agent 层拉来的人格/记忆前缀) │
│ ● Turn 预算、stop 决策 │
│ ● Sub-agent 编排(tool 里 spawn 子 Session) │
│ ● Memory 抽取:把本轮产出过筛后上报给 Agent │
│ ● 决定下一次 Query 的 input(用户新输入 / 自发总结 / 子任务) │
│ │
│ 持有:history + 若干次 Query 的生命周期 │
└─────────────────────────────────────────────────────────────────┘
↓ 一次任务里跑 N 次
┌──────────────── Query Loop(请求级 / 无状态)─────────────────┐
│ "把这次 LLM 请求跑到没有未 resolve 的 tool_use 为止" │
│ │
│ ● submit → 流事件聚合 → tool dispatch → 再 submit │
│ ● per-round scratch(text/thinking/tool_use buffer) │
│ ● 不知道 history、不知道 memory、不知道兄弟 session │
│ │
│ 持有:一次 query 的临时 scratch │
└─────────────────────────────────────────────────────────────────┘
三个问题完全正交——这是切对了的标志。每一层的输入是上一层的决策,输出是一个可消化的 result。
2. 三层之间的关键协议
这一节划协议——层与层边界上"谁必须知道谁在做什么"。字段和 API 形态等实装前再定细节。
2.1 Agent → Session:注入
Agent 在每次 Session 创建时提供三样东西:
- 人格描述 / 风格约束:注入到 Session 的 system prompt。内容稳定、跨 Session 一致、由 Agent 持有唯一来源。
- 记忆前缀(L2/L3 相关条目):Agent 根据本次 Session 的类型/意图挑选相关记忆,打包成一段结构化上下文塞进 system prompt。Session 不反向查询 Agent 的记忆仓——避免 Session 层需要理解记忆索引。
- Mood 初始值(v1 之后):从 Agent 当前 mood state 拷一份给 Session 作为初始 mood,Session 内部可以演化这份 mood,结束时 Agent 再消化更新。
2.2 Session → Agent:上报
Session 在每次 Query 结束后上报候选:
- L1 抽取候选:从本轮 assistant 产出里过筛出"值得记住的东西"。抽取在 Session 层做(它最清楚这轮讲了啥),落盘决策在 Agent 层做(它最清楚全局,能去重 / 合并 / 冲突裁决)。
- Mood delta(v1 之后):本轮对话让用户/AI 的 mood 发生了什么变化。结构化的 delta,不是 free-form 文本。
- Session 生命周期事件:被创建、被销毁、被用户主动结束、因错误终止。Agent 根据这些做"记忆固化"、"长期统计"等副作用。
2.3 为什么"抽取—上报—裁决"是硬要求
如果把 L1 落盘也放在 Session 层,每个 Session 写自己的一份持久化记忆,会有两个问题:
- 多 Session 并存时的写冲突:Session A 和 Session B 同时上报"麦伯伯偏好 tab 不用 space",Agent 层能看到是重复事实直接去重;Session 层各写各的就会留两条。
- 全局视野缺失:某条 L1 事实在单个 Session 里看价值一般,但跨 Session 反复出现 5 次才显出它是稳定事实。去重计数这件事必须要有"看得到全局"的层做。
这两件事只能由 Agent 做。所以"Session 抽取、Agent 裁决"是硬要求,不是风格选择。
2.4 Agent → Agent(主动唤醒):自举
主动唤醒场景下:
- Agent 的调度器(定时/事件)决定"该起一个新 Session 了"
- Agent 生成 initial input("你想到什么就说什么" / "用户昨天说累了,主动问候一句")
- Agent 创建 Session,Session 跑起来像普通对话一样
- 唯一区别是"第一条 input 不是用户发的,是 Agent 自发的"
这个路径要求 Session 层的 API 不假设 input 必须来自用户——这是 Session/Query 拆分时必须预留的勾子。见 §8.2。
3. 记忆分层归属终稿
| 层级 | 内容 | 归属 | 生命周期 |
|---|---|---|---|
| L0 | 当前对话的 raw history(turns、tool calls、events) | Session | 随 Session 销毁 |
| L1 | 本 Session 内抽取的要点 | Session 抽取、Agent 裁决落盘 | 跨 Session 存活、但会衰减/合并 |
| L2 | 稳定事实(用户偏好、项目约定、关键里程碑) | Agent | 长期存在、定期 compact |
| L3 | 自我认知与人格 | Agent | 近乎永久、极慢演化 |
L1 在 Session 的角色是"候选池":Session 边跑边往里塞候选,跑完后一次性喂给 Agent,Agent 决定哪些进 L2、哪些归并到既有 L2、哪些直接丢弃。Session 自己不保留 L1——Session 销毁时 L1 随之消失,留给后人看的 L1 必须已经通过裁决升级为 L2,这条规矩能强迫 Agent 裁决不得偷懒。
Part II · Session / Query 拆分(近期要执行)
4. 为什么要拆:现状痛点
4.1 session.c 876 行里挤了 7 类职责
| # | 职责 | 代码位置 |
|---|---|---|
| 1 | 滚动历史存储(flat entries + 折叠成 message) | history_*、view_build |
| 2 | 流式事件聚合(text / thinking / tool_use buffer) | assist_*、reasoning_*、pending_* |
| 3 | Tool loop(判 ToolUse → dispatch → 再 submit) | on_provider_done 后半段 |
| 4 | Turn 预算管理(max_turns、cancel、状态机) | submit_round + finish_run |
| 5 | Usage 跨轮累加(-1 哨兵) | usage_accumulate |
| 6 | 终止原因翻译(provider stop → done reason) | translate_terminal |
| 7 | Callback 路由(session-level callback → 外部) | s->cbs.on_* |
其中 3 + 4 已经在 on_provider_done 里缠成一团:判断 "这次停了之后要不要继续" 的那条 if 链,同时含了 provider 终止原因、用户 cancel、max_turns、dispatch rc、cancel 二次检查、submit rc 六种信号,70 多行。再往里塞 memory / compression / sub-agent 的 hook,就会变成"谁都不敢动"的地狱函数。
4.2 现有架构无法干净容纳的特性
- Context 压缩 / budget 管理:
context_budget字段占了位但submit_round没真用它。压缩的天然时机是"两轮 LLM 请求之间",但现状下"两轮之间"没有明确的回调/状态点。 - Memory hook(human-like-ai MVP 的核心):L0/L1 抽取要在"这次对话终结后、下次开始前"做;L2/L3 注入要在"下次 submit 之前"做。同样需要"turn 边界"。
- Sub-agent:父 Session 的某个 tool handler 里 spawn 子 Session,await 子 Session 的最终回复并把它当 tool_result 塞回父 Session 的 history。现状下没有"我发起一次 query 并等它结束"的语义。
- 非流式一次性 query(未来可能的批处理接口):需要一个纯执行型的抽象。
4.3 为什么叫 Query 不叫 Turn
- "Turn" 在 LLM 语境里通常指 user↔assistant 交替的轮次。我们这个类型的本质是"一次查询产生若干 tool round 直到稳定",用 Turn 会让读代码的人误以为它对应一次 user message ↔ assistant reply 的配对。
- "Query" 更贴合"一次调用 LLM(及其内部 tool loop)直到终结状态"的语义。
- 和 Claude Code 源码/文档的术语对齐(CC 的
query()是无状态 generator 执行器),日后对照阅读零翻译成本。 - 内部静态函数前缀
query_*比turn_*/q_*更自解释,读起来也不会和history_append_*这类动词打架。
5. 职责重新切分
| 原 session 职责 | 拆后归属 |
|---|---|
| 1 滚动历史存储 | Session |
| 2 流式事件聚合 | Query(一次 query 的 scratch) |
| 3 Tool loop | Query(query 的本质) |
| 4 Turn 预算(max_turns) | Session(决策边界) |
| 5 Usage 累加(跨 query) | Session |
| 6 Stop reason 翻译 | Query 生成 result,Session 翻译给用户 |
| 7 Callback 路由 | 两层各有,外层透传 |
| 8 Context 压缩(新) | Session(query 间) |
| 9 Prompt 注入(新) | Session(query 前构造) |
| 10 Memory hook(新) | Session(query 间) |
| 11 Sub-agent(新) | Session(起子 Session) |
6. 两层协作示意
┌─────────────────── xAgentSession(长期持有、有状态)────────────────────┐
│ │
│ history[], agent, memory, budget, max_turns, cbs… │
│ │
│ for (;;) { │
│ view = build_view(history + system_prompt + memory_prefix); │
│ xAgentQuery q = xAgentQueryCreate(sess, &forwarding_cbs); │
│ xAgentQueryRun(q, view, next_input); │
│ ...(等 on_done(result) 回调)... │
│ │
│ // ↓↓↓ 以下三件事是 "Query 之间" 做的,跟 Query 内部零耦合 ↓↓↓ │
│ memory_absorb(sess, result); // L0/L1 抽取 │
│ maybe_compact(sess); // budget 预警时压缩 │
│ next_input = decide_next(sess);// 继续 / 结束 / 起 sub-agent │
│ } │
└───────────────────────────────────────────────────────────────────────┘
↓ 每一轮 create 一个
┌─────────────────── xAgentQuery(短命、无状态、一次性)──────────────────┐
│ │
│ 从 Session 借来 view + input,自己内部跑 tool loop: │
│ submit → stream events → 若 ToolUse:dispatch tools → 再 submit │
│ → 直到 provider 返回非 ToolUse 的终结状态(Terminal/Error/Cancel) │
│ │
│ 对外只流式 yield 四类事件,最后给一次 on_done(result): │
│ on_text / on_thinking / on_tool / on_done(xAgentQueryResult*) │
│ │
│ 不知道 memory、不知道 compact、不知道 session 历史 │
└───────────────────────────────────────────────────────────────────────┘
7. 新 API 草案
/* ── xagent/query.h ────────────────────────────────────────────────── */
XDEF_HANDLE(xAgentQuery);
/**
* 一次 query 的最终结果,on_done 时交给调用方(通常是 session.c)。
* 指针只在回调期间有效,Session 消化完就释放。
*/
XDEF_STRUCT(xAgentQueryResult) {
xAgentProviderStopReason stop_reason; /* 最后一轮 provider 给的原因 */
xErrno err; /* 若 stop_reason == Error */
xAgentUsage usage; /* 这次 query 跨所有 round 的累加 */
/* query 期间 append 到 session history 的条目范围 [begin, end)。
* Session 用这个区间做 memory_absorb / compact 的输入界定。 */
size_t hist_begin;
size_t hist_end;
int rounds; /* 本次 query 实际的 provider
submit 次数(>= 1) */
};
XDEF_STRUCT(xAgentQueryCallbacks) {
void (*on_text) (xAgentQuery q, const char *chunk, size_t len, void *ud);
void (*on_thinking)(xAgentQuery q, const char *chunk, size_t len, void *ud);
void (*on_tool) (xAgentQuery q, const char *tool_name, int started, void *ud);
void (*on_done) (xAgentQuery q, const xAgentQueryResult *result, void *ud);
void *user_data;
};
/**
* 配置:query 执行过程中的 *局部* 限制,不涉及 memory/compact 等
* 外层决策性参数——那些留给 Session 层。
*/
XDEF_STRUCT(xAgentQueryConf) {
int max_rounds; /* 本次 query 内 tool loop 最多几轮 submit;
0 = 继承 session->max_turns */
int max_tokens; /* 每轮 submit 的 completion 上限;0 = 继承 */
};
XCAPI(xAgentQuery)
xAgentQueryCreate(xAgentSession sess,
const xAgentQueryConf *conf,
const xAgentQueryCallbacks *cbs);
/**
* 启动。输入 input 会被 append 到 session history,然后向 provider
* 提交第一次 submit。query 从此进入自循环直到 on_done。
*
* 调用方应确保:
* - Session 当前没有别的 query 在跑(由 session 层保证)
* - input 的内存所有权规则与 xAgentSessionInput 一致(shallow copy)
*/
XCAPI(xErrno) xAgentQueryRun(xAgentQuery q, xAgentMessage input);
/** 请求取消;on_done 仍会 fire(stop_reason == Cancelled)。 */
XCAPI(void) xAgentQueryCancel(xAgentQuery q);
/** 销毁。若还在跑,内部先 cancel 并 drain 完回调再释放。 */
XCAPI(void) xAgentQueryDestroy(xAgentQuery q);
Session 的变化面(对现有 xAgentSession API):
xAgentSessionInput(sess, msg)的签名不变,内部实现改成 "创建一个 xAgentQuery 并启动它"。xAgentSessionCallbacks的on_text / on_thinking / on_tool / on_done / on_error保持不变。Session 内部做一层 forwarding:query 的回调先进 Session,Session 加工一下(比如 on_done 要翻译 stop_reason 成 xAgentDoneReason、加上跨 query 累加的 usage)再抛给用户。- 对外 API 零 break。所有改动都是内部重构。
8. Agent 层对 Session/Query 拆分的反向约束
Agent 层现在不动手,但 Session/Query 拆分时必须留几个勾子,否则将来引入 Agent 会二次大改 Session API。
8.1 Session 的 callback 分发不硬编码单消费者
Session 现在对外暴露的 xAgentSessionCallbacks 假设用户代码是唯一消费者。Agent 层上来之后,callback 的消费者会变成 "Agent + 用户代码" 双路。
- 落实:Session 拆分阶段保留现有 callback API 给外部用户;Agent 层将来通过另一条内部观察者接口接入,不走公开 callback。
- 含义:Session 内部的事件分发不要硬编码"只 fan-out 到一个 callbacks 结构",留一个可扩展的 observer list(或至少预留
void *owner; void (*on_event)(...)这种钩子槽位)。
8.2 Session 的 input 显式携带 origin 标记
Session 现在的 xAgentSessionInput 隐含"user message"语义。Agent 主动唤醒场景下,initial input 是 Agent 合成的。
- 落实:Session 拆分时就把 input 定义显式携带一个 origin 标记(
user/system_synthesized),而不是靠调用路径隐式区分。 - 含义:Agent 层引入后,内部 system-synthesized input 不会污染 L1 抽取(Session 知道"这条不是用户说的,别当成用户偏好")。
8.3 Session 销毁要有"可上报"的钩子
Session 销毁时 Agent 需要做一次 final digest——把还没上报的 L1 候选、mood delta 汇总一次。
- 落实:Session 销毁流程里预留一个
on_session_finalizing回调点,在资源释放之前调用。 - 含义:Agent 将来挂进去只需要实现这个回调,不需要改 Session 销毁流程。
8.4 Query 层保持绝对无状态、绝对干净【最硬规矩】
Agent 层的任何勾子都不应该穿透到 Query 层。Query 层不感知有没有 Agent,也不感知 memory、mood、sub-agent。这是三层解耦最硬的规矩。
- 落实:Query 的所有 callback 参数只带"这一次查询"的数据,绝不带 session/agent 指针。需要 session/agent 上下文的特性(比如 tool handler 想查 memory),通过 session 层的
user_data透传,不改 Query API。
9. Callback 透传层的设计
Session 内部维护一个 per-session 的 xAgentQueryCallbacks,每次起 Query 时传给它:
static void forward_on_text(xAgentQuery q, const char *chunk, size_t len, void *ud) {
struct xAgentSession_ *s = ud;
if (s->cbs.on_text) s->cbs.on_text((xAgentSession)s, chunk, len, s->cbs.user_data);
}
/* forward_on_thinking / forward_on_tool 同理 */
static void forward_on_done(xAgentQuery q, const xAgentQueryResult *r, void *ud) {
struct xAgentSession_ *s = ud;
/* 跨 query 累加 usage */
session_usage_accumulate(s, &r->usage);
/* Query 间 hook 点 —— MVP 阶段先留空,未来 memory/compact 接入 */
/* memory_absorb(s, r); */
/* maybe_compact(s); */
xAgentDoneReason reason = session_translate_stop(r->stop_reason, s->cancelled);
if (reason == xAgentDoneReason_ModelError && s->cbs.on_error) {
s->cbs.on_error((xAgentSession)s, r->err, NULL, s->cbs.user_data);
}
if (s->cbs.on_done) {
s->cbs.on_done((xAgentSession)s, reason, &s->usage, s->cbs.user_data);
}
/* 释放 query */
xAgentQueryDestroy(s->current_q);
s->current_q = NULL;
s->running = 0;
}
这层 forwarding 本身就是 Session 作为 "Agent Loop" 的第一个雏形——它已经有了"在 Query 之间干一点事"的能力。
10. 迁移路径:三步走
每步可独立 PR、独立 review、独立回滚。
Step 1:内部静态函数族分组(不拆类型、不拆文件)
只做 session.c 内部的函数重排,目标是让"agent 层决策"和"query 层执行"在同一个文件里可视化地分开。
具体动作:
- 把
submit_round/on_provider_*/assist_*/reasoning_*/pending_*/view_build等函数,重命名为query_submit_round/query_on_provider_*/query_assist_*… - 把
history_*/commit_assistant_turn/finish_run/translate_terminal/usage_accumulate留为session_*或不前缀(表示"决策层")。 on_provider_done拆成 3 个小函数:query_handle_error()、query_handle_tool_loop_continuation()、query_handle_terminal(),原函数变成只做三路分派的 3-5 行调度器。- 对外 API、public header、测试全部不动。纯物理重组。
产物:一个 PR,session.c diff 大但语义零变化,npm test 全绿。
Step 2:正式引出 xAgentQuery 类型
- 新建
libx/x/agent/query.h、query_private.h、query.c、query_test.cpp。 - 把 Step 1 里
query_前缀的那批函数 + 相关数据(assist_buf/reasoning_buf/pending/turn)搬家到query.c。 struct xAgentSession_瘦身:删掉那些搬走的字段,加一个xAgentQuery current_q字段。session.c的xAgentSessionInput改写成QueryCreate + QueryRun两步。- 同步落实 §8.1 / §8.2 / §8.3 三条 Agent 预留勾子:
- Session 内部事件分发走 observer list(即使当前只有一条用户 callback 作为 observer)
xAgentSessionInput内部把 input 显式标记为user_origin- 预留
on_session_finalizing回调槽
- 新增
query_test.cpp:脱开 Session 独立测 Query(需要一个轻量 fake session,仅暴露 history append + provider)。原session_test.cpp的 fake_submit 改造成 fake_query,测 Session 层的 forwarding + usage 累加 + cancel。
产物:一个 PR,代码面净增(Query 独立测试),Session 净减。对外 API 仍然零 break。
Step 3(可选):把 Query 做成可独立使用的
在 Step 2 后,Query 其实已经不依赖 Session 的任何独特能力(只依赖 agent、history 引用、provider)。可以开放 xAgentQueryCreateStandalone(agent, view, ...) 给不需要 Session 长期状态的调用方用——例如批处理脚本、单次 QA 工具。
不是必须。只有遇到"某个用户确实想用 query loop 但不想要 session"的真实需求才做。
11. 对测试的影响
11.1 现状盘点
libx/x/agent/session_test.cpp — 覆盖 session-level 的 Input/Cancel/Destroy、
tool loop、max_turns、cb_done 签名
libx/x/agent/provider_openai_test.cpp — 覆盖 provider wire 编解码
libx/x/agent/agent_test.cpp — agent 级 tool 注册 / 生命周期
libx/x/agent/tool_test.cpp — tool 对象本身
libx/x/agent/message_test.cpp — message 结构
11.2 改造量预估
| 文件 | 改造内容 | 工作量 |
|---|---|---|
session_test.cpp | fake_submit 改成 fake_query,验 Session 层 forwarding & usage 累加 | 大(≈ 60% 重写) |
query_test.cpp | 新增:fake_provider + 独立测 tool loop / reasoning / pending / cancel | 从零 |
provider_openai_test.cpp | 零改(Query 和 provider 的契约没变) | 0 |
agent_test.cpp / tool_test.cpp / message_test.cpp | 零改 | 0 |
粗估 2-3 个整天的测试重构。
11.3 Step 1 / Step 2 的风险缓冲
- Step 1 是纯物理重组,session_test 不改而且必须全绿——这是 Step 2 能开始的前提。如果 Step 1 哪个 case 挂了就说明重组把语义动了,回滚。
- Step 2 的 fake_query 要先设计好接口,不要等到 session_test 改到一半才发现 fake 不够用。先用"最小 fake"(只能 done 一次、不支持 tool loop)跑通 Session 层最粗的 smoke test,再往 fake 里加能力。
11.4 Addendum(2026-04-25):fake_query 改造已关闭
事后复盘:§11.2 里预估的 "fake_submit → fake_query ≈ 60% 重写" 没有发生,也不再计划发生。原因是实际落地后 session_test.cpp 的形态已经满足当初要拆出 fake_query 时想达成的所有目标,不需要再做一轮机械替换。
具体来说:
- 当前
session_test.cpp事实上已是 Session + Query 集成测试。fake provider 驱动真实的xAgentQuery执行链(tool loop、cancel、reasoning、usage),Session 层的 forwarding 契约全部用端到端断言覆盖,每个用例的 intent 清晰——并没有"混在一起测不准"的问题。硬塞一个 fake_query 反而会把这条回归链路切断。 - Query 的白盒覆盖由新增
query_test.cpp独立承担(见879d895)。Query 状态机、observer 派发、history 解耦这些点的单元测试责任已经从 Session 测试里析出了,不再需要通过 "fake_query" 反向模拟。 SubmitFailureRollsBackAndReturnsError等用例已经在直接断言s->query == nullptr——说明 session_test 已经感知 Query 的生命周期,早已不是 §11.1 盘点时那个 "只看 provider 黑盒" 的形态。
结论:本条从 §12 开工清单撤下(标记为已关闭,非已完成);后续若真的出现 "fake provider 层难以驱动某个 Session 决策路径" 的用例,再按需引入 fake_query,届时对 session_test.cpp 也只需要增量补测、不是重写。
12. 开工清单
-
Step 1:
session.c内部query_*/session_*分组重命名 +on_provider_done拆三份 -
Step 1:
npm test9/9 全绿验证 - Step 1:PR 提交 + self-review 确认 diff 零语义变化
-
Step 2:新增
query.h/c/private.h,从 Session 搬运字段与函数 -
Step 2:
xAgentSession_瘦身,持有xAgentQuery current_q -
Step 2:落实 §8.1 observer list、§8.2 input origin 标记、§8.3
on_session_finalizing勾子 -
Step 2:新增
query_test.cpp(含 fake_provider) - [~] Step 2:
session_test.cpp改造 fake_submit → fake_querysession_test.cpp当前已等价承担 Session + Query 集成测试,不再需要此改造。 -
Step 2:
npm test全绿 +xagent_test通过 -
Step 2:更新
docs/xagent-module.md(如果有的话)说明新的双层结构 -
Step 3(可选):开放
xAgentQueryCreateStandalone,文档里给一个批处理 use case
Part III · Agent 层(远期登记)
13. 为什么 Agent 层不能并入 Session
有个合理的反问:Session 本来就是一个"对话"的抽象,跨对话的事交给进程/主程序不就行了?——如果只做 Part II 的 Session/Query 拆分,确实不需要 Agent 层。Agent 层的必要性完全来自 human-like-ai 规划的四个维度。
| 维度 | 为什么必须 Agent 层 |
|---|---|
| 分层记忆 L2/L3 | L2 是跨 session 的稳定事实,L3 是长期自我认知。归属权必须在所有 Session 之上,否则每一次 Session 生死都会拖一个 L2/L3 全量 I/O,还容易写冲突。 |
| 情绪延续 | Mood 必须在 Session 边界之外 carry-over,否则每新开一个对话都是冷启动情绪。只有一个常驻的"自我"才能持有 mood state。 |
| 主动唤醒 | 定时器/事件触发时,当下可能根本没有活跃 Session。由 Agent 层决定"要不要起一个新 Session"以及"input 是什么"。Session 层无法自举。 |
| 人格一致性 | 每新开一个 Session,system prompt 要注入一致的人格描述。如果让每个 Session 自行维护人格字符串,无法保证一致(也难以升级、AB test 不同人格版本)。 |
| Sub-agent 并存 | 父 Session 在 tool 里 spawn 子 Session,两者谁来 own?放在父 Session 里就成了"Session 持有 Session",生命周期纠缠;放在 Agent 层就是"Agent 持有 N 个 Session,其中两个有父子关系",干净。 |
如果这四件事都不做,Agent 层就是过度设计。如果这四件事里有任何一件认真做,Agent 层就不可省略。
14. Agent 层开工范围(提纲,未到日不细写)
-
定
xAgentopaque handle + 核心 struct 字段(memory store、mood、scheduler、session list) - 实装 Agent → Session 注入(人格前缀、记忆前缀)
- 实装 Session → Agent 上报(L1 抽取回调、session_finalizing 回调)
-
实装 L2/L3 的持久化后端(选型:sqlite? 文本? 文件布局?——独立起一份
docs/design/xagent_memory_storage.md) - 主动唤醒调度器(先做一个最简单的定时器 MVP)
- Mood state(v1,不在 MVP 内)
-
示例
examples/ai_agent.cpp(像cli/一样的 REPL,但持有 Agent) -
测试:
agent_test.cpp扩展 +session_agent_integration_test.cpp
15. Agent 层开放问题
15.1 Process singleton 还是允许多实例?
倾向:不强制 singleton。一个进程可以创建多个 xAgent(每个绑定不同用户身份),但常见用法是一个进程一个 Agent。这样设计测试友好(可以在同进程里并行测多个 agent),也方便未来做 multi-tenant。
15.2 L2/L3 持久化格式
初期考虑:
- JSON Lines 文件(易调试、易手工修)
- SQLite(查询灵活、但依赖更重)
- 先 JSONL MVP、v1 再迁 SQLite?
不在本文档决定,真正做到那一步时单独起一份 docs/design/xagent_memory_storage.md。
15.3 并发模型
Agent 需要持有多个 Session、需要响应定时器事件——它一定是运行在 xEventLoop 之上的。
- Agent 绑定一个 loop,Session 必须绑定同一个 loop,这是最简单的模型。
- 跨 loop 的 Agent/Session 暂不考虑——有需求时再说,不提前抽象。
15.4 Mood 的表示
v1 之后的事,先不管。但脑子里要有个粗草案:不是连续浮点(难解释难 debug),是离散状态 + 辅助度量——比如 {tone: calm/tired/excited, energy: 0..3} 这类小集合。
15.5 主动唤醒的用户体验
这是产品问题不是架构问题,但本层要提供"用户可关闭/降频"的开关。默认行为应该保守——宁可错过主动时机也不要乱刷屏。
Part IV · 执行时机与风险
16. 总体时间线
now future
│ │
├── human-like-ai MVP 决定启动 ──────────────┐│
│ ↓↓
├── Step 1: session.c 内部分组(纯物理)──┐ │
│ ● 对外 API 零 break │ │
│ ● npm test 9/9 全绿 │ │
│ ↓ │
├── Step 2: 正式引入 xAgentQuery ────────────┐│ │
│ ● 落实 Agent 层预留勾子(§8.1~8.3) ││ │
│ ● fake_query 最小 MVP 先跑通 smoke ││ │
│ ● session_test 60% 重写 ↓│ │
│ │ │
├── Step 3(可选): standalone Query ────┘ │
│ │
├── human-like-ai MVP 开工 ─────────────────┤
│ ● 引入 xAgent handle │
│ ● 记忆 L2/L3 持久化 │
│ ● 主动唤醒调度器 │
│ │
└── v1 / v2:情绪延续、选择性遗忘、主动唤醒升级 ─┘
17. 风险总览
| 项 | 评估 | 缓解 |
|---|---|---|
| 对外 API break | 无。所有改动内部。 | 三步都严守"对外 API 零 break"硬约束 |
| 行为回归 | Step 1 纯物理重组风险最低;Step 2 动了数据字段归属 | Step 1 必须 session_test 9/9 全绿才能进 Step 2;Step 2 先用最小 fake 跑通 smoke 再扩展 |
| 测试工作量 | 2-3 天测试重构 | Step 2 拆成多个小 commit 渐进,不要一次性堆完所有 case |
| Agent 预留勾子设计不到位 | 将来引入 Agent 时要二次改 Session | Step 2 就落实 §8.1~8.3,不留到 Agent 开工再补 |
| 如果 human-like-ai 不做了 | Session/Query 拆分的主要价值消失 | 拆分是 MVP 前置条件,MVP 决定启动时才启动拆分;否则不启动 |
| Query 层不干净 | 被 Agent 特性穿透,三层白分 | §8.4 最硬规矩:Query 所有 callback 参数只带本次查询数据,上下文通过 user_data 透传 |
18. 启动时机硬约束
- Session/Query 拆分的触发条件:human-like-ai MVP 决定启动。否则不启动——不是架构美观必需品。
- Agent 层的触发条件:Session/Query Step 2 完成 且 human-like-ai MVP 进入"引入跨 session 记忆"阶段。
这两条约束必须严守。架构设计可以提前半年写好,但动手写代码要绑定真实产品需求。
18.1 MVP 启动记录
- 2026-04-24:human-like-ai MVP 启动扳机已扣下。拆分 MVP-a(L0+L1 + JSONL + Agent 层雏形)和 MVP-b(L2 + 向量 + SQLite)两小段,详见
human-like-ai.md§6 MVP 执行边界。 - 因此 Session/Query 拆分 Step 1 解锁,可以开工;Step 2 同期进行,为 MVP-a 的 Agent 勾子落地做准备。
- Agent 层的硬前置仍未满足——等 MVP-a 跑稳、确认要接 L2 跨 session 记忆后再启动。
Part V · 附录
19. 三层命名速查
| 层 | 类型名 | 内部前缀 | 文件 | 职责一句话 |
|---|---|---|---|---|
| Agent Loop | xAgent(将来) | agent_* | agent.h/c(将来) | "这个 AI 怎么活" |
| Session Loop | xAgentSession(现有) | session_* / 待梳理 | session.h/c(现有) | "这个任务怎么完成" |
| Query Loop | xAgentQuery(Step 2 后) | query_* | query.h/c(将来) | "这次请求怎么跑完" |
命名一致性原则:Agent 内部静态函数用 agent_*(模块短前缀去掉首字母 x → agent,规则和 xfer → xfer_* 一致)。
20. 与其他文档的关系
- human-like-ai.md:产品方向,回答"做什么"。本文回答"做的东西住在哪"以及"近期怎么动手"。
- 未来:
docs/design/xagent_memory_storage.md:L2/L3 存储选型(Agent 层开工时写)docs/design/xagent_agent_api.md:Agent 公开 API 正式定义(Agent 层开工时写)
作者:小W(与麦伯伯讨论后整理) 日期:2026-04-24 状态:execution plan / 已定稿,按此执行